Learning Cross-View Object Correspondence via Cycle-Consistent Mask Prediction
作者: Shannan Yan, Leqi Zheng, Keyu Lv, Jingchen Ni, Hongyang Wei, Jiajun Zhang, Guangting Wang, Jing Lyu, Chun Yuan, Fengyun Rao
分类: cs.CV
发布日期: 2026-02-22
备注: The paper has been accepted to CVPR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出循环一致掩码预测方法,解决跨视角物体对应问题
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 跨视角物体对应 循环一致性 自监督学习 视频理解 第一人称视角 第三人称视角 掩码预测
📋 核心要点
- 现有方法在跨视角物体对应任务中泛化性不足,难以适应视角差异大的场景。
- 提出循环一致掩码预测框架,利用视角转换的循环一致性约束学习视角不变的物体表示。
- 在Ego-Exo4D和HANDAL-X数据集上验证了方法的有效性,取得了state-of-the-art的结果。
📝 摘要(中文)
本文研究了视频中不同视角下物体级视觉对应关系的建立,重点关注了第一人称视角到第三人称视角以及第三人称视角到第一人称视角的场景。我们提出了一种基于条件二值分割的简单而有效的框架,其中对象查询掩码被编码成潜在表示,以指导目标视频中相应对象的定位。为了鼓励鲁棒的、视角不变的表示,我们引入了循环一致性训练目标:目标视角中预测的掩码被反向投影回源视角,以重建原始查询掩码。这种双向约束提供了一种强大的自监督信号,无需ground-truth标注,并支持推理时的测试时训练(TTT)。在Ego-Exo4D和HANDAL-X基准测试上的实验证明了我们的优化目标和TTT策略的有效性,实现了最先进的性能。
🔬 方法详解
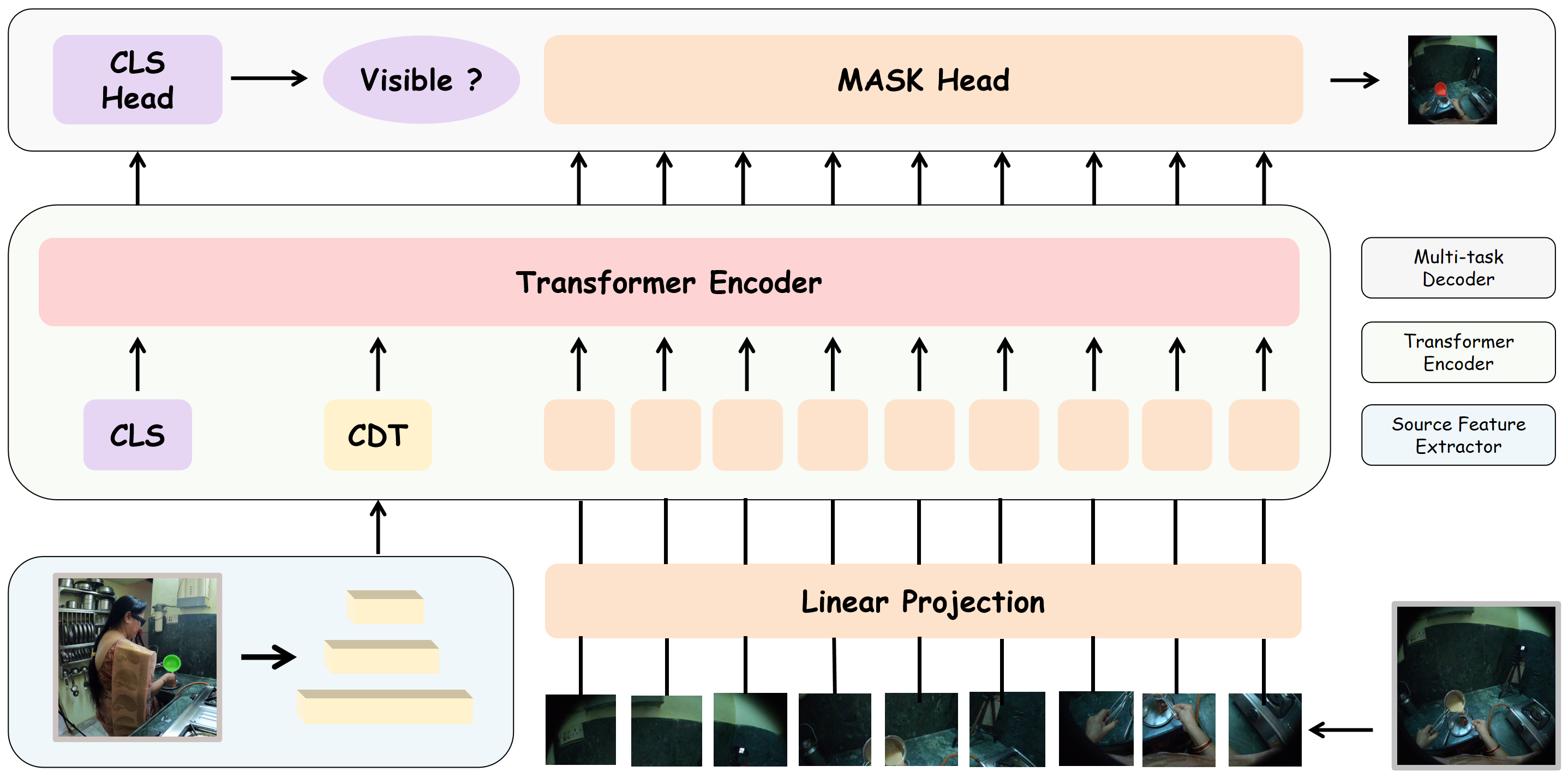
问题定义:论文旨在解决跨视角视频中物体对应关系的建立问题,尤其关注第一人称视角和第三人称视角之间的对应。现有方法通常依赖大量标注数据,且在视角差异较大时性能下降,缺乏鲁棒性和泛化能力。
核心思路:论文的核心思路是利用循环一致性约束来学习视角不变的物体表示。具体来说,给定一个视角的物体掩码,模型预测其在另一个视角中的对应掩码,然后将预测的掩码反向投影回原始视角,并与原始掩码进行比较。通过最小化重构误差,模型可以学习到对视角变化具有鲁棒性的物体表示。
技术框架:整体框架包含以下几个主要模块:1) 特征提取器:用于提取源视角和目标视角的视频帧特征。2) 掩码编码器:将源视角的物体掩码编码成一个潜在表示。3) 掩码预测器:利用编码后的潜在表示和目标视角的视频帧特征,预测目标视角中对应物体的掩码。4) 掩码反向投影模块:将预测的掩码反向投影回源视角。5) 循环一致性损失:计算原始掩码和反向投影掩码之间的差异,作为训练的损失函数。
关键创新:该方法最重要的创新点在于引入了循环一致性约束,这是一种自监督学习方法,无需人工标注的对应关系。通过循环一致性,模型可以学习到视角不变的物体表示,从而提高跨视角物体对应任务的性能。此外,论文还提出了测试时训练(TTT)策略,进一步提升了模型的泛化能力。
关键设计:在具体实现上,掩码编码器和掩码预测器可以使用卷积神经网络或Transformer结构。循环一致性损失可以使用Dice Loss或交叉熵损失。测试时训练(TTT)策略通过在测试阶段对模型进行微调,以适应特定的测试场景。具体的网络结构和参数设置需要在实验中进行调整和优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在Ego-Exo4D和HANDAL-X数据集上取得了state-of-the-art的性能。与现有方法相比,该方法在跨视角物体对应任务中具有更高的准确性和鲁棒性。循环一致性损失和测试时训练(TTT)策略显著提升了模型的泛化能力。
🎯 应用场景
该研究成果可应用于机器人导航、增强现实、视频监控等领域。例如,在机器人导航中,机器人可以通过第一人称视角观察物体,并利用该方法在第三人称视角的地图中定位该物体。在增强现实中,可以将虚拟物体与不同视角的真实场景进行对齐。在视频监控中,可以实现跨摄像头的物体追踪。
📄 摘要(原文)
We study the task of establishing object-level visual correspondence across different viewpoints in videos, focusing on the challenging egocentric-to-exocentric and exocentric-to-egocentric scenarios. We propose a simple yet effective framework based on conditional binary segmentation, where an object query mask is encoded into a latent representation to guide the localization of the corresponding object in a target video. To encourage robust, view-invariant representations, we introduce a cycle-consistency training objective: the predicted mask in the target view is projected back to the source view to reconstruct the original query mask. This bidirectional constraint provides a strong self-supervisory signal without requiring ground-truth annotations and enables test-time training (TTT) at inference. Experiments on the Ego-Exo4D and HANDAL-X benchmarks demonstrate the effectiveness of our optimization objective and TTT strategy, achieving state-of-the-art performance. The code is available at https://github.com/shannany0606/CCMP.