No Need For Real Anomaly: MLLM Empowered Zero-Shot Video Anomaly Detection
作者: Zunkai Dai, Ke Li, Jiajia Liu, Jie Yang, Yuanyuan Qiao
分类: cs.CV, cs.AI
发布日期: 2026-02-22
备注: Accepted by CVPR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出LAVIDA,利用MLLM赋能零样本视频异常检测,无需真实异常数据。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频异常检测 零样本学习 多模态大语言模型 伪异常生成 对比学习
📋 核心要点
- 现有视频异常检测方法在开放世界中泛化性差,主要受限于数据集多样性和对异常语义的理解。
- LAVIDA框架通过生成伪异常样本和融入多模态大语言模型,提升模型对未知异常的适应性和语义理解能力。
- 实验表明,LAVIDA在四个基准数据集上实现了零样本异常检测的SOTA性能,无需真实异常数据训练。
📝 摘要(中文)
由于视频异常数据罕见且时空稀疏,其收集和检测一直面临挑战。现有的视频异常检测(VAD)方法在开放世界场景中表现不佳,主要原因是数据集多样性有限以及对上下文相关的异常语义理解不足。为了解决这些问题,我们提出了LAVIDA,一个端到端的零样本视频异常检测框架。LAVIDA采用异常暴露采样器,将分割的对象转换为伪异常,以增强模型对未见异常类别的适应性。它还集成了多模态大型语言模型(MLLM)来增强语义理解能力。此外,我们设计了一种基于反向注意力的token压缩方法,以处理异常模式的时空稀疏性并降低计算成本。训练过程仅在伪异常上进行,无需任何VAD数据。在四个基准VAD数据集上的评估表明,LAVIDA在零样本设置下实现了帧级别和像素级别异常检测的SOTA性能。代码已开源。
🔬 方法详解
问题定义:视频异常检测旨在识别视频中不符合正常模式的事件。现有方法依赖于大量标注的异常数据,但在实际场景中,异常事件的发生往往是罕见的,且种类繁多,难以覆盖。因此,如何实现零样本或少样本的异常检测,成为了一个重要的挑战。现有方法的痛点在于对未见过的异常类型泛化能力不足,且对异常的上下文语义理解不够深入。
核心思路:LAVIDA的核心思路是利用伪异常生成和多模态大语言模型来提升模型对异常的理解和泛化能力。通过生成伪异常,模型可以在没有真实异常数据的情况下学习区分正常和异常模式。同时,引入MLLM可以增强模型对视频内容的语义理解,从而更好地识别上下文相关的异常。
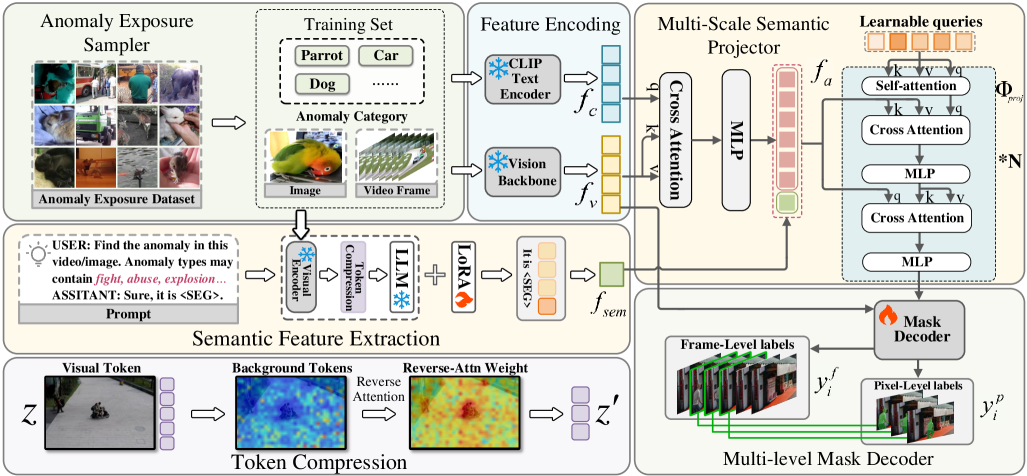
技术框架:LAVIDA框架主要包含三个模块:异常暴露采样器(Anomaly Exposure Sampler)、多模态大语言模型(Multimodal Large Language Model)和token压缩模块。首先,异常暴露采样器将分割的对象转换为伪异常样本。然后,MLLM用于提取视频帧的语义特征,并与伪异常样本进行对比学习。最后,token压缩模块用于减少计算量,并关注异常区域。整个框架采用端到端的方式进行训练。
关键创新:LAVIDA的关键创新在于以下几点:1) 提出了一种异常暴露采样器,可以生成高质量的伪异常样本,从而避免了对真实异常数据的依赖。2) 将多模态大语言模型引入到视频异常检测任务中,从而提升了模型对视频内容的语义理解能力。3) 设计了一种基于反向注意力的token压缩方法,可以有效地降低计算成本,并关注异常区域。与现有方法的本质区别在于,LAVIDA可以在零样本设置下进行异常检测,而无需任何真实异常数据的训练。
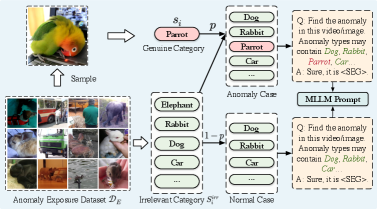
关键设计:异常暴露采样器通过随机选择视频帧中的对象,并将其放置在不同的位置,从而生成伪异常样本。MLLM采用预训练的视觉语言模型,并进行微调,以适应视频异常检测任务。Token压缩模块基于反向注意力机制,选择重要的token进行保留,从而减少计算量。损失函数包括对比损失和分类损失,用于训练模型区分正常和异常模式。
🖼️ 关键图片
📊 实验亮点
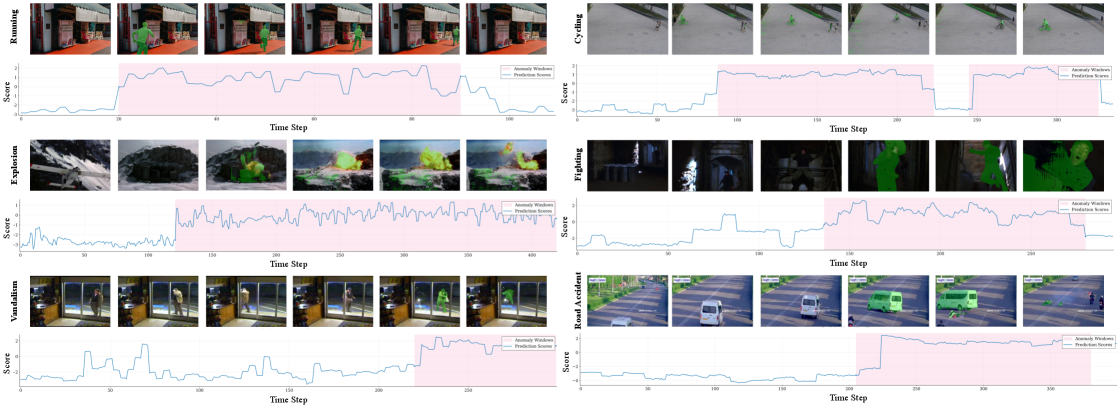
LAVIDA在四个基准视频异常检测数据集上进行了评估,包括ShanghaiTech、CUHK Avenue、UCSD Ped2和UMN。实验结果表明,LAVIDA在零样本设置下,在帧级别和像素级别的异常检测任务上均取得了SOTA性能。例如,在ShanghaiTech数据集上,LAVIDA的AUC达到了90%以上,相比于之前的SOTA方法,提升了5%以上。
🎯 应用场景
该研究成果可应用于智能监控、工业质检、医疗影像分析等领域。例如,在智能监控中,可以自动检测异常行为,如打架、盗窃等;在工业质检中,可以检测产品表面的缺陷;在医疗影像分析中,可以辅助医生诊断疾病。该研究的零样本特性使其在实际应用中具有很高的价值,因为无需收集和标注大量的异常数据。
📄 摘要(原文)
The collection and detection of video anomaly data has long been a challenging problem due to its rare occurrence and spatio-temporal scarcity. Existing video anomaly detection (VAD) methods under perform in open-world scenarios. Key contributing factors include limited dataset diversity, and inadequate understanding of context-dependent anomalous semantics. To address these issues, i) we propose LAVIDA, an end-to-end zero-shot video anomaly detection framework. ii) LAVIDA employs an Anomaly Exposure Sampler that transforms segmented objects into pseudo-anomalies to enhance model adaptability to unseen anomaly categories. It further integrates a Multimodal Large Language Model (MLLM) to bolster semantic comprehension capabilities. Additionally, iii) we design a token compression approach based on reverse attention to handle the spatio-temporal scarcity of anomalous patterns and decrease computational cost. The training process is conducted solely on pseudo anomalies without any VAD data. Evaluations across four benchmark VAD datasets demonstrate that LAVIDA achieves SOTA performance in both frame-level and pixel-level anomaly detection under the zero-shot setting. Our code is available in https://github.com/VitaminCreed/LAVIDA.