GS-CLIP: Zero-shot 3D Anomaly Detection by Geometry-Aware Prompt and Synergistic View Representation Learning
作者: Zehao Deng, An Liu, Yan Wang
分类: cs.CV
发布日期: 2026-02-22
🔗 代码/项目: GITHUB
💡 一句话要点
GS-CLIP:基于几何感知提示和协同视图表示学习的零样本3D异常检测
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 零样本学习 3D异常检测 几何感知 协同视图表示学习 CLIP 缺陷检测 工业质检
📋 核心要点
- 现有零样本3D异常检测方法依赖2D投影,损失几何信息,且单一视角限制了异常检测能力。
- GS-CLIP通过几何感知提示和协同视图表示学习,增强模型对3D几何信息的理解和利用。
- 在四个大型数据集上,GS-CLIP取得了优越的异常检测性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为GS-CLIP的框架,用于解决零样本3D异常检测问题。该任务旨在无需目标训练数据的情况下检测目标数据集中的异常,这在样本稀缺和数据隐私受限的场景中尤为重要。现有方法通过将3D点云投影到2D表示来适配CLIP,但存在几何细节丢失和依赖单一2D模态导致视觉理解不完整的问题,限制了其检测多样化异常类型的能力。GS-CLIP通过几何感知提示和协同视图表示学习,使模型能够通过两阶段学习过程识别几何异常。第一阶段,动态生成嵌入3D几何先验的文本提示,包含全局形状上下文和由几何缺陷提炼模块(GDDM)提取的局部缺陷信息。第二阶段,引入协同视图表示学习架构,并行处理渲染图像和深度图像,并通过协同细化模块(SRM)融合两者的特征,利用其互补优势。在四个大型公共数据集上的实验结果表明,GS-CLIP在检测方面取得了优越的性能。
🔬 方法详解
问题定义:零样本3D异常检测旨在无需目标数据集训练样本的情况下,识别3D数据中的异常。现有方法主要依赖于将3D点云投影为2D图像,然后利用预训练的CLIP模型进行异常检测。然而,这种投影过程不可避免地会丢失3D几何信息,并且单一视角的2D图像无法提供完整的3D场景理解,导致模型难以检测复杂的几何异常。
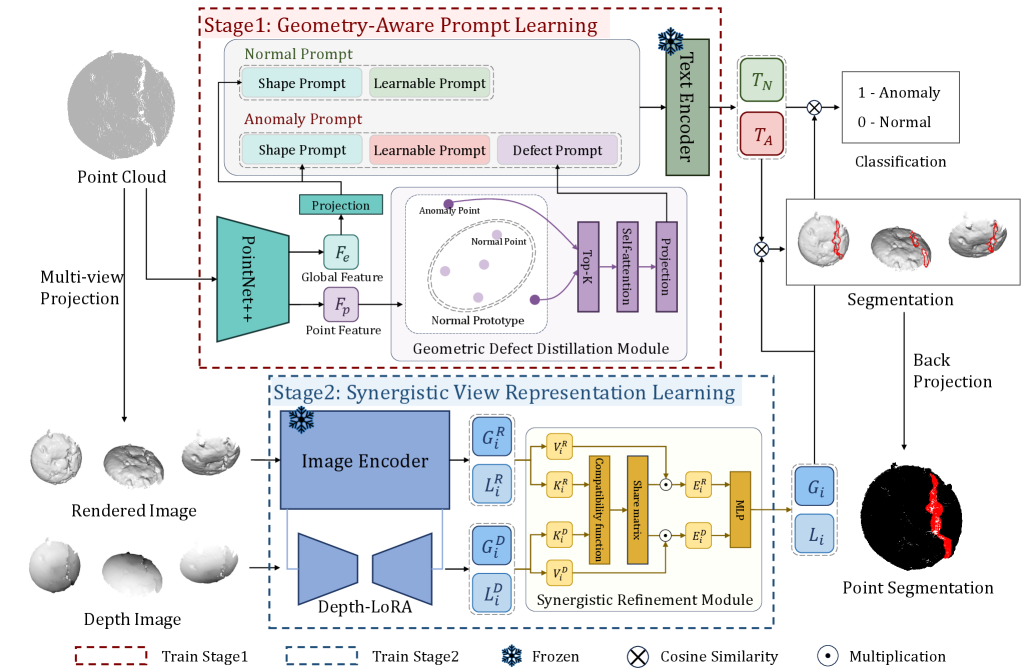
核心思路:GS-CLIP的核心思路是通过引入几何先验知识和多视角信息来增强模型的3D理解能力。具体来说,首先通过几何缺陷提炼模块(GDDM)提取3D数据的几何特征,并将其融入到文本提示中,引导CLIP模型关注几何异常。然后,利用渲染图像和深度图像两种视角的信息,通过协同视图表示学习来弥补单一视角的不足。
技术框架:GS-CLIP框架主要包含两个阶段:几何感知提示生成和协同视图表示学习。在第一阶段,GDDM从3D数据中提取全局形状上下文和局部缺陷信息,并将其嵌入到文本提示中。在第二阶段,渲染图像和深度图像被并行输入到两个独立的编码器中,提取视觉特征。然后,协同细化模块(SRM)融合两种视角的特征,得到最终的表示。最后,利用CLIP模型计算图像和文本之间的相似度,从而判断是否存在异常。
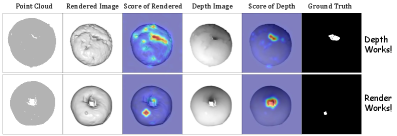
关键创新:GS-CLIP的关键创新在于以下两点:一是提出了几何缺陷提炼模块(GDDM),能够有效地提取3D数据的几何特征,并将其融入到文本提示中,从而引导CLIP模型关注几何异常。二是提出了协同视图表示学习架构,通过融合渲染图像和深度图像两种视角的信息,弥补了单一视角的不足,提高了异常检测的准确率。
关键设计:GDDM的具体实现细节未知,论文中可能没有详细描述。协同细化模块(SRM)的设计细节也未知,可能采用了注意力机制或其他特征融合方法。损失函数方面,可能使用了CLIP模型的对比学习损失,以及其他辅助损失来提高模型的性能。具体的参数设置和网络结构细节需要在论文原文中查找。
🖼️ 关键图片

📊 实验亮点
GS-CLIP在四个大型公共数据集上取得了显著的性能提升。具体数据未知,但摘要中提到GS-CLIP在检测方面取得了优越的性能,表明其优于现有的零样本3D异常检测方法。与现有方法相比,GS-CLIP能够更准确地检测各种类型的异常,尤其是在几何异常方面表现突出。
🎯 应用场景
GS-CLIP可应用于工业质检、医疗影像分析、自动驾驶等领域。例如,在工业质检中,可以检测产品表面的缺陷;在医疗影像分析中,可以辅助医生诊断疾病;在自动驾驶中,可以识别道路上的异常物体。该研究有助于提高相关领域的自动化水平和安全性。
📄 摘要(原文)
Zero-shot 3D Anomaly Detection is an emerging task that aims to detect anomalies in a target dataset without any target training data, which is particularly important in scenarios constrained by sample scarcity and data privacy concerns. While current methods adapt CLIP by projecting 3D point clouds into 2D representations, they face challenges. The projection inherently loses some geometric details, and the reliance on a single 2D modality provides an incomplete visual understanding, limiting their ability to detect diverse anomaly types. To address these limitations, we propose the Geometry-Aware Prompt and Synergistic View Representation Learning (GS-CLIP) framework, which enables the model to identify geometric anomalies through a two-stage learning process. In stage 1, we dynamically generate text prompts embedded with 3D geometric priors. These prompts contain global shape context and local defect information distilled by our Geometric Defect Distillation Module (GDDM). In stage 2, we introduce Synergistic View Representation Learning architecture that processes rendered and depth images in parallel. A Synergistic Refinement Module (SRM) subsequently fuses the features of both streams, capitalizing on their complementary strengths. Comprehensive experimental results on four large-scale public datasets show that GS-CLIP achieves superior performance in detection. Code can be available at https://github.com/zhushengxinyue/GS-CLIP.