JavisDiT++: Unified Modeling and Optimization for Joint Audio-Video Generation
作者: Kai Liu, Yanhao Zheng, Kai Wang, Shengqiong Wu, Rongjunchen Zhang, Jiebo Luo, Dimitrios Hatzinakos, Ziwei Liu, Hao Fei, Tat-Seng Chua
分类: cs.CV, cs.MM, cs.SD
发布日期: 2026-02-22
备注: Accepted by ICLR 2026. Homepage: https://JavisVerse.github.io/JavisDiT2-page
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
JavisDiT++:提出统一建模与优化框架,用于高质量联合音视频生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联合音视频生成 多模态学习 扩散模型 时间同步 偏好优化 混合专家网络 AIGC
📋 核心要点
- 现有开源联合音视频生成方法在生成质量、时间同步性和人类偏好对齐方面存在不足,与商业模型存在差距。
- JavisDiT++通过模态特定混合专家、时间对齐RoPE和音视频直接偏好优化,实现统一建模与优化。
- 实验表明,JavisDiT++仅使用少量数据即可达到SOTA性能,并在质量和同步性上显著优于现有方法。
📝 摘要(中文)
AIGC已从文本到图像生成迅速扩展到高质量的视频和音频多模态合成。在此背景下,联合音视频生成(JAVG)已成为一项基础任务,旨在从文本描述中生成同步且语义对齐的声音和视觉内容。然而,与Veo3等先进商业模型相比,现有的开源方法在生成质量、时间同步性和与人类偏好对齐方面仍然存在局限性。为了弥合这一差距,本文提出了JavisDiT++,这是一个简洁而强大的框架,用于JAVG的统一建模和优化。首先,我们引入了一种特定模态的混合专家(MS-MoE)设计,以提高跨模态交互的有效性,同时增强单模态生成质量。然后,我们提出了一种时间对齐的RoPE(TA-RoPE)策略,以实现音频和视频token之间显式的帧级别同步。此外,我们开发了一种音视频直接偏好优化(AV-DPO)方法,以使模型输出在质量、一致性和同步性维度上与人类偏好对齐。基于Wan2.1-1.3B-T2V,我们的模型仅使用约100万个公共训练条目就实现了最先进的性能,在定性和定量评估中均显著优于现有方法。我们进行了全面的消融研究,以验证我们提出的模块的有效性。所有代码、模型和数据集均已发布。
🔬 方法详解
问题定义:论文旨在解决联合音视频生成任务中,现有开源方法在生成质量、时间同步性和与人类偏好对齐方面存在的不足。现有方法难以生成高质量、同步且符合人类偏好的音视频内容,与商业模型存在显著差距。
核心思路:论文的核心思路是提出一个统一的建模和优化框架JavisDiT++,通过模态特定混合专家(MS-MoE)增强单模态生成质量和跨模态交互,通过时间对齐RoPE(TA-RoPE)实现显式的帧级别同步,并通过音视频直接偏好优化(AV-DPO)使模型输出与人类偏好对齐。这样设计的目的是为了提升生成质量、保证时间同步性并符合人类审美。
技术框架:JavisDiT++框架主要包含三个核心模块:1) 模态特定混合专家(MS-MoE):用于增强单模态生成质量和跨模态交互;2) 时间对齐RoPE(TA-RoPE):用于实现音频和视频token之间显式的帧级别同步;3) 音视频直接偏好优化(AV-DPO):用于使模型输出在质量、一致性和同步性维度上与人类偏好对齐。整体流程是,首先使用MS-MoE进行特征提取和融合,然后使用TA-RoPE进行时间同步,最后使用AV-DPO进行偏好对齐优化。
关键创新:论文最重要的技术创新点在于提出了一个统一的建模和优化框架,将模态特定混合专家、时间对齐RoPE和音视频直接偏好优化三个模块有机结合,从而在生成质量、时间同步性和人类偏好对齐三个方面都取得了显著提升。与现有方法相比,JavisDiT++能够生成更高质量、更同步且更符合人类偏好的音视频内容。
关键设计:MS-MoE的具体实现方式未知,但其核心思想是为每个模态设计独立的专家网络,并允许跨模态交互。TA-RoPE的关键在于如何将RoPE应用于时间维度,以实现帧级别的同步。AV-DPO的关键在于如何设计合适的奖励函数,以反映人类在质量、一致性和同步性方面的偏好。具体的参数设置、损失函数和网络结构等技术细节需要在论文中进一步查找。
🖼️ 关键图片
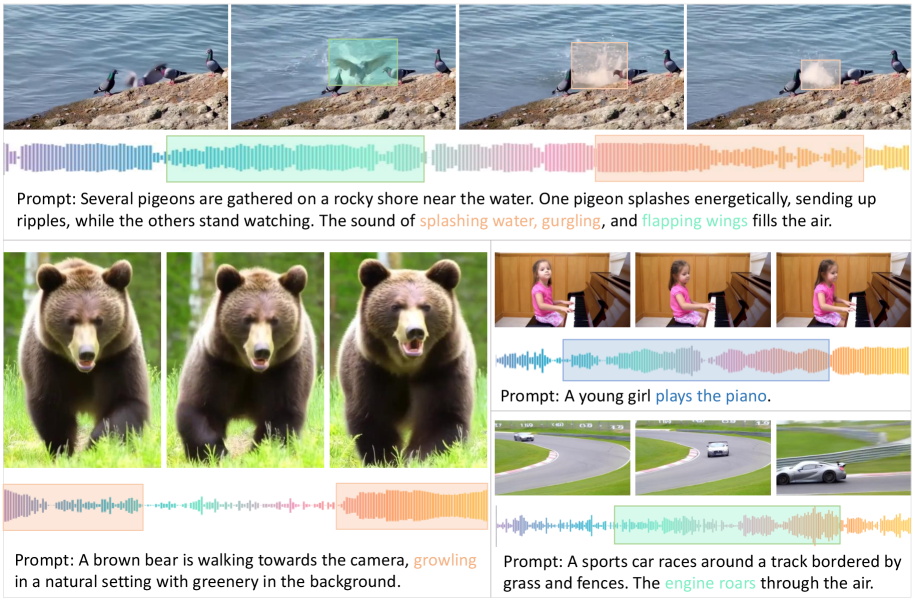
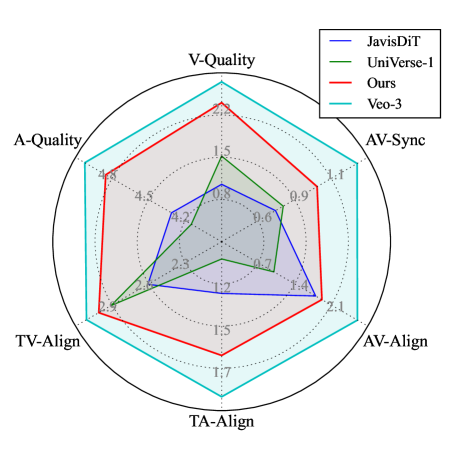
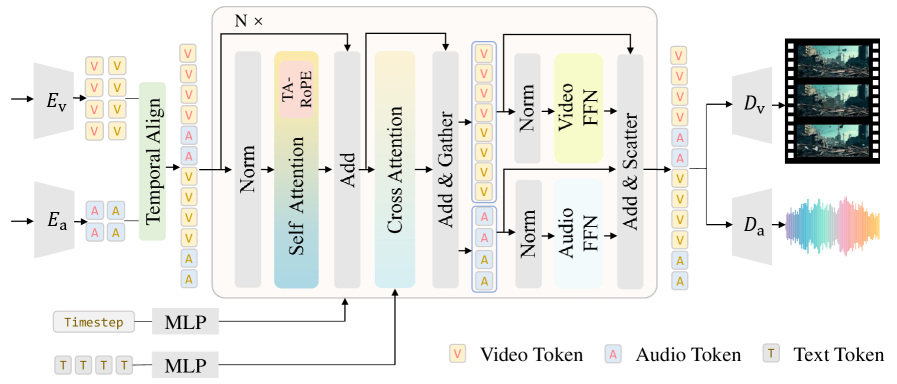
📊 实验亮点
JavisDiT++模型基于Wan2.1-1.3B-T2V,仅使用约100万个公共训练条目就实现了最先进的性能。在定性和定量评估中,JavisDiT++在生成质量和时间同步性方面均显著优于现有方法。消融实验验证了MS-MoE、TA-RoPE和AV-DPO三个模块的有效性,证明了该框架的优越性。
🎯 应用场景
该研究成果可广泛应用于AIGC领域,例如电影制作、游戏开发、虚拟现实、广告创意等。它可以帮助用户快速生成高质量、同步且符合人类偏好的音视频内容,从而降低创作成本、提高创作效率,并为用户带来更好的视听体验。未来,该技术有望进一步发展,实现更加智能和个性化的音视频生成。
📄 摘要(原文)
AIGC has rapidly expanded from text-to-image generation toward high-quality multimodal synthesis across video and audio. Within this context, joint audio-video generation (JAVG) has emerged as a fundamental task that produces synchronized and semantically aligned sound and vision from textual descriptions. However, compared with advanced commercial models such as Veo3, existing open-source methods still suffer from limitations in generation quality, temporal synchrony, and alignment with human preferences. To bridge the gap, this paper presents JavisDiT++, a concise yet powerful framework for unified modeling and optimization of JAVG. First, we introduce a modality-specific mixture-of-experts (MS-MoE) design that enables cross-modal interaction efficacy while enhancing single-modal generation quality. Then, we propose a temporal-aligned RoPE (TA-RoPE) strategy to achieve explicit, frame-level synchronization between audio and video tokens. Besides, we develop an audio-video direct preference optimization (AV-DPO) method to align model outputs with human preference across quality, consistency, and synchrony dimensions. Built upon Wan2.1-1.3B-T2V, our model achieves state-of-the-art performance merely with around 1M public training entries, significantly outperforming prior approaches in both qualitative and quantitative evaluations. Comprehensive ablation studies have been conducted to validate the effectiveness of our proposed modules. All the code, model, and dataset are released at https://JavisVerse.github.io/JavisDiT2-page.