Ani3DHuman: Photorealistic 3D Human Animation with Self-guided Stochastic Sampling
作者: Qi Sun, Can Wang, Jiaxiang Shang, Yingchun Liu, Jing Liao
分类: cs.CV, cs.GR, cs.LG
发布日期: 2026-02-22
备注: CVPR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
Ani3DHuman:结合运动学与扩散先验的逼真3D人体动画生成
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 3D人体动画 视频扩散模型 非刚性运动 随机采样 自引导 运动学 分层运动表示
📋 核心要点
- 现有3D人体动画方法在非刚性运动建模和照片级真实感方面存在不足,难以兼顾运动细节和视觉质量。
- Ani3DHuman通过分层运动表示解耦刚性和非刚性运动,并利用自引导随机采样方法,有效结合运动学和扩散模型的优势。
- 实验结果表明,Ani3DHuman在生成逼真3D人体动画方面优于现有方法,显著提升了视觉质量和运动细节。
📝 摘要(中文)
当前3D人体动画方法难以实现照片级真实感:基于运动学的方法缺乏非刚性动力学(如服装动力学),而利用视频扩散先验的方法可以合成非刚性运动,但存在质量伪影和身份丢失的问题。为了克服这些限制,我们提出了Ani3DHuman,一个结合了基于运动学的动画和视频扩散先验的框架。我们首先引入分层运动表示,将刚性运动与残余非刚性运动分离。刚性运动由运动学方法生成,然后产生粗略渲染,以指导视频扩散模型生成视频序列,从而恢复残余非刚性运动。然而,这种基于扩散采样的恢复任务极具挑战性,因为初始渲染是分布外的,导致标准确定性ODE采样器失效。因此,我们提出了一种新颖的自引导随机采样方法,通过结合随机采样(用于照片级真实感)和自引导(用于身份保真度)来有效解决分布外问题。这些恢复的视频提供高质量的监督,从而能够优化残余非刚性运动场。大量实验表明,Ani3DHuman可以生成照片级真实的3D人体动画,优于现有方法。
🔬 方法详解
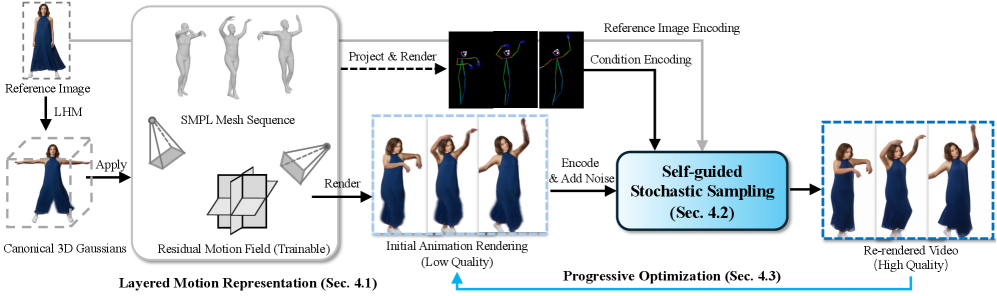
问题定义:现有3D人体动画方法主要面临两个挑战。一是基于运动学的方法难以模拟非刚性运动,如服装的动态效果。二是利用视频扩散模型的方法虽然可以生成非刚性运动,但容易出现质量伪影和身份信息丢失的问题。因此,如何生成既具有真实运动细节,又具有照片级真实感的3D人体动画是一个亟待解决的问题。
核心思路:Ani3DHuman的核心思路是将基于运动学的动画和视频扩散先验相结合。首先,利用运动学方法生成刚性运动,然后使用视频扩散模型来恢复残余的非刚性运动。为了解决扩散模型在处理分布外数据时出现的问题,论文提出了自引导随机采样方法,以提高生成质量和身份保真度。
技术框架:Ani3DHuman框架主要包含以下几个阶段:1) 运动学动画生成:利用运动学方法生成人体骨骼的刚性运动。2) 粗略渲染:将刚性运动渲染成粗略的图像序列,作为扩散模型的输入。3) 自引导随机采样:使用自引导随机采样方法,利用视频扩散模型恢复残余的非刚性运动,生成高质量的视频序列。4) 非刚性运动场优化:利用生成的视频序列作为监督信号,优化残余非刚性运动场。
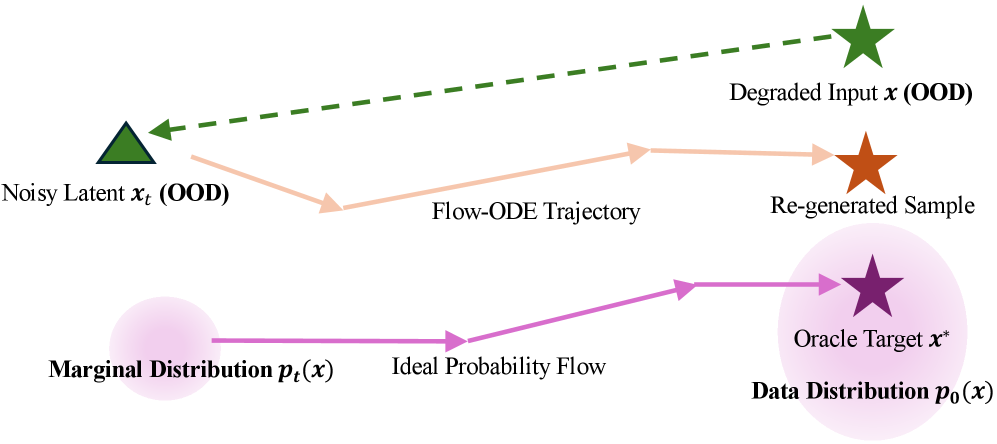
关键创新:Ani3DHuman的关键创新在于提出了自引导随机采样方法。传统的确定性ODE采样器在处理分布外数据时容易失效,而随机采样可以提高生成质量,但容易导致身份信息丢失。自引导随机采样方法通过结合随机采样和自引导,在提高生成质量的同时,保持了身份保真度。
关键设计:自引导随机采样方法的设计是关键。该方法在随机采样的基础上,引入了自引导机制,利用初始渲染图像的信息来引导采样过程,从而保证生成结果与初始渲染图像在身份信息上的一致性。具体的实现细节包括:使用噪声预测器进行随机采样,并使用初始渲染图像的特征来调整采样方向。
🖼️ 关键图片

📊 实验亮点
Ani3DHuman通过自引导随机采样方法,在生成逼真3D人体动画方面取得了显著进展。实验结果表明,该方法在视觉质量和运动细节方面均优于现有方法。作者在论文中提供了详细的实验数据和对比结果,证明了Ani3DHuman的有效性。
🎯 应用场景
Ani3DHuman技术可广泛应用于虚拟现实、增强现实、游戏开发、电影制作等领域。该技术能够生成逼真的人体动画,提升用户体验,降低内容制作成本。未来,该技术有望应用于数字人、虚拟偶像等新兴领域,推动人机交互的发展。
📄 摘要(原文)
Current 3D human animation methods struggle to achieve photorealism: kinematics-based approaches lack non-rigid dynamics (e.g., clothing dynamics), while methods that leverage video diffusion priors can synthesize non-rigid motion but suffer from quality artifacts and identity loss. To overcome these limitations, we present Ani3DHuman, a framework that marries kinematics-based animation with video diffusion priors. We first introduce a layered motion representation that disentangles rigid motion from residual non-rigid motion. Rigid motion is generated by a kinematic method, which then produces a coarse rendering to guide the video diffusion model in generating video sequences that restore the residual non-rigid motion. However, this restoration task, based on diffusion sampling, is highly challenging, as the initial renderings are out-of-distribution, causing standard deterministic ODE samplers to fail. Therefore, we propose a novel self-guided stochastic sampling method, which effectively addresses the out-of-distribution problem by combining stochastic sampling (for photorealistic quality) with self-guidance (for identity fidelity). These restored videos provide high-quality supervision, enabling the optimization of the residual non-rigid motion field. Extensive experiments demonstrate that \MethodName can generate photorealistic 3D human animation, outperforming existing methods. Code is available in https://github.com/qiisun/ani3dhuman.