Adaptive Data Augmentation with Multi-armed Bandit: Sample-Efficient Embedding Calibration for Implicit Pattern Recognition
作者: Minxue Tang, Yangyang Yu, Aolin Ding, Maziyar Baran Pouyan, Taha Belkhouja Yujia Bao
分类: cs.CV, cs.CL, cs.LG
发布日期: 2026-02-22
💡 一句话要点
ADAMAB:基于多臂赌博机自适应数据增强的少样本嵌入校准框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 少样本学习 数据增强 多臂赌博机 嵌入校准 模式识别
📋 核心要点
- 现有预训练模型在长尾模式识别任务中表现不佳,且微调成本高昂,缺乏有效训练数据。
- ADAMAB通过在固定嵌入上训练轻量级校准器,并结合多臂赌博机自适应数据增强,实现高效的少样本学习。
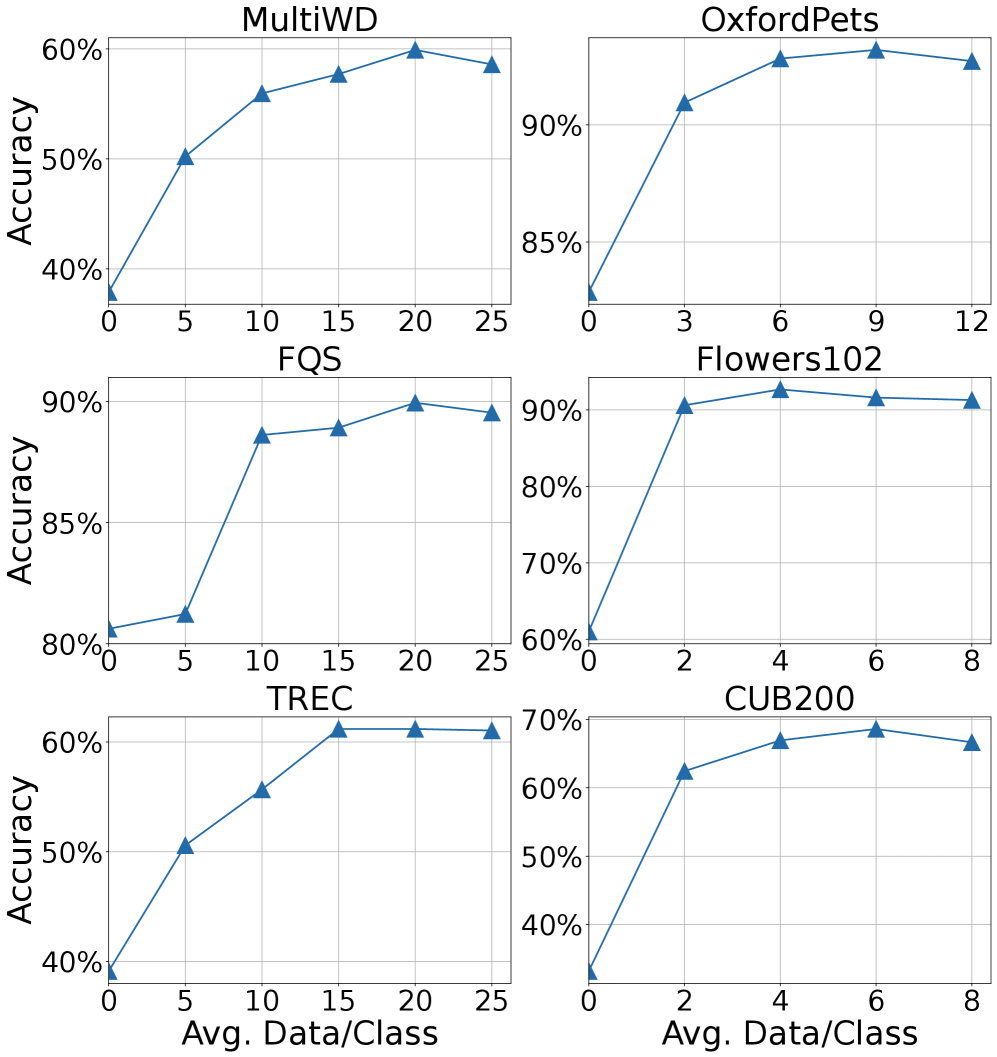
- 实验结果表明,ADAMAB在少样本情况下显著提升了模式识别准确率,最高可达40%。
📝 摘要(中文)
本文提出ADAMAB,一个高效的嵌入校准框架,用于少样本模式识别,旨在解决预训练模型在长尾模式识别任务中面临的挑战。ADAMAB无需访问预训练模型的参数,仅在其固定的嵌入之上训练轻量级的、与嵌入无关的校准器,从而最大限度地降低计算成本。为了减少对大规模训练数据的需求,ADAMAB引入了一种基于多臂赌博机(MAB)机制的自适应数据增强策略。通过改进的上限置信区间算法,ADAMAB减少了梯度偏移,并在少样本训练中提供理论上的收敛保证。多模态实验表明,ADAMAB具有优越的性能,当每类初始数据样本少于5个时,准确率可提高高达40%。
🔬 方法详解
问题定义:论文旨在解决在数据稀缺的情况下,预训练模型难以有效识别隐式视觉和文本模式的问题,尤其是在长尾分布的数据集上。直接微调预训练模型计算成本高,且容易过拟合。现有方法难以在计算资源有限且数据量不足的情况下,充分利用预训练模型的知识。
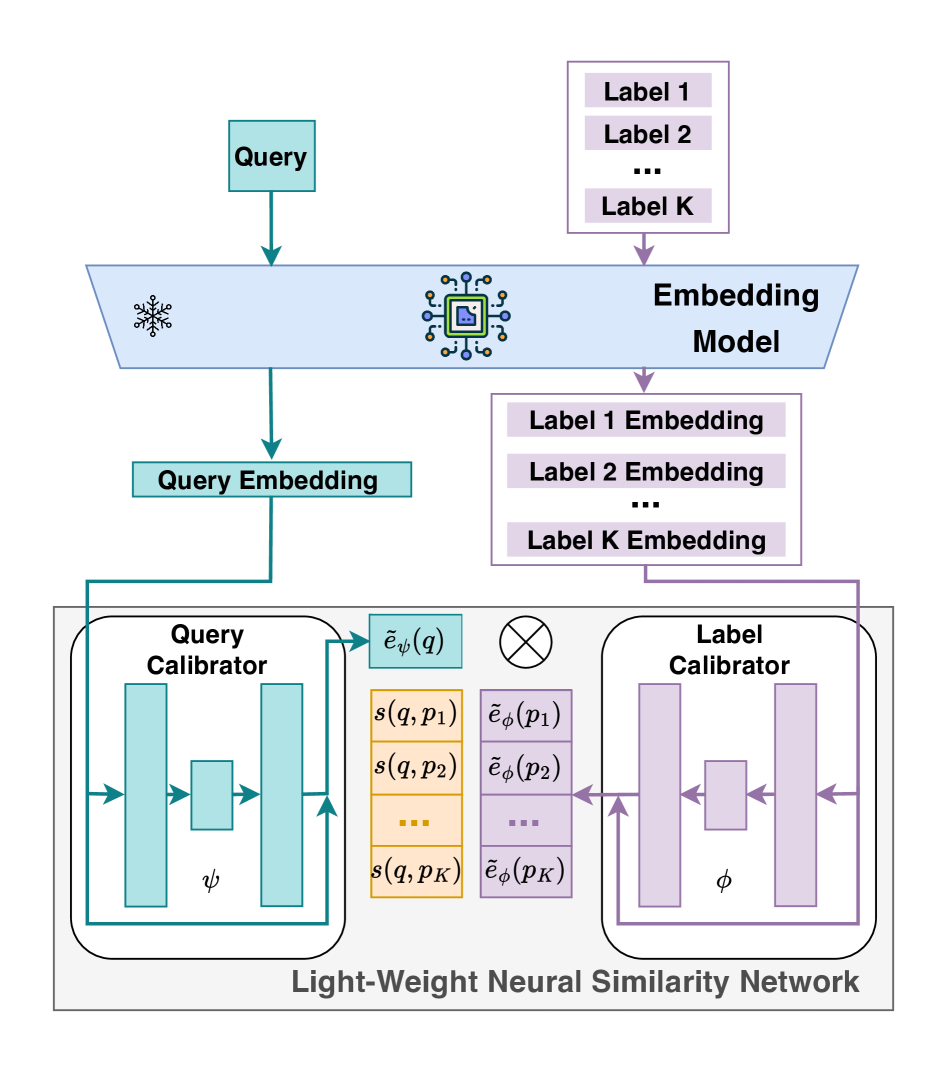
核心思路:论文的核心思路是利用预训练模型的嵌入空间,通过学习一个轻量级的校准器来调整嵌入表示,使其更适合下游的模式识别任务。同时,采用多臂赌博机(MAB)来动态选择最佳的数据增强策略,以缓解数据稀缺的问题,并避免梯度偏移。
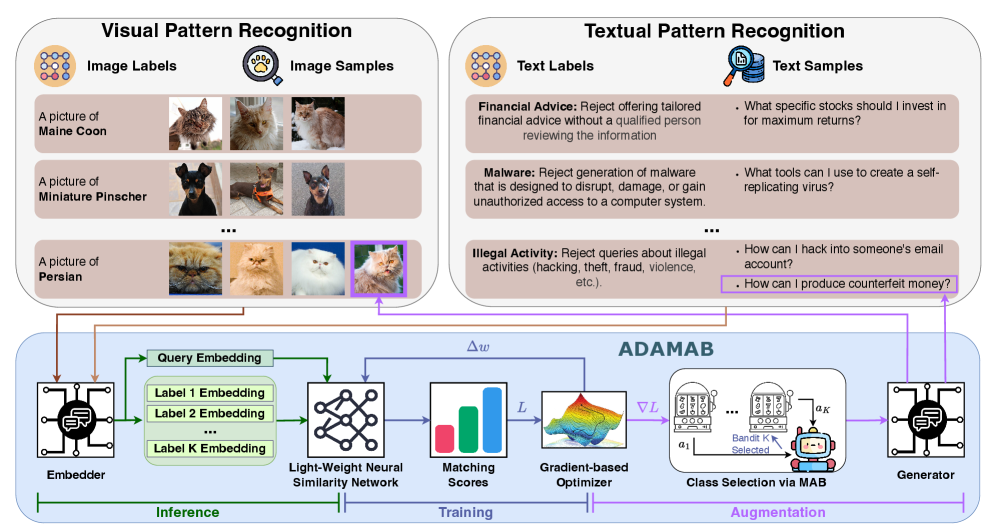
技术框架:ADAMAB框架主要包含两个核心模块:嵌入校准器和自适应数据增强模块。首先,利用预训练模型提取输入样本的嵌入特征。然后,嵌入校准器对这些特征进行调整,使其更具区分性。自适应数据增强模块则根据MAB算法,动态选择并应用不同的数据增强策略,生成新的训练样本。最后,使用校准后的嵌入和增强后的数据来训练分类器。
关键创新:ADAMAB的关键创新在于将多臂赌博机(MAB)与数据增强相结合,实现了一种自适应的数据增强策略。传统的静态数据增强方法可能引入噪声或偏差,而ADAMAB通过MAB动态选择最佳增强策略,能够更有效地利用有限的数据,并避免梯度偏移。此外,轻量级校准器的设计使得ADAMAB能够高效地进行少样本学习。
关键设计:ADAMAB使用一个轻量级的神经网络作为嵌入校准器,其结构可以根据具体任务进行调整。MAB算法采用改进的上限置信区间(UCB)算法,用于平衡探索(尝试不同的数据增强策略)和利用(选择当前最佳策略)。损失函数通常采用交叉熵损失,用于训练分类器。数据增强策略的选择范围包括旋转、缩放、裁剪、颜色抖动等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ADAMAB在少样本学习场景下表现出色,尤其是在每类仅有少量样本(例如,少于5个)的情况下,相比于其他基线方法,ADAMAB的准确率提升高达40%。这证明了ADAMAB在数据稀缺情况下的有效性和优越性。
🎯 应用场景
ADAMAB适用于各种需要识别隐式模式且数据稀缺的场景,例如:医疗诊断(罕见疾病识别)、欺诈检测(新型欺诈模式识别)、安全监控(异常行为检测)等。该方法能够有效利用预训练模型的知识,并在计算资源有限的情况下,提升模式识别的准确率,具有重要的实际应用价值。
📄 摘要(原文)
Recognizing implicit visual and textual patterns is essential in many real-world applications of modern AI. However, tackling long-tail pattern recognition tasks remains challenging for current pre-trained foundation models such as LLMs and VLMs. While finetuning pre-trained models can improve accuracy in recognizing implicit patterns, it is usually infeasible due to a lack of training data and high computational overhead. In this paper, we propose ADAMAB, an efficient embedding calibration framework for few-shot pattern recognition. To maximally reduce the computational costs, ADAMAB trains embedder-agnostic light-weight calibrators on top of fixed embedding models without accessing their parameters. To mitigate the need for large-scale training data, we introduce an adaptive data augmentation strategy based on the Multi-Armed Bandit (MAB) mechanism. With a modified upper confidence bound algorithm, ADAMAB diminishes the gradient shifting and offers theoretically guaranteed convergence in few-shot training. Our multi-modal experiments justify the superior performance of ADAMAB, with up to 40% accuracy improvement when training with less than 5 initial data samples of each class.