CREM: Compression-Driven Representation Enhancement for Multimodal Retrieval and Comprehension
作者: Lihao Liu, Yan Wang, Biao Yang, Da Li, Jiangxia Cao, Yuxiao Luo, Xiang Chen, Xiangyu Wu, Wei Yuan, Fan Yang, Guiguang Ding, Tingting Gao, Guorui Zhou
分类: cs.CV
发布日期: 2026-02-22
💡 一句话要点
CREM:通过压缩驱动的表征增强,统一多模态检索与理解任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 多模态理解 表征学习 压缩驱动 大型语言模型
📋 核心要点
- 现有MLLM应用于检索任务时,存在输出格式与优化目标不一致的问题,且对比微调会牺牲生成能力。
- CREM通过压缩驱动的提示设计和训练策略,统一了检索和生成任务,增强了多模态表征。
- 实验表明,CREM在检索任务上达到SOTA,同时保持了强大的生成能力,验证了生成监督对表征质量的提升。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉描述和视觉问答等理解任务中取得了显著成功。然而,由于输出格式和优化目标之间的差异,直接将其应用于基于嵌入的任务(如检索)仍然具有挑战性。以往的方法通常采用对比微调来使MLLM适应检索,但代价是失去了其生成能力。我们认为,生成任务和嵌入任务从根本上依赖于共享的认知机制,特别是跨模态表征对齐和上下文理解。为此,我们提出了CREM(压缩驱动的表征增强模型),它采用统一的框架来增强多模态表征,以进行检索,同时保持生成能力。具体来说,我们引入了一种基于压缩的提示设计,其中包含可学习的合唱token来聚合多模态语义,以及一种压缩驱动的训练策略,该策略通过压缩感知的注意力机制整合对比和生成目标。大量实验表明,CREM在MMEB上实现了最先进的检索性能,同时在多个理解基准测试中保持了强大的生成性能。我们的研究结果表明,在所提出的压缩驱动范式下,生成监督可以进一步提高MLLM的表征质量。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在应用于基于嵌入的检索任务时,由于输出格式和优化目标差异导致的性能瓶颈问题。现有方法通常采用对比微调,但会牺牲MLLM的生成能力,无法兼顾检索和生成两种能力。
核心思路:论文的核心思路是通过压缩驱动的表征增强,统一检索和生成任务。作者认为,检索和生成任务都依赖于跨模态表征对齐和上下文理解等共享认知机制。因此,通过设计一种能够同时优化检索和生成能力的训练策略,可以提升MLLM的整体表征质量。
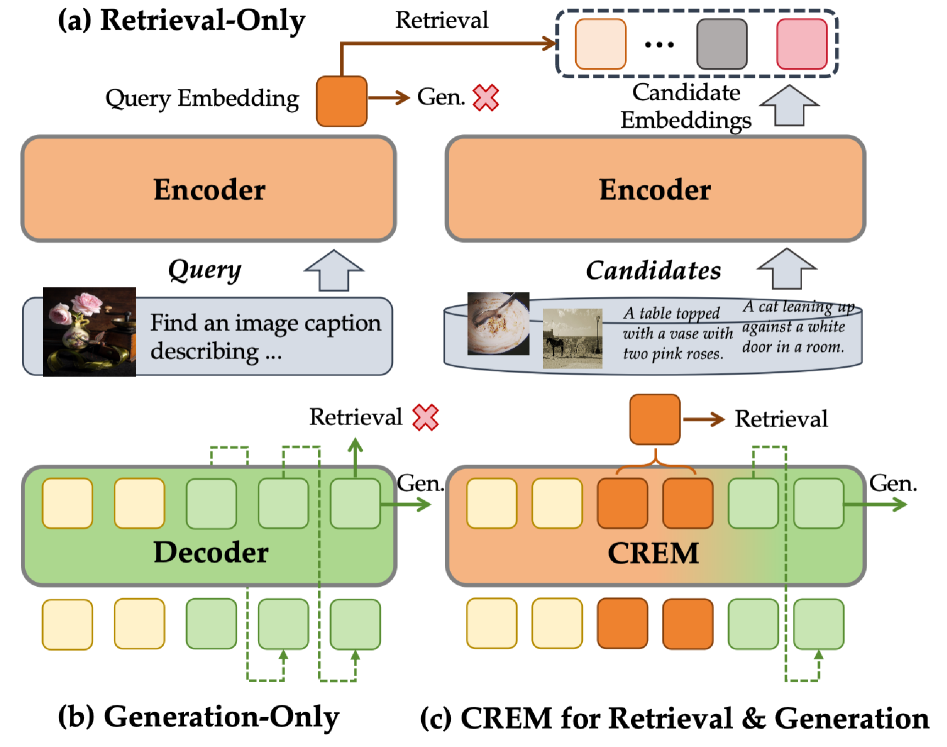
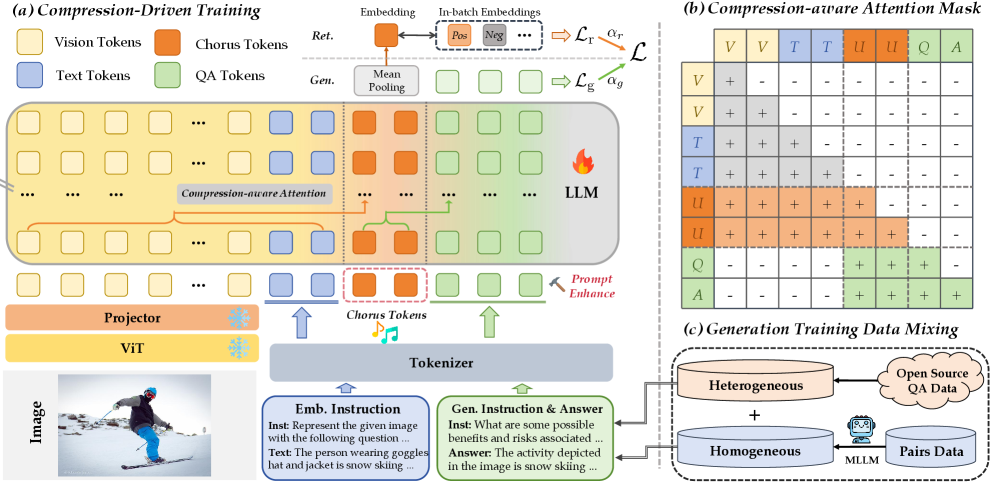
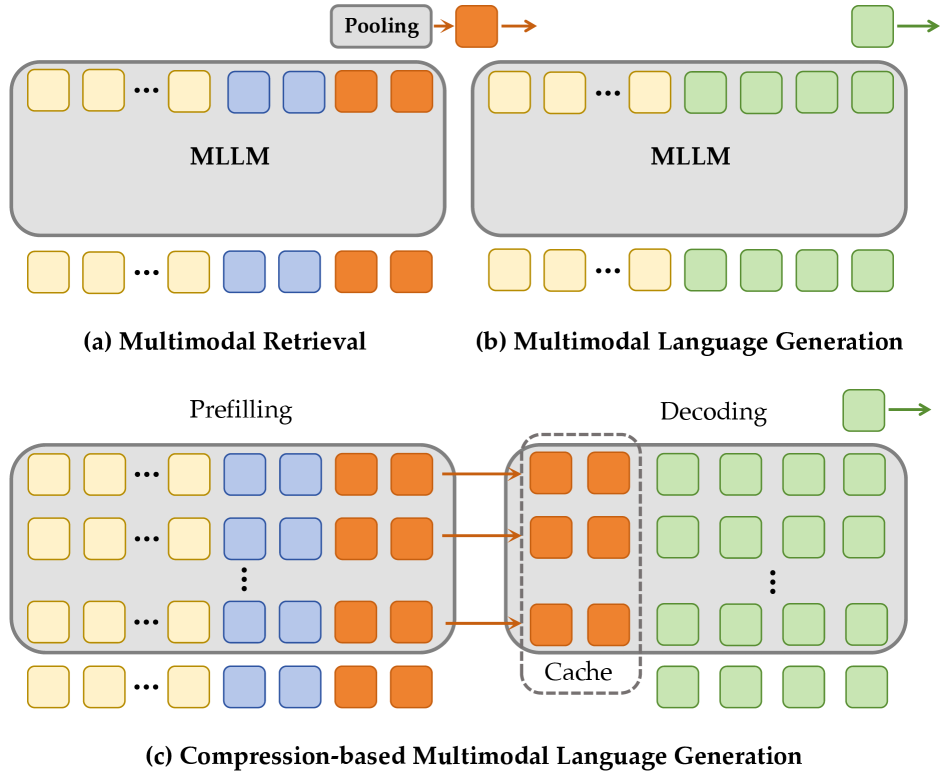
技术框架:CREM的整体框架包含两个主要组成部分:1) 基于压缩的提示设计:引入可学习的合唱token来聚合多模态语义,将多模态信息压缩成更紧凑的表征。2) 压缩驱动的训练策略:通过压缩感知的注意力机制,整合对比学习和生成学习的目标,从而同时优化检索和生成能力。
关键创新:CREM的关键创新在于其压缩驱动的训练范式。与以往的对比微调方法不同,CREM利用生成任务的监督信号来提升表征质量,从而在不牺牲生成能力的前提下,提高检索性能。此外,可学习的合唱token的设计也为多模态信息的有效聚合提供了一种新的思路。
关键设计:在提示设计方面,作者引入了可学习的“chorus tokens”,这些tokens与视觉特征和文本提示一起输入到MLLM中,并通过训练来学习如何有效地聚合多模态信息。在训练策略方面,作者设计了一个联合损失函数,该函数结合了对比损失(用于检索)和生成损失(用于生成),并通过压缩感知的注意力机制来平衡两个目标。具体的损失函数形式和注意力机制的实现细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
CREM在MMEB检索基准上取得了SOTA性能,显著优于现有方法。同时,在多个理解基准测试中保持了强大的生成性能,证明了该方法在提升检索性能的同时,不会牺牲MLLM的生成能力。实验结果表明,生成监督可以有效提升MLLM的表征质量。
🎯 应用场景
CREM的研究成果可应用于各种多模态信息检索和理解场景,例如图像/视频检索、跨模态问答、多模态对话系统等。该方法能够提升检索的准确性和效率,同时保持MLLM的生成能力,具有广泛的应用前景。未来,该方法还可以扩展到其他多模态任务,例如多模态摘要、多模态翻译等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have shown remarkable success in comprehension tasks such as visual description and visual question answering. However, their direct application to embedding-based tasks like retrieval remains challenging due to the discrepancy between output formats and optimization objectives. Previous approaches often employ contrastive fine-tuning to adapt MLLMs for retrieval, but at the cost of losing their generative capabilities. We argue that both generative and embedding tasks fundamentally rely on shared cognitive mechanisms, specifically cross-modal representation alignment and contextual comprehension. To this end, we propose CREM (Compression-driven Representation Enhanced Model), with a unified framework that enhances multimodal representations for retrieval while preserving generative ability. Specifically, we introduce a compression-based prompt design with learnable chorus tokens to aggregate multimodal semantics and a compression-driven training strategy that integrates contrastive and generative objectives through compression-aware attention. Extensive experiments demonstrate that CREM achieves state-of-the-art retrieval performance on MMEB while maintaining strong generative performance on multiple comprehension benchmarks. Our findings highlight that generative supervision can further improve the representational quality of MLLMs under the proposed compression-driven paradigm.