Keep it SymPL: Symbolic Projective Layout for Allocentric Spatial Reasoning in Vision-Language Models
作者: Jaeyun Jang, Seunghui Shin, Taeho Park, Hyoseok Hwang
分类: cs.CV
发布日期: 2026-02-22
备注: To appear in CVPR 2026
💡 一句话要点
提出SymPL框架,解决视觉-语言模型中以客体为中心的空间推理难题
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting)
关键词: 空间推理 视觉-语言模型 客体中心 符号布局 透视投影
📋 核心要点
- 现有视觉-语言模型在以自我为中心的空间推理表现良好,但在以客体为中心时性能显著下降,难以理解物体间的相对空间关系。
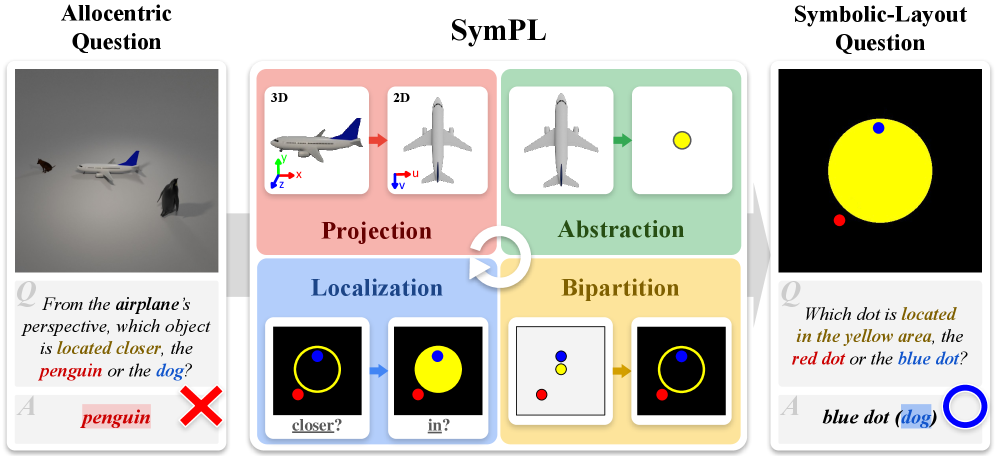
- 论文提出SymPL框架,将客体中心的空间推理转化为符号布局形式,利用投影、抽象、二分和定位等关键因素进行问题重构。
- 实验结果表明,SymPL显著提高了客体中心和自我中心任务的性能,并增强了模型在视觉错觉和多视角场景下的鲁棒性。
📝 摘要(中文)
本文提出了一种名为符号投影布局(SymPL)的框架,旨在解决视觉-语言模型(VLMs)在以客体为中心的空间推理方面的不足。尽管VLMs在以自我为中心的场景中表现良好,但在需要从场景中物体的角度推断空间关系时,性能会显著下降。SymPL通过将客体中心的推理转化为VLMs擅长的符号布局形式来解决这一问题。该框架利用投影、抽象、二分和定位四个关键因素,将客体中心的问题转换为结构化的符号布局表示。大量实验表明,这种重构显著提高了客体中心和自我中心任务的性能,增强了在视觉错觉和多视角场景下的鲁棒性,并且每个组成部分都对这些提升做出了关键贡献。这些结果表明,SymPL为解决复杂的透视感知空间推理提供了一种有效且有原则的方法。
🔬 方法详解
问题定义:视觉-语言模型在以自我为中心的空间推理任务中表现出色,但当需要理解场景中物体之间的空间关系,即以客体为中心进行推理时,性能会显著下降。现有的方法难以有效地从物体的视角推断空间关系,尤其是在存在视觉错觉或多视角的情况下。
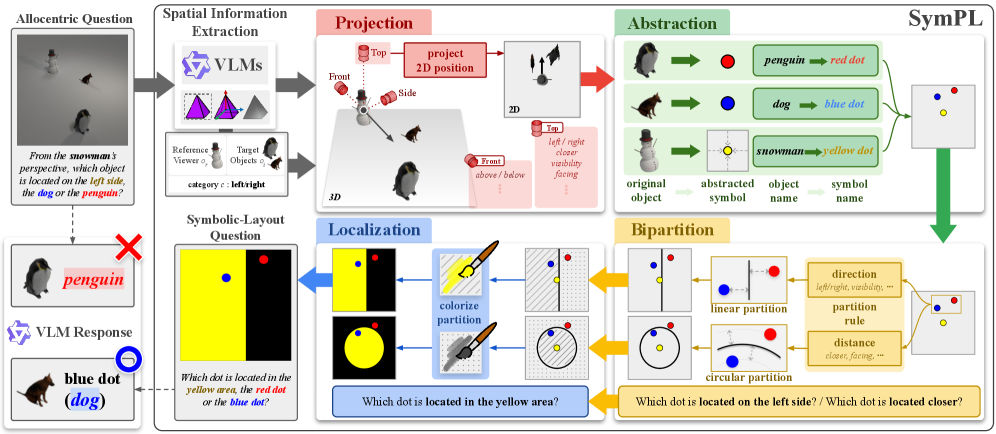
核心思路:论文的核心思路是将复杂的以客体为中心的空间推理问题转化为视觉-语言模型更擅长处理的符号布局形式。通过将场景中的物体及其空间关系抽象成符号化的表示,并利用投影关系将三维空间信息映射到二维布局上,从而简化推理过程。这种方法使得模型能够更容易地理解和推理物体之间的相对位置关系。
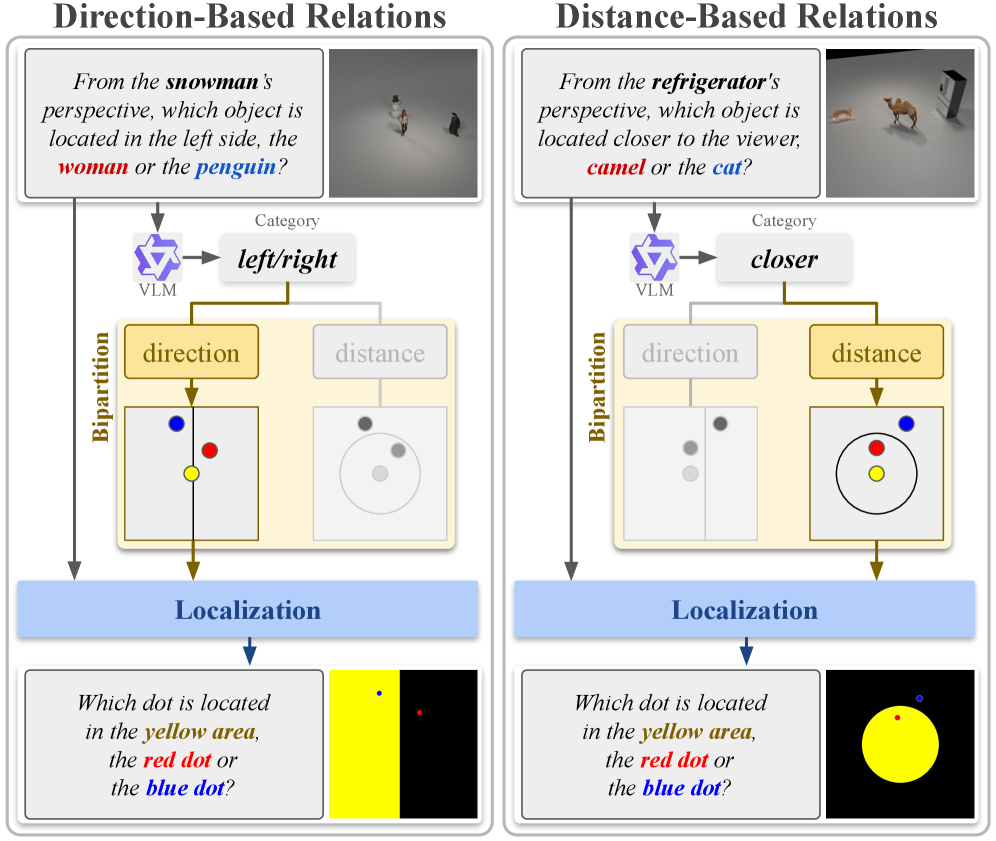
技术框架:SymPL框架主要包含以下几个阶段:1) 投影(Projection):将三维场景投影到二维平面上,建立物体之间的空间关系。2) 抽象(Abstraction):将场景中的物体抽象成符号化的表示,例如用简单的几何形状或标签来代表物体。3) 二分(Bipartition):将场景划分为不同的区域,以便更好地组织和理解物体之间的空间关系。4) 定位(Localization):确定每个物体在符号布局中的位置,并建立物体之间的连接关系。最终,将这些信息编码成一种结构化的符号布局表示,输入到视觉-语言模型中进行推理。
关键创新:SymPL的关键创新在于它提供了一种将复杂的客体中心空间推理问题转化为符号布局表示的通用方法。与直接让视觉-语言模型处理原始图像不同,SymPL通过预处理将问题转化为模型更擅长处理的形式,从而提高了推理的准确性和效率。此外,SymPL框架的模块化设计使得可以灵活地调整和优化每个组成部分,以适应不同的场景和任务。
关键设计:SymPL框架的关键设计包括:1) 使用透视投影来模拟物体之间的空间关系,并考虑了视角的影响。2) 使用简单的符号来表示物体,从而降低了模型的计算复杂度。3) 使用二分法来组织场景,从而更好地捕捉物体之间的空间关系。4) 使用损失函数来优化符号布局的表示,从而提高推理的准确性。具体的参数设置和网络结构取决于具体的视觉-语言模型和任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SymPL框架在客体中心和自我中心的空间推理任务中均取得了显著的性能提升。在视觉错觉和多视角场景下,SymPL表现出更强的鲁棒性。消融实验表明,投影、抽象、二分和定位四个关键因素都对性能提升做出了重要贡献。具体性能数据和对比基线信息在论文中有详细描述。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实和增强现实等领域。通过使机器能够理解和推理以客体为中心的空间关系,可以提高机器在复杂环境中的自主性和适应性。此外,该方法还可以用于改善人机交互,例如,使机器能够更好地理解人类的指令和意图。
📄 摘要(原文)
Perspective-aware spatial reasoning involves understanding spatial relationships from specific viewpoints-either egocentric (observer-centered) or allocentric (object-centered). While vision-language models (VLMs) perform well in egocentric settings, their performance deteriorates when reasoning from allocentric viewpoints, where spatial relations must be inferred from the perspective of objects within the scene. In this study, we address this underexplored challenge by introducing Symbolic Projective Layout (SymPL), a framework that reformulates allocentric reasoning into symbolic-layout forms that VLMs inherently handle well. By leveraging four key factors-projection, abstraction, bipartition, and localization-SymPL converts allocentric questions into structured symbolic-layout representations. Extensive experiments demonstrate that this reformulation substantially improves performance in both allocentric and egocentric tasks, enhances robustness under visual illusions and multi-view scenarios, and that each component contributes critically to these gains. These results show that SymPL provides an effective and principled approach for addressing complex perspective-aware spatial reasoning.