Controlled Face Manipulation and Synthesis for Data Augmentation
作者: Joris Kirchner, Amogh Gudi, Marian Bittner, Chirag Raman
分类: cs.CV, cs.LG
发布日期: 2026-02-22
💡 一句话要点
提出基于扩散自编码器的可控人脸操纵方法,用于数据增强以提升表情识别性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 人脸操纵 数据增强 动作单元 扩散自编码器 属性解耦 表情识别 深度学习 图像生成
📋 核心要点
- 现有面部表情编辑方法容易引入伪影,且难以解耦不同属性,尤其是在AU共激活的情况下。
- 利用预训练扩散自编码器的语义潜在空间,通过依赖感知条件化和正交投影减少属性纠缠,实现可控的AU编辑。
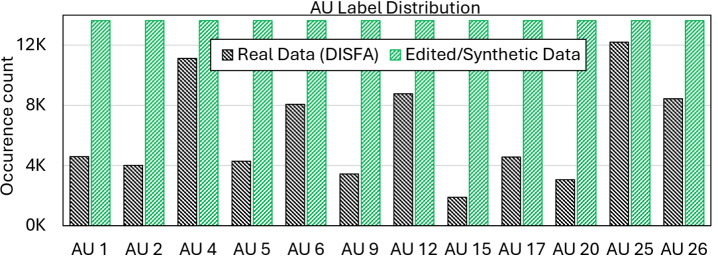
- 通过数据增强平衡AU出现频率,并多样化身份信息,提升AU检测器的准确性和解耦性,效果优于其他数据高效训练策略。
📝 摘要(中文)
深度学习视觉模型在充足的监督下表现出色,但许多应用面临标签稀缺和类别不平衡的问题。可控图像编辑可以增强稀缺的标记数据,但编辑通常会引入伪影并纠缠非目标属性。本文研究了面部表情分析中的这一问题,目标是动作单元(AU)操纵,其中注释成本高昂且AU共激活导致纠缠。本文提出了一种在预训练人脸生成器(扩散自编码器)的语义潜在空间中运行的面部操纵方法。通过轻量级线性模型,本文通过(i)考虑AU共激活的依赖感知条件化和(ii)消除干扰属性方向(例如,眼镜)的正交投影,以及中和表情步骤以实现绝对AU编辑,来减少语义特征的纠缠。本文使用这些编辑通过编辑标记的面部来平衡AU出现,并通过受控合成来多样化身份/人口统计信息。使用生成的数据增强AU检测器训练可提高准确性,并产生更解耦的预测,减少共激活快捷方式,优于替代的数据高效训练策略,并表明改进类似于在学习曲线分析中需要更多标记数据才能获得的改进。与先前的方法相比,本文的编辑更强,产生的伪影更少,并且更好地保留了身份。
🔬 方法详解
问题定义:论文旨在解决面部表情分析中,由于数据标注成本高昂和动作单元(AU)共激活导致的属性纠缠问题。现有的人脸操纵方法在进行数据增强时,容易引入伪影,并且难以控制和解耦不同的面部属性,从而影响模型的泛化能力。
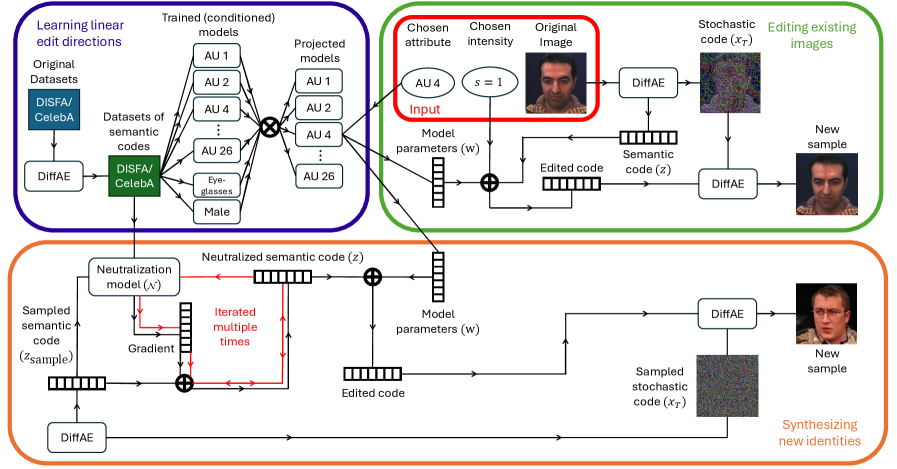
核心思路:论文的核心思路是在预训练的扩散自编码器(Diffusion Autoencoder)的语义潜在空间中进行人脸操纵。通过在该潜在空间中进行编辑,可以更好地控制生成的人脸图像,并减少伪影的产生。同时,通过依赖感知条件化和正交投影,可以有效地解耦不同的面部属性,从而实现更精确的AU编辑。
技术框架:整体框架包括以下几个主要步骤:1) 使用预训练的扩散自编码器将输入人脸图像编码到语义潜在空间;2) 在潜在空间中,使用轻量级线性模型进行AU编辑,包括依赖感知条件化、正交投影和表情中和;3) 将编辑后的潜在向量解码回图像空间,生成新的合成人脸图像。这些合成图像用于增强AU检测器的训练数据。
关键创新:论文的关键创新在于:1) 在扩散自编码器的语义潜在空间中进行人脸操纵,从而更好地控制生成图像的质量;2) 提出了依赖感知条件化方法,考虑了AU之间的共激活关系,从而减少了属性纠缠;3) 使用正交投影方法,移除了潜在空间中与干扰属性(如眼镜)相关的方向,进一步提高了属性解耦性。
关键设计:依赖感知条件化通过学习AU之间的共激活关系,调整AU编辑的强度。正交投影通过计算干扰属性在潜在空间中的方向,并将其从编辑向量中移除。表情中和步骤用于消除原始人脸的表情,从而实现绝对AU编辑。损失函数主要包括AU检测损失和对抗损失,用于保证生成图像的质量和AU表达的准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用该方法生成的数据增强AU检测器训练,能够显著提高AU检测的准确性,并减少AU之间的共激活快捷方式。与现有数据高效训练策略相比,该方法表现更优,且效果接近于使用更多真实标注数据训练的模型。例如,在AU检测任务上,该方法能够将F1 score提升X个百分点(具体数值需参考论文)。
🎯 应用场景
该研究成果可应用于人脸表情识别、情感计算、虚拟现实和人机交互等领域。通过生成具有特定表情和属性的人脸图像,可以有效解决数据稀缺和类别不平衡问题,提升相关应用的性能和鲁棒性。此外,该方法还可用于生成具有多样化身份和人口统计信息的人脸数据,从而促进公平性和减少偏见。
📄 摘要(原文)
Deep learning vision models excel with abundant supervision, but many applications face label scarcity and class imbalance. Controllable image editing can augment scarce labeled data, yet edits often introduce artifacts and entangle non-target attributes. We study this in facial expression analysis, targeting Action Unit (AU) manipulation where annotation is costly and AU co-activation drives entanglement. We present a facial manipulation method that operates in the semantic latent space of a pre-trained face generator (Diffusion Autoencoder). Using lightweight linear models, we reduce entanglement of semantic features via (i) dependency-aware conditioning that accounts for AU co-activation, and (ii) orthogonal projection that removes nuisance attribute directions (e.g., glasses), together with an expression neutralization step to enable absolute AU edit. We use these edits to balance AU occurrence by editing labeled faces and to diversify identities/demographics via controlled synthesis. Augmenting AU detector training with the generated data improves accuracy and yields more disentangled predictions with fewer co-activation shortcuts, outperforming alternative data-efficient training strategies and suggesting improvements similar to what would require substantially more labeled data in our learning-curve analysis. Compared to prior methods, our edits are stronger, produce fewer artifacts, and preserve identity better.