TeFlow: Enabling Multi-frame Supervision for Self-Supervised Feed-forward Scene Flow Estimation
作者: Qingwen Zhang, Chenhan Jiang, Xiaomeng Zhu, Yunqi Miao, Yushan Zhang, Olov Andersson, Patric Jensfelt
分类: cs.CV, cs.RO
发布日期: 2026-02-22
备注: CVPR 2026; 15 pages, 8 figures
🔗 代码/项目: GITHUB
💡 一句话要点
TeFlow:通过时序一致性监督,提升自监督前馈场景流估计性能
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 场景流估计 自监督学习 多帧监督 时序一致性 前馈网络
📋 核心要点
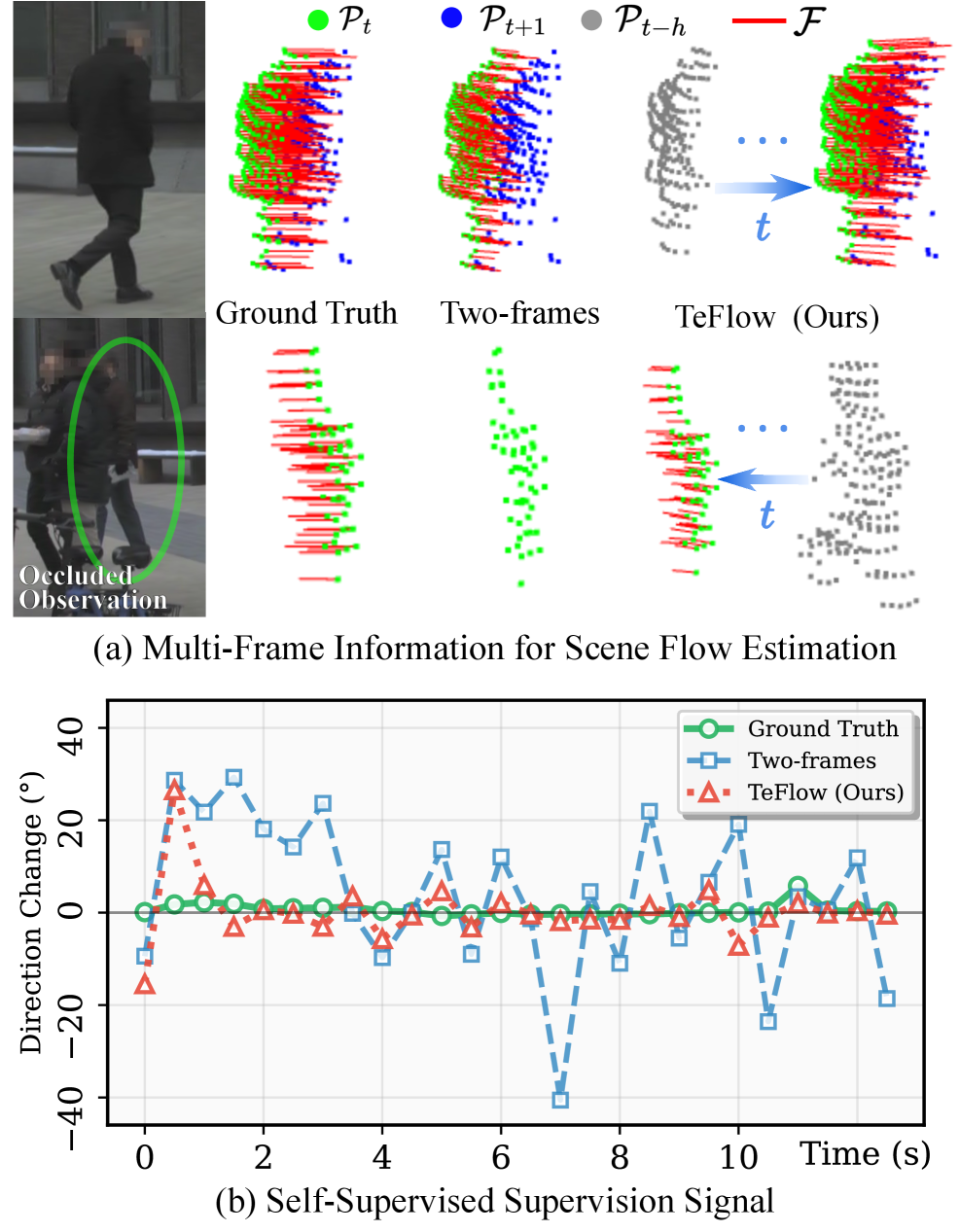
- 现有自监督前馈场景流方法依赖双帧对应,易受遮挡影响,导致监督信号不稳定。
- TeFlow通过时序集成策略,从多帧候选池中聚合时序一致的运动线索,构建可靠监督信号。
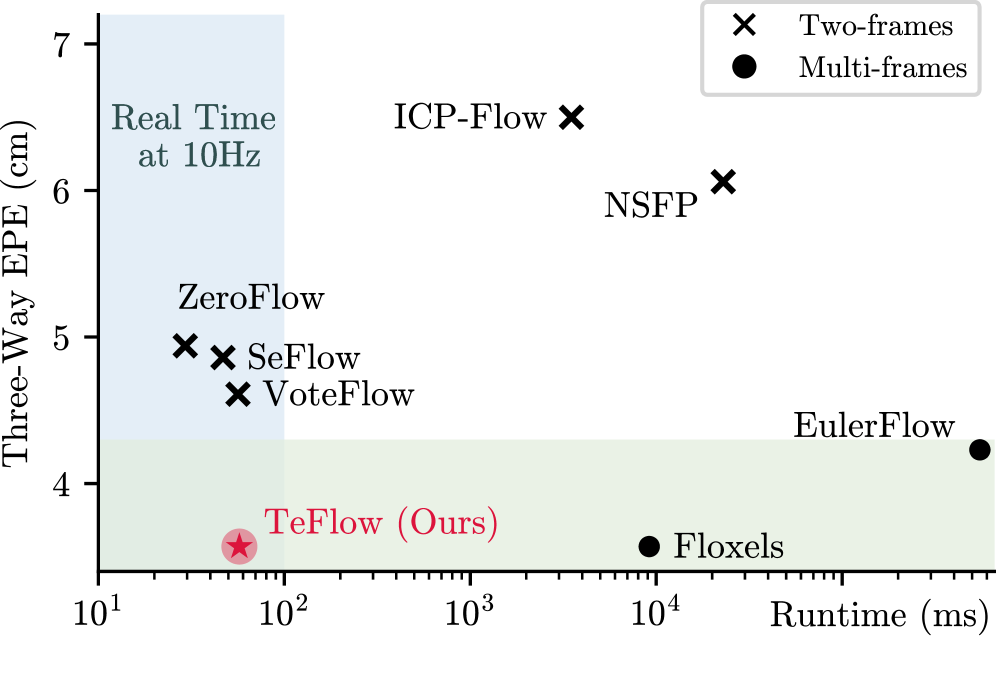
- 实验表明,TeFlow在Argoverse 2和nuScenes数据集上显著提升性能,速度远超优化方法。
📝 摘要(中文)
本文提出TeFlow,旨在为自监督前馈场景流估计模型引入多帧监督机制。现有的基于双帧点对应关系的自监督方法不够稳定,容易在遮挡情况下失效。多帧监督通过整合过去帧的运动信息,具有提供更稳定指导的潜力。然而,直接扩展双帧目标函数是无效的,因为点对应关系在不同帧之间变化剧烈,产生不一致的信号。TeFlow通过挖掘时序一致的监督信息来解决这个问题。它引入了一种时序集成策略,通过聚合来自多帧构建的候选池中最具时序一致性的运动线索,形成可靠的监督信号。在Argoverse 2和nuScenes数据集上的大量评估表明,TeFlow为自监督前馈方法建立了新的state-of-the-art,性能提升高达33%。该方法性能与领先的基于优化的方法相当,但速度提高了150倍。代码和训练好的模型权重已开源。
🔬 方法详解
问题定义:论文旨在解决自监督前馈场景流估计中,由于双帧监督信号不稳定,尤其是在遮挡情况下性能下降的问题。现有方法难以有效利用多帧信息,因为帧间点对应关系变化剧烈,导致监督信号不一致。
核心思路:TeFlow的核心思路是通过挖掘和聚合时序一致的运动线索,构建更可靠的监督信号。它认为,虽然相邻帧之间的点对应关系可能不稳定,但在较长时间范围内,仍然存在一些时序一致的运动模式。通过识别和利用这些一致的模式,可以提供更鲁棒的监督信息。
技术框架:TeFlow的技术框架主要包含以下几个阶段:1) 构建多帧候选池:从多个相邻帧中提取可能的运动线索,形成一个候选池。2) 时序一致性评估:评估候选池中每个运动线索的时序一致性,例如,通过计算其在不同帧之间的运动轨迹的平滑程度。3) 时序集成:根据时序一致性评估的结果,选择最可靠的运动线索,并将其聚合起来,形成最终的监督信号。4) 损失函数计算与模型训练:利用生成的监督信号,计算损失函数,并更新前馈场景流估计模型的参数。
关键创新:TeFlow的关键创新在于其时序集成策略,它能够有效地从多帧数据中提取时序一致的运动线索,并将其用于监督前馈场景流估计模型的训练。与现有方法相比,TeFlow不再仅仅依赖于相邻帧之间的点对应关系,而是更加关注运动模式的时序一致性,从而提高了监督信号的鲁棒性。
关键设计:TeFlow的关键设计包括:1) 时序一致性度量:如何定义和计算运动线索的时序一致性是至关重要的。论文可能采用了诸如光流一致性、运动轨迹平滑度等指标。2) 集成策略:如何将多个时序一致的运动线索聚合起来,形成最终的监督信号。论文可能采用了加权平均、选择最佳线索等方法。3) 损失函数设计:如何设计损失函数,使得模型能够有效地利用时序一致的监督信号进行训练。论文可能采用了基于光度一致性、几何一致性等原则的损失函数。
🖼️ 关键图片

📊 实验亮点
TeFlow在Argoverse 2和nuScenes数据集上取得了显著的性能提升,相较于之前的自监督前馈方法,性能提升高达33%。此外,TeFlow的性能与领先的基于优化的方法相当,但速度提高了150倍,使其更适合于实时应用。
🎯 应用场景
TeFlow在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。更准确的场景流估计可以帮助自动驾驶系统更好地理解周围环境,从而做出更安全的决策。在机器人导航中,可以帮助机器人更好地感知自身运动状态和环境变化。在增强现实中,可以实现更逼真的虚拟物体与真实场景的融合。
📄 摘要(原文)
Self-supervised feed-forward methods for scene flow estimation offer real-time efficiency, but their supervision from two-frame point correspondences is unreliable and often breaks down under occlusions. Multi-frame supervision has the potential to provide more stable guidance by incorporating motion cues from past frames, yet naive extensions of two-frame objectives are ineffective because point correspondences vary abruptly across frames, producing inconsistent signals. In the paper, we present TeFlow, enabling multi-frame supervision for feed-forward models by mining temporally consistent supervision. TeFlow introduces a temporal ensembling strategy that forms reliable supervisory signals by aggregating the most temporally consistent motion cues from a candidate pool built across multiple frames. Extensive evaluations demonstrate that TeFlow establishes a new state-of-the-art for self-supervised feed-forward methods, achieving performance gains of up to 33\% on the challenging Argoverse 2 and nuScenes datasets. Our method performs on par with leading optimization-based methods, yet speeds up 150 times. The code is open-sourced at https://github.com/KTH-RPL/OpenSceneFlow along with trained model weights.