UniE2F: A Unified Diffusion Framework for Event-to-Frame Reconstruction with Video Foundation Models
作者: Gang Xu, Zhiyu Zhu, Junhui Hou
分类: cs.CV
发布日期: 2026-02-22
🔗 代码/项目: GITHUB
💡 一句话要点
UniE2F:利用视频基础模型的事件到帧重建统一扩散框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事件相机 视频重建 扩散模型 视频生成 帧间残差
📋 核心要点
- 事件相机数据缺乏空间信息和静态纹理细节,限制了其应用。
- 利用预训练视频扩散模型的生成能力,并引入事件帧间残差引导,提升重建精度。
- 该方法可扩展到视频帧插值和预测,并在真实和合成数据集上取得了显著优于现有方法的效果。
📝 摘要(中文)
事件相机擅长高速、低功耗和高动态范围的场景感知。然而,由于它们本质上只记录相对强度变化而非绝对强度,因此产生的数据流会遭受显著的空间信息和静态纹理细节损失。本文通过利用预训练视频扩散模型的生成先验,从稀疏事件数据中重建高保真视频帧来解决这一限制。具体而言,我们首先通过直接应用事件数据作为条件来合成视频,从而建立基线模型。然后,基于事件流和视频帧之间的物理相关性,我们进一步引入基于事件的帧间残差引导,以提高视频帧重建的准确性。此外,我们通过调节反向扩散采样过程,将我们的方法以零样本方式扩展到视频帧插值和预测,从而创建一个统一的事件到帧重建框架。在真实和合成数据集上的实验结果表明,我们的方法在定量和定性方面都显著优于以前的方法。我们还请审阅者参考补充材料中包含的视频演示以获取视频结果。代码将在https://github.com/CS-GangXu/UniE2F上公开发布。
🔬 方法详解
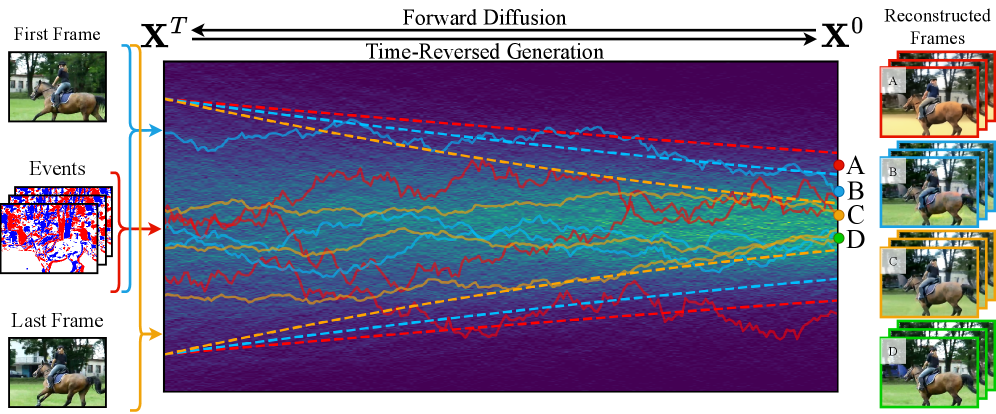
问题定义:事件相机仅记录相对亮度变化,导致空间信息和静态纹理细节的严重损失。现有方法难以从稀疏事件数据中重建高质量的视频帧,尤其是在复杂场景和快速运动的情况下。
核心思路:利用预训练视频扩散模型强大的生成先验知识,将事件数据作为条件引导视频帧的生成过程。通过结合事件流和视频帧之间的物理相关性,引入事件帧间残差引导,进一步提升重建的准确性和细节。
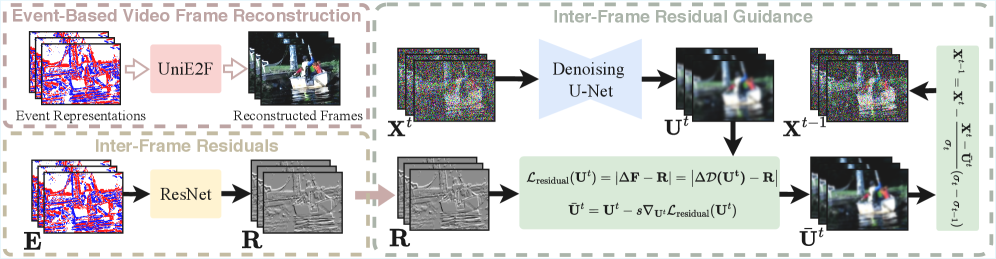
技术框架:UniE2F框架包含以下主要模块:1) 事件数据预处理,将事件数据转换为适合扩散模型输入的格式。2) 基于预训练视频扩散模型的视频生成模块,以事件数据为条件生成视频帧。3) 事件帧间残差引导模块,利用事件流计算帧间残差,并将其作为额外的引导信息融入扩散过程。4) 反向扩散采样过程调节模块,用于实现视频帧插值和预测。
关键创新:该方法的核心创新在于将预训练视频扩散模型与事件数据相结合,利用扩散模型的生成能力弥补事件数据空间信息的不足。同时,引入事件帧间残差引导,充分利用事件流和视频帧之间的物理相关性,提升重建质量。此外,该框架具有统一性,能够处理事件到帧重建、视频帧插值和预测等多种任务。
关键设计:事件帧间残差引导模块的设计是关键。具体而言,该模块利用事件流计算相邻帧之间的残差,并将该残差作为额外的条件信息输入到扩散模型的反向扩散过程中。损失函数方面,采用了重建损失和感知损失相结合的方式,以保证重建帧的质量和视觉效果。网络结构方面,采用了标准的U-Net结构作为扩散模型的主干网络,并针对事件数据的特点进行了一些调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,UniE2F在真实和合成数据集上均显著优于现有方法。在事件到帧重建任务中,UniE2F在PSNR和SSIM等指标上取得了显著提升。此外,UniE2F还成功地应用于视频帧插值和预测任务,展示了其泛化能力。补充材料中的视频演示也直观地展示了UniE2F的优越性能。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、运动捕捉、高速视频重建等领域。通过从事件数据中重建高质量视频帧,可以提升感知系统的性能,使其能够在高速、低光照和高动态范围等复杂环境下更好地工作。未来,该技术有望在智能交通、安防监控、工业自动化等领域发挥重要作用。
📄 摘要(原文)
Event cameras excel at high-speed, low-power, and high-dynamic-range scene perception. However, as they fundamentally record only relative intensity changes rather than absolute intensity, the resulting data streams suffer from a significant loss of spatial information and static texture details. In this paper, we address this limitation by leveraging the generative prior of a pre-trained video diffusion model to reconstruct high-fidelity video frames from sparse event data. Specifically, we first establish a baseline model by directly applying event data as a condition to synthesize videos. Then, based on the physical correlation between the event stream and video frames, we further introduce the event-based inter-frame residual guidance to enhance the accuracy of video frame reconstruction. Furthermore, we extend our method to video frame interpolation and prediction in a zero-shot manner by modulating the reverse diffusion sampling process, thereby creating a unified event-to-frame reconstruction framework. Experimental results on real-world and synthetic datasets demonstrate that our method significantly outperforms previous approaches both quantitatively and qualitatively. We also refer the reviewers to the video demo contained in the supplementary material for video results. The code will be publicly available at https://github.com/CS-GangXu/UniE2F.