Universal 3D Shape Matching via Coarse-to-Fine Language Guidance
作者: Qinfeng Xiao, Guofeng Mei, Bo Yang, Liying Zhang, Jian Zhang, Kit-lun Yick
分类: cs.CV
发布日期: 2026-02-22
备注: Accepted CVPR 2026
💡 一句话要点
提出UniMatch,通过粗到细的语言引导实现通用3D形状匹配。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D形状匹配 语义对应 多模态学习 视觉语言模型 非等距形状
📋 核心要点
- 现有形状匹配方法依赖于近等距假设和同类对象,难以处理跨类别对象的语义对应。
- UniMatch利用多模态大语言模型和视觉语言模型,将粗略语义信息转化为精细的密集对应关系。
- 实验表明,UniMatch在各种场景中优于现有方法,实现了跨类别和非等距形状的通用匹配。
📝 摘要(中文)
本文提出UniMatch,一个语义感知的、由粗到精的框架,用于构建强非等距形状之间的密集语义对应关系,且不限制对象类别。核心思想是将“粗略”的语义线索提升为“精细”的对应关系,这通过两个阶段实现。在“粗略”阶段,执行类别无关的3D分割以获得非重叠的语义部分,并提示多模态大型语言模型(MLLM)来识别部件名称。然后,利用预训练的视觉语言模型(VLM)提取文本嵌入,从而构建匹配的语义部分。在“精细”阶段,利用这些粗略的对应关系,通过专门的基于排序的对比方案来指导密集对应关系的學習。由于类别无关的分割、语言引导和基于排序的对比学习,该方法适用于通用对象类别,不需要预定义的部件提议,从而实现类间和非等距形状的通用匹配。大量实验表明,UniMatch在各种具有挑战性的场景中始终优于竞争方法。
🔬 方法详解
问题定义:论文旨在解决跨类别、非等距3D形状之间的语义对应问题。现有方法通常依赖于形状的等距性或需要预定义的部件信息,限制了其通用性和适用范围。因此,如何建立不同类别、差异较大的3D形状之间的可靠语义对应关系是一个挑战。
核心思路:论文的核心思路是利用语言的语义理解能力来引导3D形状的匹配过程。通过将3D形状分割成语义部件,并利用多模态大语言模型识别这些部件的名称,从而建立粗略的语义对应关系。然后,利用这些粗略的对应关系来指导精细的密集对应关系的學習。这种由粗到精的策略能够有效地处理非等距形状和跨类别对象。
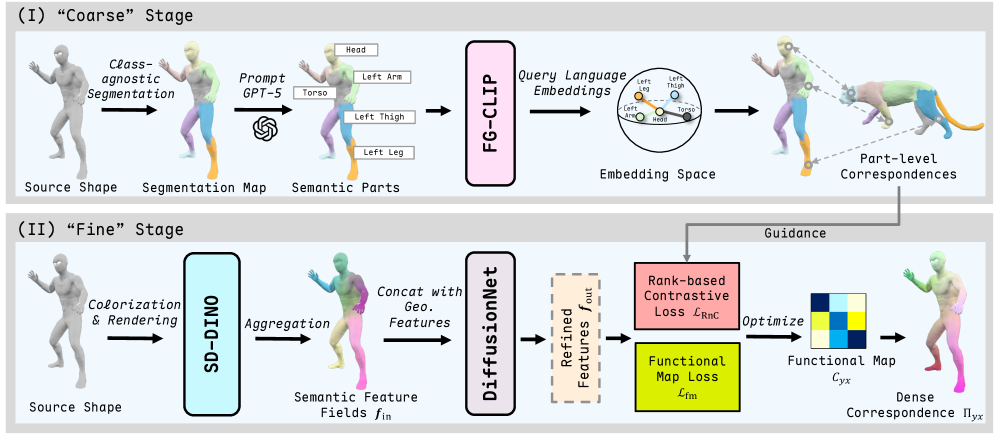
技术框架:UniMatch框架包含两个主要阶段:粗略阶段和精细阶段。在粗略阶段,首先使用类别无关的3D分割算法将3D形状分割成多个非重叠的语义部件。然后,利用多模态大语言模型(MLLM)识别每个部件的名称。接着,使用预训练的视觉语言模型(VLM)提取部件名称的文本嵌入,并基于文本嵌入的相似度建立粗略的语义对应关系。在精细阶段,利用粗略的对应关系作为指导,通过基于排序的对比学习方法来学习密集的对应关系。
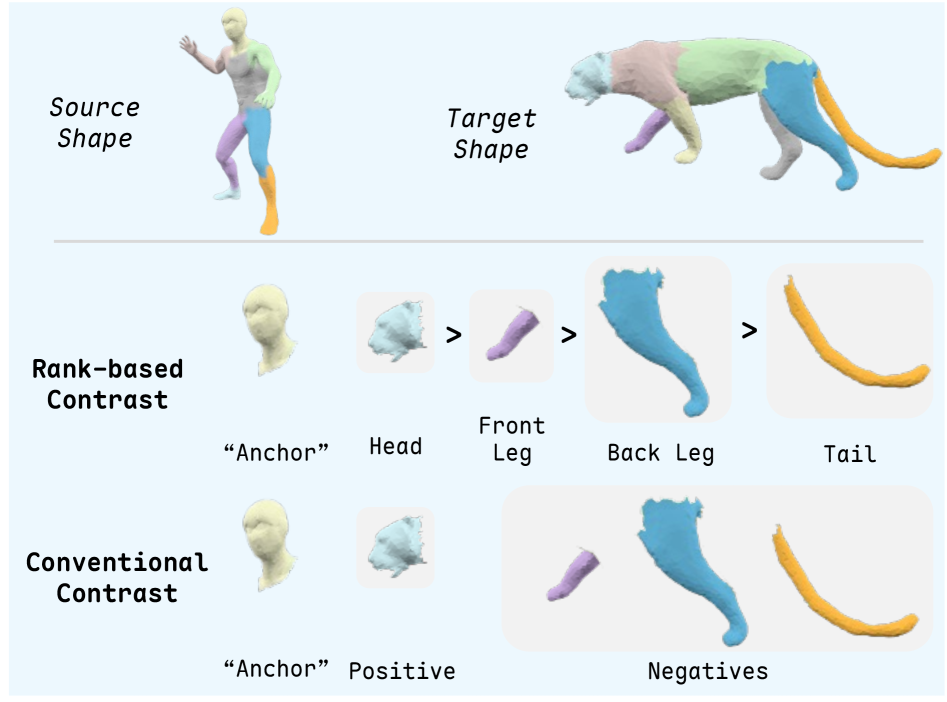
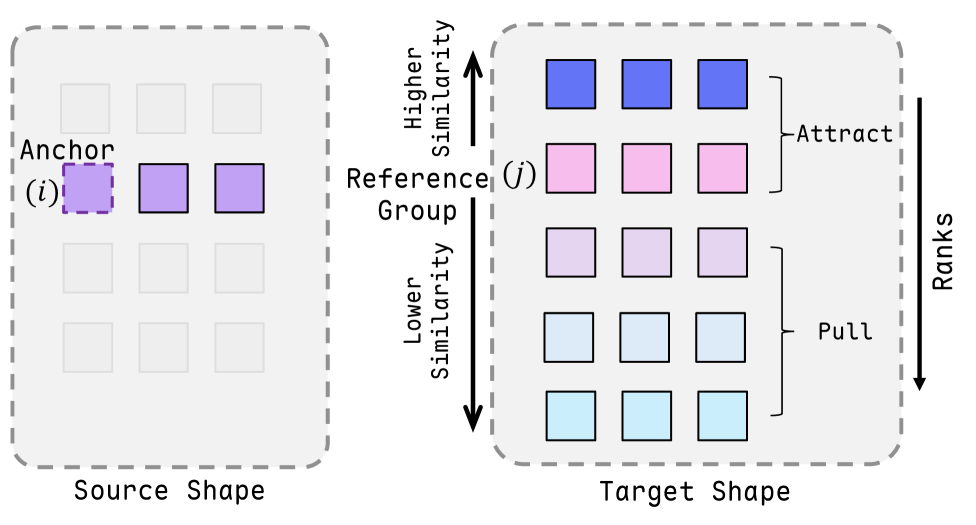
关键创新:UniMatch的关键创新在于利用语言的语义信息来引导3D形状的匹配过程。通过结合类别无关的3D分割、多模态大语言模型和视觉语言模型,实现了跨类别、非等距形状之间的通用匹配。此外,基于排序的对比学习方法能够有效地利用粗略的对应关系来学习精细的对应关系。
关键设计:在粗略阶段,使用了类别无关的3D分割算法,例如基于图割的方法,以确保分割的部件具有语义一致性。多模态大语言模型用于识别部件名称,例如使用CLIP模型提取文本嵌入。在精细阶段,使用了基于排序的对比损失函数,该损失函数鼓励匹配的对应点具有更高的相似度,而不匹配的对应点具有更低的相似度。具体的网络结构和参数设置在论文中有详细描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
UniMatch在多个具有挑战性的数据集上进行了评估,包括跨类别形状匹配和非等距形状匹配。实验结果表明,UniMatch在各种场景中始终优于现有的形状匹配方法。具体的性能提升幅度未知,但论文强调了UniMatch的通用性和鲁棒性。
🎯 应用场景
UniMatch具有广泛的应用前景,例如在3D模型检索、动画制作、机器人操作和虚拟现实等领域。它可以用于建立不同类别对象之间的语义对应关系,从而实现更智能的3D模型搜索、更自然的动画生成、更灵活的机器人操作和更逼真的虚拟现实体验。该研究的未来影响在于推动跨类别3D形状理解和操作的发展。
📄 摘要(原文)
Establishing dense correspondences between shapes is a crucial task in computer vision and graphics, while prior approaches depend on near-isometric assumptions and homogeneous subject types (i.e., only operate for human shapes). However, building semantic correspondences for cross-category objects remains challenging and has received relatively little attention. To achieve this, we propose UniMatch, a semantic-aware, coarse-to-fine framework for constructing dense semantic correspondences between strongly non-isometric shapes without restricting object categories. The key insight is to lift "coarse" semantic cues into "fine" correspondence, which is achieved through two stages. In the "coarse" stage, we perform class-agnostic 3D segmentation to obtain non-overlapping semantic parts and prompt multimodal large language models (MLLMs) to identify part names. Then, we employ pretrained vision language models (VLMs) to extract text embeddings, enabling the construction of matched semantic parts. In the "fine" stage, we leverage these coarse correspondences to guide the learning of dense correspondences through a dedicated rank-based contrastive scheme. Thanks to class-agnostic segmentation, language guiding, and rank-based contrastive learning, our method is versatile for universal object categories and requires no predefined part proposals, enabling universal matching for inter-class and non-isometric shapes. Extensive experiments demonstrate UniMatch consistently outperforms competing methods in various challenging scenarios.