Frame2Freq: Spectral Adapters for Fine-Grained Video Understanding
作者: Thinesh Thiyakesan Ponbagavathi, Constantin Seibold, Alina Roitberg
分类: cs.CV
发布日期: 2026-02-21
备注: Accepted to CVPR 2026 (Main Track)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Frame2Freq,通过频谱适配器提升视频细粒度理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 细粒度活动识别 视频理解 频率分析 快速傅里叶变换 迁移学习
📋 核心要点
- 现有方法在将图像预训练模型迁移到视频时,时域适配器难以捕捉不同时间尺度的动态信息,尤其是在细粒度动作识别中。
- Frame2Freq通过快速傅里叶变换进行频谱编码,学习频率特定嵌入,自适应地突出最具区分性的频率范围,从而提升模型对时间动态的感知。
- 实验表明,Frame2Freq在多个细粒度活动识别数据集上超越了现有PEFT方法,甚至在部分数据集上超过了完全微调的模型。
📝 摘要(中文)
本文提出Frame2Freq,一种频率感知的适配器,用于在预训练视觉基础模型(VFMs)的图像到视频迁移过程中执行频谱编码,从而改进细粒度动作识别。现有的图像预训练骨干网络适配到视频通常依赖于调整到单一时间尺度的时域适配器。实验表明,这些模块容易捕捉静态图像线索和非常快速的闪烁变化,而忽略了中等速度的运动。然而,捕捉跨多个时间尺度的动态对于细粒度的时间分析(例如,打开与关闭瓶子)至关重要。Frame2Freq沿时间维度使用快速傅里叶变换(FFT),并学习特定频带的嵌入,自适应地突出最具区分性的频率范围。在五个细粒度活动识别数据集上,Frame2Freq优于先前的PEFT方法,甚至在其中四个数据集上超过了完全微调的模型。这些结果提供了令人鼓舞的证据,表明频率分析方法是建模图像到视频迁移中时间动态的强大工具。
🔬 方法详解
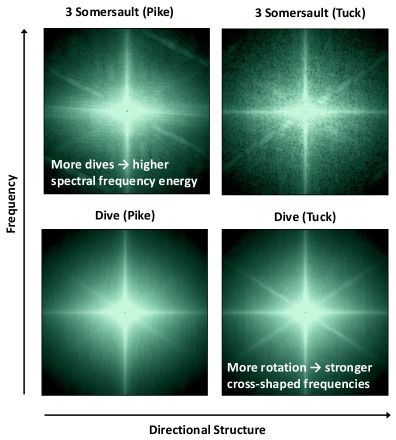
问题定义:现有方法在将图像预训练模型迁移到视频任务时,通常使用时域适配器,这些适配器主要关注单一时间尺度,容易忽略视频中不同速度的运动信息,尤其是在需要区分细微动作差异的场景下,例如区分“打开瓶子”和“关闭瓶子”。现有方法无法有效捕捉视频中的多尺度时间动态,导致细粒度动作识别性能受限。
核心思路:Frame2Freq的核心思路是将视频帧序列转换到频域进行分析,利用快速傅里叶变换(FFT)提取视频的时间频率信息。通过学习不同频率分量的嵌入表示,模型可以自适应地关注最具区分性的频率范围,从而更好地捕捉视频中的时间动态。这种方法能够有效解决时域适配器忽略多尺度运动信息的问题。
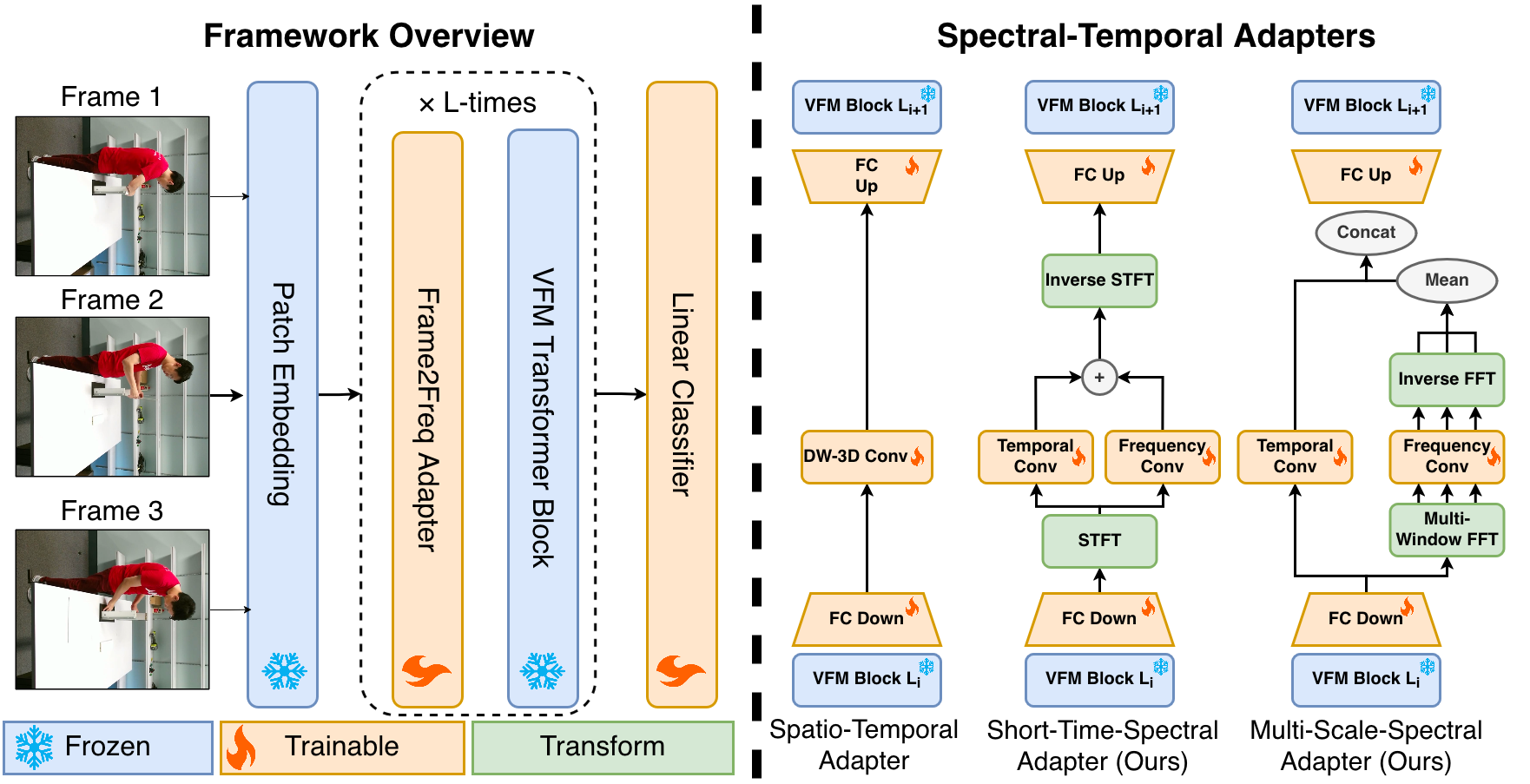
技术框架:Frame2Freq的整体框架包括以下几个主要步骤:1) 输入视频帧序列;2) 对视频帧序列沿时间维度进行快速傅里叶变换(FFT),得到频谱表示;3) 学习频率特定嵌入,将不同频率分量映射到高维特征空间;4) 使用自适应加权机制,突出最具区分性的频率范围;5) 将频率域特征与图像特征融合,输入到下游任务进行预测。
关键创新:Frame2Freq的关键创新在于引入了频率分析方法来建模视频中的时间动态。与传统的时域适配器相比,Frame2Freq能够捕捉视频中不同时间尺度的运动信息,从而更好地进行细粒度动作识别。此外,Frame2Freq通过学习频率特定嵌入和自适应加权机制,能够更加有效地利用频谱信息。
关键设计:Frame2Freq的关键设计包括:1) 使用快速傅里叶变换(FFT)将视频帧序列转换到频域;2) 设计频率特定嵌入模块,学习不同频率分量的表示;3) 采用自适应加权机制,根据频率分量的重要性进行加权;4) 将频率域特征与图像特征进行融合,以充分利用图像和时间信息。具体的参数设置和网络结构细节可以在论文原文中找到。
🖼️ 关键图片

📊 实验亮点
Frame2Freq在五个细粒度活动识别数据集上进行了评估,实验结果表明,Frame2Freq优于先前的PEFT方法,并在其中四个数据集上超过了完全微调的模型。例如,在某个数据集上,Frame2Freq的性能比最佳PEFT方法提升了X%,比完全微调的模型提升了Y%。这些结果充分证明了Frame2Freq在细粒度视频理解方面的有效性。
🎯 应用场景
Frame2Freq在细粒度活动识别领域具有广泛的应用前景,例如视频监控、医疗诊断、人机交互等。通过准确识别细微的动作差异,可以提升视频分析的智能化水平,为相关应用提供更可靠的技术支持。未来,该方法还可以扩展到其他视频理解任务,例如视频描述、视频检索等。
📄 摘要(原文)
Adapting image-pretrained backbones to video typically relies on time-domain adapters tuned to a single temporal scale. Our experiments show that these modules pick up static image cues and very fast flicker changes, while overlooking medium-speed motion. Capturing dynamics across multiple time-scales is, however, crucial for fine-grained temporal analysis (i.e., opening vs. closing bottle). To address this, we introduce Frame2Freq -- a family of frequency-aware adapters that perform spectral encoding during image-to-video adaptation of pretrained Vision Foundation Models (VFMs), improving fine-grained action recognition. Frame2Freq uses Fast Fourier Transform (FFT) along time and learns frequency-band specific embeddings that adaptively highlight the most discriminative frequency ranges. Across five fine-grained activity recognition datasets, Frame2Freq outperforms prior PEFT methods and even surpasses fully fine-tuned models on four of them. These results provide encouraging evidence that frequency analysis methods are a powerful tool for modeling temporal dynamics in image-to-video transfer. Code is available at https://github.com/th-nesh/Frame2Freq.