EMAD: Evidence-Centric Grounded Multimodal Diagnosis for Alzheimer's Disease
作者: Qiuhui Chen, Xuancheng Yao, Zhenglei Zhou, Xinyue Hu, Yi Hong
分类: cs.CV
发布日期: 2026-02-22
备注: Accepted by CVPR2026
💡 一句话要点
EMAD:面向阿尔茨海默病的证据驱动多模态诊断框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿尔茨海默病诊断 多模态学习 可解释性AI 视觉-语言模型 知识蒸馏 强化学习 医学图像分析
📋 核心要点
- 现有医学图像分析的深度学习模型缺乏透明性,难以与临床指南对齐,且决策缺乏证据支持。
- EMAD框架通过分层SEA grounding机制,将诊断报告中的每个声明与多模态证据(临床证据和MRI解剖结构)显式关联。
- EMAD在AD-MultiSense数据集上实现了最先进的诊断准确性,并生成了更透明、解剖学上更准确的报告。
📝 摘要(中文)
医学图像分析中的深度学习模型通常是黑盒,很少与临床指南对齐或将决策与支持证据明确联系起来。这在阿尔茨海默病(AD)中尤为重要,因为预测应基于解剖学和临床发现。我们提出了EMAD,一个视觉-语言框架,它生成结构化的AD诊断报告,其中每个声明都明确地基于多模态证据。EMAD使用分层的句子-证据-解剖(SEA) grounding 机制:(i)句子到证据的grounding将生成的句子链接到临床证据短语,以及(ii)证据到解剖的grounding将相应的结构定位在3D脑部MRI上。为了减少密集的标注需求,我们提出了GTX-Distill,它将grounding行为从使用有限监督训练的教师转移到在模型生成的报告上运行的学生。我们进一步引入了Executable-Rule GRPO,一种具有可验证奖励的强化微调方案,它强制执行临床一致性、协议遵守和推理-诊断一致性。在AD-MultiSense数据集上,EMAD实现了最先进的诊断准确性,并生成比现有方法更透明、解剖学上更忠实的报告。我们将发布代码和grounding注释,以支持未来在可信医学视觉-语言模型方面的研究。
🔬 方法详解
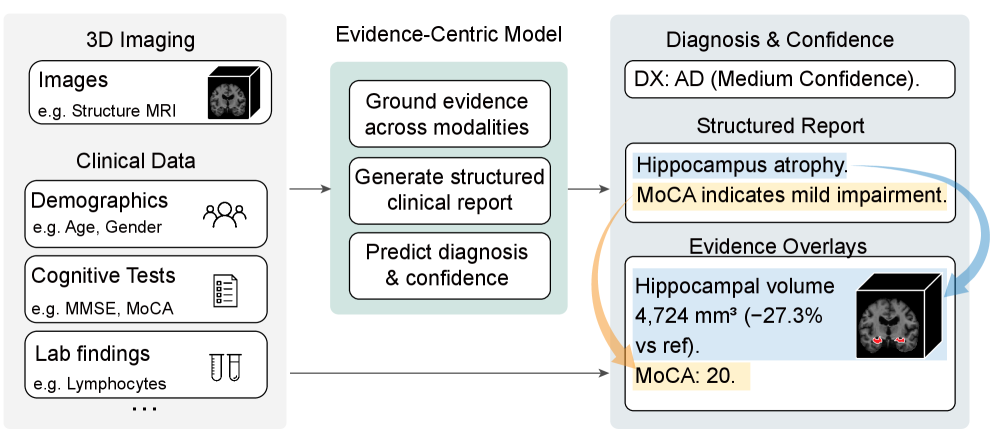
问题定义:现有基于深度学习的医学图像分析模型通常是黑盒模型,缺乏透明性和可解释性。在阿尔茨海默病(AD)诊断中,仅仅给出诊断结果是不够的,医生需要知道模型是基于哪些临床证据和解剖结构做出的判断。因此,如何让模型能够生成带有证据支持的诊断报告,并且保证报告的临床一致性和准确性,是一个重要的挑战。
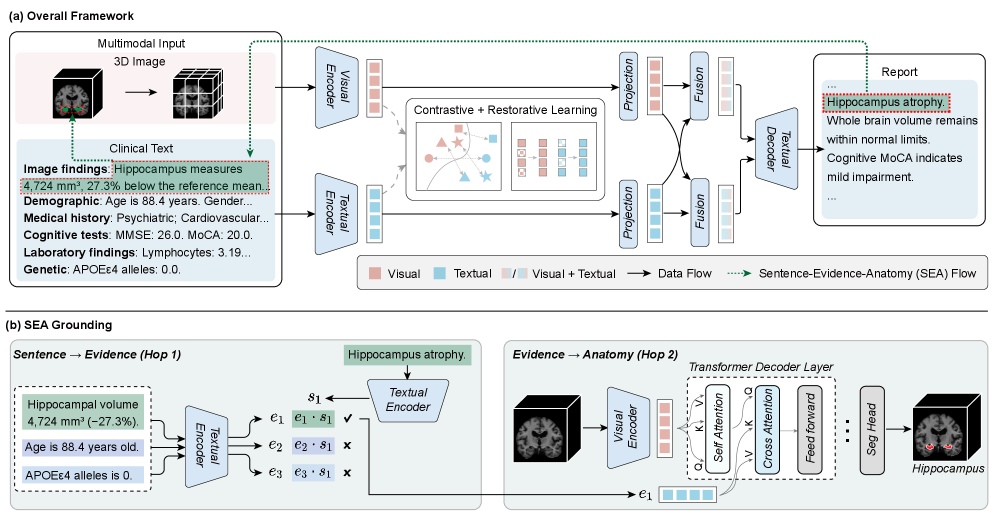
核心思路:EMAD的核心思路是将诊断报告的生成过程与多模态证据(临床文本和MRI图像)进行显式关联,从而提高模型的可解释性和可信度。具体来说,EMAD通过一个分层的grounding机制,将生成的诊断报告中的每个句子与对应的临床证据短语和MRI图像中的解剖结构进行链接。这样,医生就可以清楚地看到模型是基于哪些证据做出的诊断。
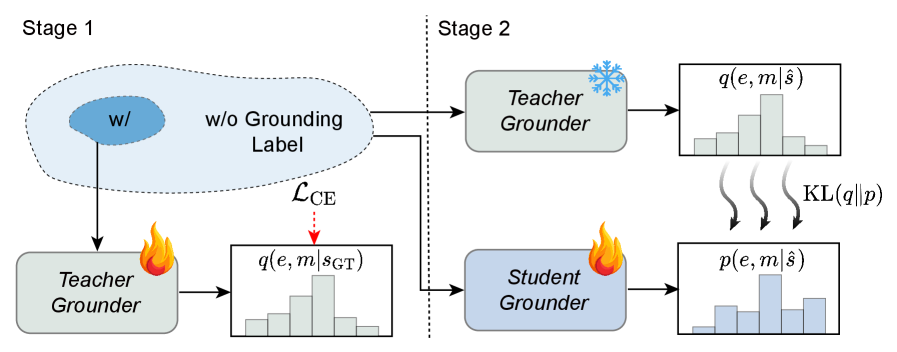
技术框架:EMAD的整体框架包括以下几个主要模块:1) 句子-证据-解剖(SEA)grounding模块:该模块负责将生成的诊断报告中的每个句子与对应的临床证据短语和MRI图像中的解剖结构进行链接。2) GTX-Distill模块:该模块使用知识蒸馏技术,将grounding行为从一个在少量标注数据上训练的教师模型转移到一个在模型生成的报告上运行的学生模型,从而减少了对大量标注数据的需求。3) Executable-Rule GRPO模块:该模块使用强化学习技术,通过可验证的奖励来强制执行临床一致性、协议遵守和推理-诊断一致性。
关键创新:EMAD的关键创新在于其分层的SEA grounding机制和Executable-Rule GRPO强化微调方案。SEA grounding机制能够将诊断报告的生成过程与多模态证据进行显式关联,从而提高模型的可解释性和可信度。Executable-Rule GRPO强化微调方案能够强制执行临床一致性、协议遵守和推理-诊断一致性,从而提高诊断报告的质量。
关键设计:EMAD的关键设计包括:1) 使用Transformer模型作为生成器,生成诊断报告。2) 使用预训练的语言模型(如BERT)来编码临床文本。3) 使用3D卷积神经网络来提取MRI图像的特征。4) 使用注意力机制来实现句子-证据和证据-解剖的grounding。5) 使用基于规则的奖励函数来指导强化学习过程。
🖼️ 关键图片
📊 实验亮点
EMAD在AD-MultiSense数据集上取得了state-of-the-art的诊断准确率,并且生成的报告在解剖学上更加准确和透明。相较于现有方法,EMAD能够提供更强的证据支持,从而提高诊断的可信度。论文还开源了代码和标注数据,为未来的研究提供了便利。
🎯 应用场景
EMAD框架可应用于阿尔茨海默病和其他疾病的辅助诊断,帮助医生更准确、更高效地进行诊断。该框架生成的带有证据支持的诊断报告可以提高诊断的可解释性和可信度,并为临床决策提供更有力的支持。此外,该框架还可以用于医学教育和研究,帮助学生和研究人员更好地理解疾病的诊断过程。
📄 摘要(原文)
Deep learning models for medical image analysis often act as black boxes, seldom aligning with clinical guidelines or explicitly linking decisions to supporting evidence. This is especially critical in Alzheimer's disease (AD), where predictions should be grounded in both anatomical and clinical findings. We present EMAD, a vision-language framework that generates structured AD diagnostic reports in which each claim is explicitly grounded in multimodal evidence. EMAD uses a hierarchical Sentence-Evidence-Anatomy (SEA) grounding mechanism: (i) sentence-to-evidence grounding links generated sentences to clinical evidence phrases, and (ii) evidence-to-anatomy grounding localizes corresponding structures on 3D brain MRI. To reduce dense annotation requirements, we propose GTX-Distill, which transfers grounding behavior from a teacher trained with limited supervision to a student operating on model-generated reports. We further introduce Executable-Rule GRPO, a reinforcement fine-tuning scheme with verifiable rewards that enforces clinical consistency, protocol adherence, and reasoning-diagnosis coherence. On the AD-MultiSense dataset, EMAD achieves state-of-the-art diagnostic accuracy and produces more transparent, anatomically faithful reports than existing methods. We will release code and grounding annotations to support future research in trustworthy medical vision-language models.