FUSAR-GPT : A Spatiotemporal Feature-Embedded and Two-Stage Decoupled Visual Language Model for SAR Imagery
作者: Xiaokun Zhang, Yi Yang, Ziqi Ye, Baiyun, Xiaorong Guo, Qingchen Fang, Ruyi Zhang, Xinpeng Zhou, Haipeng Wang
分类: cs.CV, cs.AI
发布日期: 2026-02-22
💡 一句话要点
FUSAR-GPT:面向SAR影像,时空特征嵌入与解耦的两阶段视觉语言模型
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: SAR图像解译 视觉语言模型 时空特征嵌入 两阶段解耦 遥感应用
📋 核心要点
- 现有VLM直接应用于SAR图像解译时,由于SAR成像的复杂性和数据稀缺性,性能受到严重限制。
- FUSAR-GPT通过嵌入地理空间知识和时序特征,并采用两阶段解耦训练,提升了SAR图像的理解能力。
- 实验结果表明,FUSAR-GPT在多个遥感视觉语言任务上显著优于现有模型,性能提升超过12%。
📝 摘要(中文)
针对合成孔径雷达(SAR)影像智能解译在遥感应用中的重要性,以及现有视觉语言模型(VLM)在SAR领域因成像机制复杂、对散射特征敏感和高质量文本语料匮乏而受限的问题,本文构建了首个SAR图像-文本-AlphaEarth特征三元组数据集,并开发了专门用于SAR的VLM——FUSAR-GPT。FUSAR-GPT创新性地引入了地理空间基线模型作为“世界知识”先验,并通过“时空锚点”将多源遥感时间特征嵌入到模型的视觉骨干中,从而动态补偿SAR图像中目标的稀疏表示。此外,设计了两阶段SFT策略来解耦大型模型的知识注入和任务执行。时空特征嵌入和两阶段解耦范式使FUSAR-GPT在多个典型的遥感视觉语言基准测试中取得了最先进的性能,显著优于主流基线模型12%以上。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在RGB图像上表现出色,但直接应用于SAR图像时,由于SAR成像机制的复杂性(如散射特性)以及缺乏高质量的SAR图像-文本数据集,性能显著下降。现有方法难以有效利用SAR图像中的空间和时间信息,并且知识注入和任务执行耦合,导致模型泛化能力不足。
核心思路:FUSAR-GPT的核心思路是通过引入地理空间知识作为先验,并嵌入多源遥感时序特征,来增强模型对SAR图像的理解。同时,采用两阶段的微调策略,将知识注入和任务执行解耦,从而提高模型的泛化能力和性能。
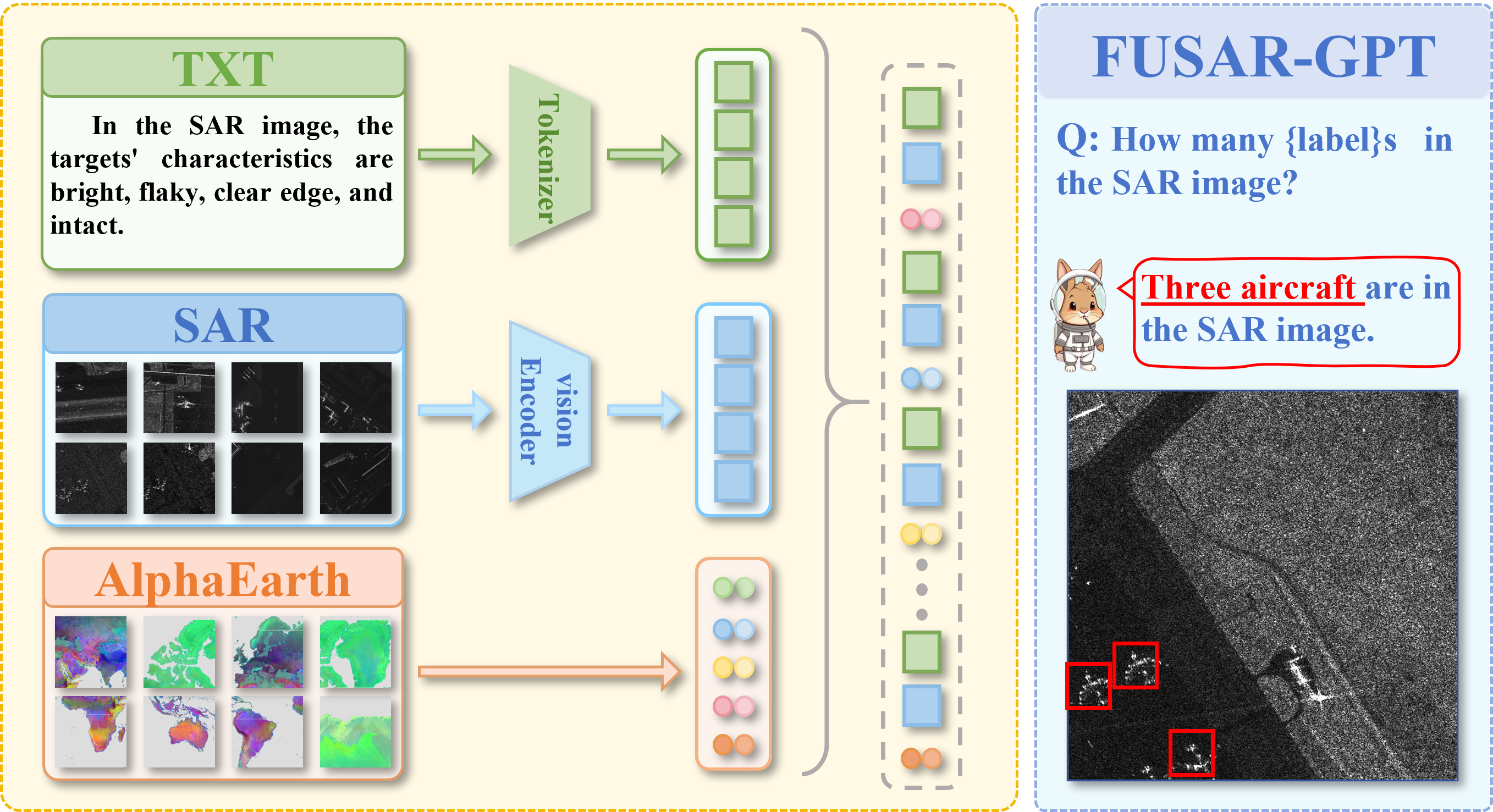
技术框架:FUSAR-GPT的整体框架包括以下几个主要模块:1) SAR图像编码器:用于提取SAR图像的视觉特征。2) 地理空间基线模型:提供地理空间知识先验。3) 时空特征嵌入模块:将多源遥感时序特征嵌入到视觉骨干网络中。4) 文本编码器:用于编码文本描述。5) 两阶段微调策略:包括知识注入阶段和任务执行阶段。
关键创新:FUSAR-GPT的关键创新在于:1) 提出了SAR图像-文本-AlphaEarth特征三元组数据集,为SAR领域的VLM研究提供了高质量的数据支持。2) 创新性地引入了地理空间基线模型作为“世界知识”先验,增强了模型对SAR图像的理解。3) 设计了时空特征嵌入模块,动态补偿SAR图像中目标的稀疏表示。4) 提出了两阶段SFT策略,解耦了知识注入和任务执行,提高了模型的泛化能力。
关键设计:时空特征嵌入模块通过“时空锚点”将多源遥感时间特征嵌入到模型的视觉骨干中,具体实现方式未知。两阶段SFT策略的具体实现细节未知,包括损失函数、网络结构等。地理空间基线模型的选择和集成方式也未知。
🖼️ 关键图片
📊 实验亮点
FUSAR-GPT在多个遥感视觉语言基准测试中取得了state-of-the-art的性能,显著优于主流基线模型超过12%。这一结果表明,该模型在SAR图像理解方面具有显著的优势,验证了时空特征嵌入和两阶段解耦策略的有效性。
🎯 应用场景
FUSAR-GPT在全天候、全天时的遥感应用中具有广泛的应用前景,例如灾害监测、城市规划、农业监测、环境评估和军事侦察等。该模型能够提升SAR图像的智能解译能力,为相关领域的决策提供更准确、及时的信息支持,具有重要的实际价值和深远的影响。
📄 摘要(原文)
Research on the intelligent interpretation of all-weather, all-time Synthetic Aperture Radar (SAR) is crucial for advancing remote sensing applications. In recent years, although Visual Language Models (VLMs) have demonstrated strong open-world understanding capabilities on RGB images, their performance is severely limited when directly applied to the SAR field due to the complexity of the imaging mechanism, sensitivity to scattering features, and the scarcity of high-quality text corpora. To systematically address this issue, we constructed the inaugural SAR Image-Text-AlphaEarth feature triplet dataset and developed FUSAR-GPT, a VLM specifically for SAR. FUSAR-GPT innovatively introduces a geospatial baseline model as a 'world knowledge' prior and embeds multi-source remote-sensing temporal features into the model's visual backbone via 'spatiotemporal anchors', enabling dynamic compensation for the sparse representation of targets in SAR images. Furthermore, we designed a two-stage SFT strategy to decouple the knowledge injection and task execution of large models. The spatiotemporal feature embedding and the two-stage decoupling paradigm enable FUSAR-GPT to achieve state-of-the-art performance across several typical remote sensing visual-language benchmark tests, significantly outperforming mainstream baseline models by over 12%.