OpenVO: Open-World Visual Odometry with Temporal Dynamics Awareness
作者: Phuc D. A. Nguyen, Anh N. Nhu, Ming C. Lin
分类: cs.CV
发布日期: 2026-02-22
备注: Main paper CVPR 2026
💡 一句话要点
OpenVO:提出一种具有时间动态感知的开放世界视觉里程计框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉里程计 开放世界 时间动态感知 单目视觉 深度学习 自动驾驶 位姿估计
📋 核心要点
- 现有视觉里程计方法忽略时间动态信息,且依赖相机内参标定,限制了其在行车记录仪等开放场景下的应用。
- OpenVO通过显式编码时间动态信息和利用3D几何先验,实现了在不同观测频率和未校准相机下的鲁棒位姿估计。
- 实验结果表明,OpenVO在多个自动驾驶数据集上显著优于现有方法,误差降低高达92%,展示了其优越的泛化能力。
📝 摘要(中文)
本文介绍了一种名为OpenVO的新型框架,用于在有限的输入条件下进行具有时间感知的开放世界视觉里程计(VO)。OpenVO能够从具有不同观测频率和未校准相机的单目行车记录仪视频中有效估计真实尺度的自我运动,从而能够从行车记录仪中记录的罕见驾驶事件中构建鲁棒的轨迹数据集。现有的VO方法在固定的观测频率(例如,10Hz或12Hz)下进行训练,完全忽略了时间动态信息。许多先前的方法还需要具有已知内部参数的校准相机。因此,当(1)部署在未知的观测频率下或(2)应用于未校准的相机时,它们的性能会下降。这些显著地限制了它们对许多下游任务(例如,从行车记录仪视频中提取轨迹)的泛化能力。为了解决这些挑战,OpenVO(1)在双帧姿态回归框架内显式地编码时间动态信息,并且(2)利用从基础模型导出的3D几何先验。我们在三个主要的自动驾驶基准测试(KITTI、nuScenes和Argoverse 2)上验证了我们的方法,与最先进的方法相比,性能提高了20%以上。在不同的观测速率设置下,我们的方法显著更鲁棒,在所有指标上的误差降低了46%-92%。这些结果证明了OpenVO在真实世界3D重建和各种下游应用中的多功能性。
🔬 方法详解
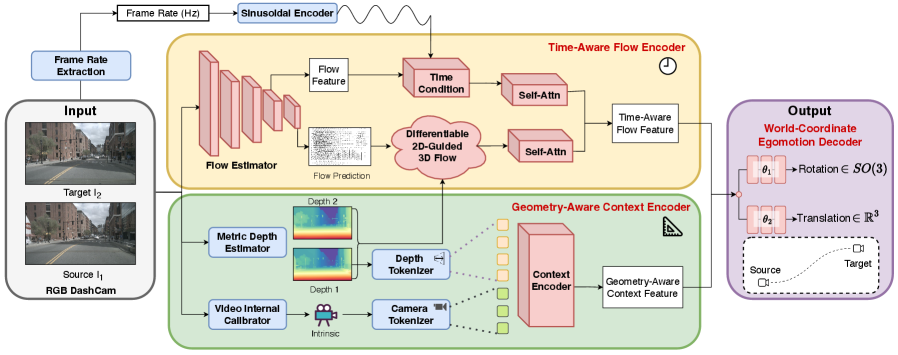
问题定义:现有视觉里程计方法通常在固定频率的图像序列上训练,忽略了时间信息,并且需要预先标定的相机参数。这使得它们难以应用于实际的开放世界场景,例如使用行车记录仪数据进行轨迹重建,因为行车记录仪的帧率可能不固定,且相机参数未知。因此,如何设计一种能够处理不同帧率和未标定相机的视觉里程计是本文要解决的问题。
核心思路:OpenVO的核心思路是显式地将时间动态信息编码到视觉里程计框架中,并利用从预训练模型中提取的3D几何先验知识来提高位姿估计的准确性和鲁棒性。通过这种方式,OpenVO能够适应不同的观测频率,并减少对相机标定信息的依赖。
技术框架:OpenVO采用双帧姿态回归框架。该框架包含以下主要模块:1) 特征提取模块,用于从连续两帧图像中提取视觉特征;2) 时间动态编码模块,用于显式地编码两帧图像之间的时间间隔信息;3) 3D几何先验模块,利用预训练模型提取的3D信息作为先验知识;4) 位姿回归模块,基于提取的特征、时间信息和3D先验,回归相机位姿变换。
关键创新:OpenVO的关键创新在于:1) 显式地编码时间动态信息,使其能够适应不同的观测频率;2) 利用从预训练模型中提取的3D几何先验知识,提高位姿估计的准确性和鲁棒性。与现有方法相比,OpenVO不需要预先标定的相机参数,并且能够更好地处理不同帧率的图像序列。
关键设计:OpenVO使用一个两帧姿态回归网络,输入是连续的两帧图像。时间动态信息通过将两帧图像之间的时间间隔作为一个输入特征添加到网络中进行编码。3D几何先验通过使用预训练的深度估计模型估计场景深度,并将深度信息作为额外的输入特征添加到网络中进行编码。损失函数包括位姿回归损失和深度一致性损失,用于约束位姿估计的准确性和深度估计的一致性。
🖼️ 关键图片
📊 实验亮点
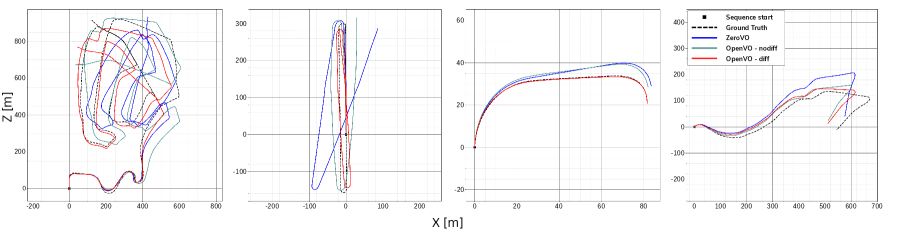
OpenVO在KITTI、nuScenes和Argoverse 2等多个自动驾驶数据集上进行了评估,结果表明其性能显著优于现有方法。具体而言,OpenVO在位姿估计精度上提升了20%以上,并且在不同观测速率下,误差降低了46%-92%。这些结果表明OpenVO具有很强的鲁棒性和泛化能力。
🎯 应用场景
OpenVO具有广泛的应用前景,包括自动驾驶、机器人导航、增强现实等领域。特别是在自动驾驶领域,OpenVO可以用于构建高精地图、进行车辆定位和路径规划。此外,OpenVO还可以应用于行车记录仪数据分析,例如提取驾驶轨迹、识别危险驾驶行为等。该研究的成果有助于推动自动驾驶和机器人技术的发展。
📄 摘要(原文)
We introduce OpenVO, a novel framework for Open-world Visual Odometry (VO) with temporal awareness under limited input conditions. OpenVO effectively estimates real-world-scale ego-motion from monocular dashcam footage with varying observation rates and uncalibrated cameras, enabling robust trajectory dataset construction from rare driving events recorded in dashcam. Existing VO methods are trained on fixed observation frequency (e.g., 10Hz or 12Hz), completely overlooking temporal dynamics information. Many prior methods also require calibrated cameras with known intrinsic parameters. Consequently, their performance degrades when (1) deployed under unseen observation frequencies or (2) applied to uncalibrated cameras. These significantly limit their generalizability to many downstream tasks, such as extracting trajectories from dashcam footage. To address these challenges, OpenVO (1) explicitly encodes temporal dynamics information within a two-frame pose regression framework and (2) leverages 3D geometric priors derived from foundation models. We validate our method on three major autonomous-driving benchmarks - KITTI, nuScenes, and Argoverse 2 - achieving more than 20 performance improvement over state-of-the-art approaches. Under varying observation rate settings, our method is significantly more robust, achieving 46%-92% lower errors across all metrics. These results demonstrate the versatility of OpenVO for real-world 3D reconstruction and diverse downstream applications.