VLM-Guided Group Preference Alignment for Diffusion-based Human Mesh Recovery
作者: Wenhao Shen, Hao Wang, Wanqi Yin, Fayao Liu, Xulei Yang, Chao Liang, Zhongang Cai, Guosheng Lin
分类: cs.CV
发布日期: 2026-02-22
备注: Accepted to CVPR 2026
💡 一句话要点
提出VLM引导的群体偏好对齐框架,提升扩散模型人体网格重建的真实性和一致性
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体网格重建 扩散模型 视觉语言模型 偏好学习 三维人体姿态估计
📋 核心要点
- 现有基于扩散模型的人体网格重建方法在复杂场景下精度不足,易产生物理上不可信或与图像不符的结果。
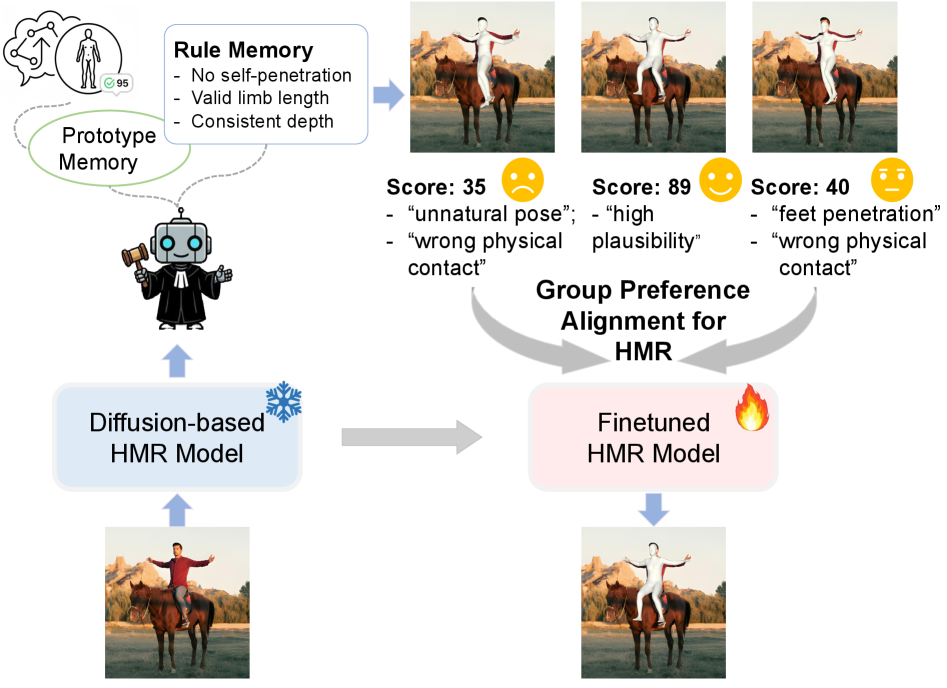
- 提出双记忆增强的HMR评论代理,通过自反思机制生成上下文感知的质量分数,构建群体偏好数据集。
- 构建群体偏好对齐框架,微调扩散模型,使其生成更符合物理规律和图像一致性的人体网格。
📝 摘要(中文)
单张RGB图像的人体网格重建(HMR)具有内在的模糊性,因为多个3D姿势可能对应于相同的2D观测。最近基于扩散的方法通过生成各种假设来解决这个问题,但通常会牺牲准确性。它们产生的预测要么在物理上不可信,要么偏离输入图像,尤其是在遮挡或杂乱的野外场景中。为了解决这个问题,我们引入了一个具有自我反思的双记忆增强HMR评论代理,为预测的网格生成上下文感知的质量分数。这些分数提炼了关于3D人体运动结构、物理可行性和与输入图像对齐的细粒度线索。我们使用这些分数来构建一个群体HMR偏好数据集。利用这个数据集,我们提出了一种群体偏好对齐框架,用于微调基于扩散的HMR模型。这个过程将丰富的偏好信号注入到模型中,引导它生成更符合物理规律和图像一致性的人体网格。大量的实验表明,我们的方法与最先进的方法相比,取得了优越的性能。
🔬 方法详解
问题定义:论文旨在解决单张RGB图像人体网格重建(HMR)的模糊性问题,尤其是在遮挡或复杂场景下,现有基于扩散模型的方法生成的3D人体网格可能在物理上不合理,或者与输入的2D图像不一致。现有方法的痛点在于缺乏对生成结果的有效评估和引导,导致生成质量不稳定。
核心思路:论文的核心思路是利用视觉语言模型(VLM)的强大理解能力,构建一个能够评估和指导HMR模型生成过程的“评论代理”。该代理通过学习人类对HMR结果的偏好,从而引导扩散模型生成更符合物理规律和图像一致性的人体网格。这种方法的核心在于将人类的偏好知识注入到模型中,从而克服了传统方法在复杂场景下的局限性。
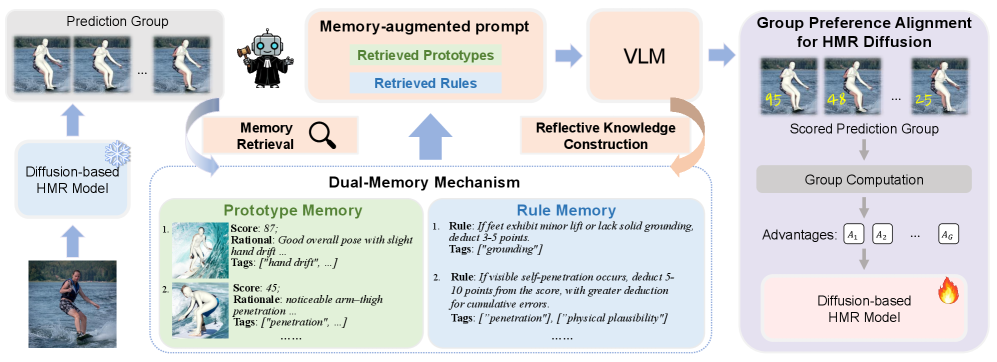
技术框架:整体框架包含以下几个主要模块:1) 双记忆增强的HMR评论代理:该代理负责评估HMR模型生成的网格质量,并给出相应的分数。它利用双记忆机制来存储和检索与输入图像相关的上下文信息,从而更准确地评估网格的物理可行性和图像一致性。2) 群体HMR偏好数据集构建:利用评论代理生成的分数,构建一个包含多个HMR结果及其对应质量分数的偏好数据集。3) 群体偏好对齐框架:利用偏好数据集,通过微调扩散模型,使其学习人类对HMR结果的偏好,从而生成更符合人类期望的网格。
关键创新:最重要的技术创新点在于引入了VLM来指导HMR模型的生成过程。传统的HMR方法主要依赖于图像特征或先验知识,而忽略了人类对3D人体姿态的理解和偏好。通过构建评论代理,论文将人类的偏好知识融入到模型中,从而显著提升了HMR的质量。与现有方法的本质区别在于,论文的方法不仅仅是生成多个假设,而是通过学习人类偏好来选择和优化生成结果。
关键设计:评论代理的关键设计包括:1) 双记忆机制:利用两个记忆模块分别存储全局图像特征和局部人体姿态特征,从而更全面地理解输入图像。2) 自反思机制:通过让评论代理对自身的评估结果进行反思,从而提高评估的准确性。3) 偏好损失函数:设计了一种基于排序的损失函数,用于训练扩散模型,使其能够生成更符合人类偏好的HMR结果。具体的参数设置和网络结构细节在论文中有详细描述,此处不再赘述。
🖼️ 关键图片
📊 实验亮点
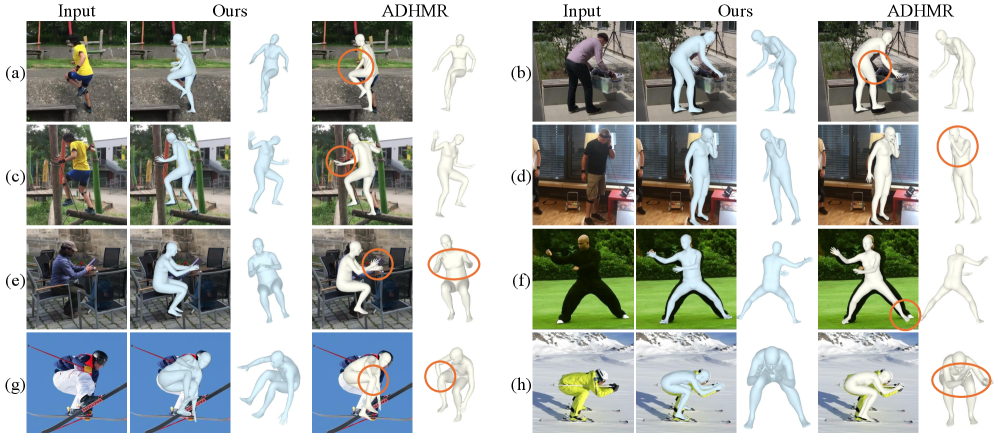
实验结果表明,该方法在多个公开数据集上取得了显著的性能提升,超越了当前最先进的方法。具体而言,在3D人体姿态估计的常用指标(如MPJPE和PVE)上,该方法均取得了明显的改进。此外,定性结果也表明,该方法生成的3D人体网格在物理合理性和图像一致性方面均有显著提升。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏开发、动画制作等领域,提升虚拟角色的真实感和交互性。在运动分析、康复训练等领域也有潜在应用价值,通过准确的人体姿态估计,可以为相关应用提供更可靠的数据支持。未来,该技术有望进一步推广到其他3D人体建模任务中。
📄 摘要(原文)
Human mesh recovery (HMR) from a single RGB image is inherently ambiguous, as multiple 3D poses can correspond to the same 2D observation. Recent diffusion-based methods tackle this by generating various hypotheses, but often sacrifice accuracy. They yield predictions that are either physically implausible or drift from the input image, especially under occlusion or in cluttered, in-the-wild scenes. To address this, we introduce a dual-memory augmented HMR critique agent with self-reflection to produce context-aware quality scores for predicted meshes. These scores distill fine-grained cues about 3D human motion structure, physical feasibility, and alignment with the input image. We use these scores to build a group-wise HMR preference dataset. Leveraging this dataset, we propose a group preference alignment framework for finetuning diffusion-based HMR models. This process injects the rich preference signals into the model, guiding it to generate more physically plausible and image-consistent human meshes. Extensive experiments demonstrate that our method achieves superior performance compared to state-of-the-art approaches.