Global Commander and Local Operative: A Dual-Agent Framework for Scene Navigation
作者: Kaiming Jin, Yuefan Wu, Shengqiong Wu, Bobo Li, Shuicheng Yan, Tat-Seng Chua
分类: cs.CV
发布日期: 2026-02-21
备注: 18 pages, 9 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出DACo双智能体框架,解耦全局规划与局部执行,提升场景导航性能。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 场景导航 视觉语言导航 双智能体 解耦架构 长时程规划
📋 核心要点
- 现有场景导航方法面临协调成本高或智能体认知过载的挑战,影响长时程导航性能。
- DACo框架解耦全局规划与局部执行,通过双智能体协同减轻认知负担,提升导航稳定性。
- 实验表明,DACo在多个数据集上显著优于现有方法,并能有效泛化到不同骨干网络。
📝 摘要(中文)
本文提出了一种用于视觉-语言场景导航的双智能体框架DACo,旨在解决现有方法中存在的协调成本高或智能体认知过载问题。DACo采用规划-执行解耦的架构,利用全局指挥者进行高层战略规划,局部执行者进行以自我为中心的观察和精细执行。通过解耦全局推理和局部动作,DACo减轻了认知负担并提高了长时程导航的稳定性。该框架还集成了动态子目标规划和自适应重规划,以实现结构化和鲁棒的导航。在R2R、REVERIE和R4R上的大量评估表明,DACo在零样本设置下,相对于最佳基线分别实现了4.9%、6.5%、5.4%的绝对性能提升,并且能够有效地泛化到闭源(如GPT-4o)和开源(如Qwen-VL系列)骨干网络。DACo为鲁棒的长时程导航提供了一个原则性和可扩展的范例。
🔬 方法详解
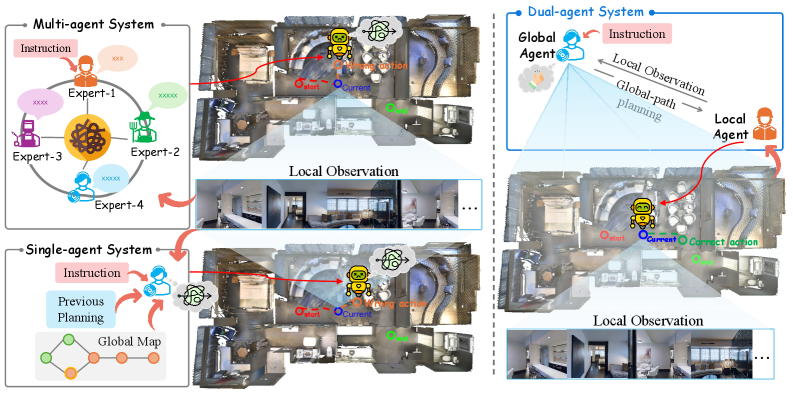
问题定义:视觉-语言场景导航任务要求智能体根据自然语言指令在复杂环境中执行连贯的动作序列。现有方法要么依赖多个智能体,导致协调和资源成本高昂,要么采用单智能体范式,使智能体同时承担全局规划和局部感知,导致推理能力下降和长时程导航中的指令漂移。
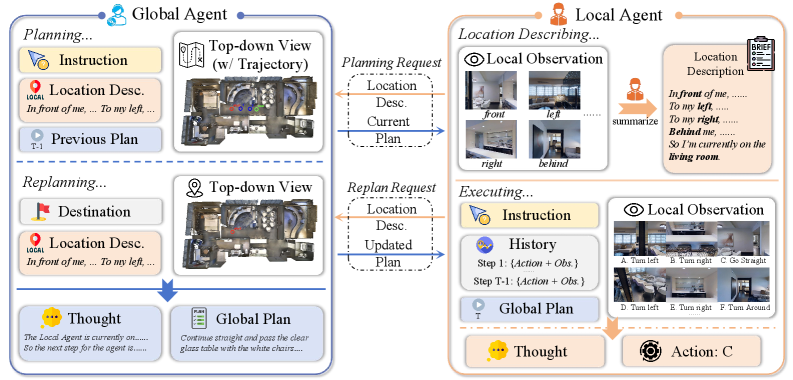
核心思路:DACo的核心思路是将全局战略规划与局部精细执行解耦,分别由全局指挥者(Global Commander)和局部执行者(Local Operative)承担。全局指挥者负责高层决策和子目标规划,局部执行者负责感知环境和执行具体动作。这种解耦可以减轻智能体的认知负担,提高长时程导航的稳定性和鲁棒性。
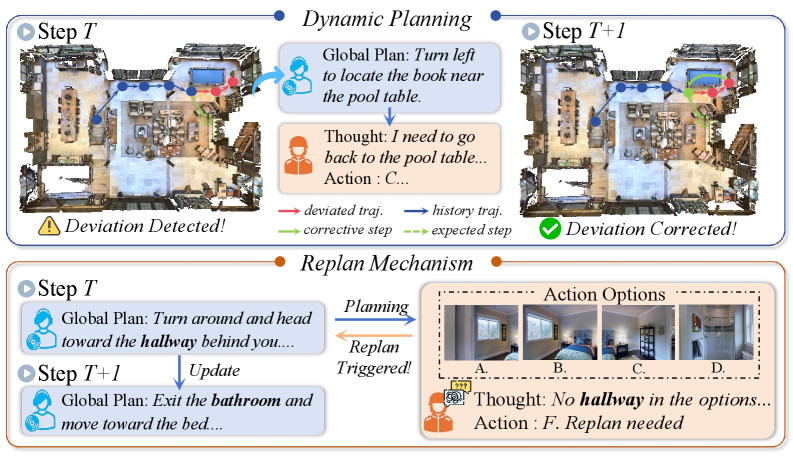
技术框架:DACo框架包含全局指挥者和局部执行者两个模块。全局指挥者接收语言指令和环境信息,进行高层战略规划,生成一系列子目标。局部执行者以自我为中心观察环境,根据全局指挥者设定的子目标,执行精细的动作序列。框架还包含动态子目标规划和自适应重规划机制,允许智能体在导航过程中根据实际情况调整子目标和行动计划。
关键创新:DACo的关键创新在于双智能体架构和规划-执行解耦的设计。与单智能体方法相比,DACo能够更有效地处理复杂环境和长时程指令。与多智能体方法相比,DACo避免了复杂的协调机制,降低了资源消耗。动态子目标规划和自适应重规划机制进一步提高了导航的鲁棒性。
关键设计:全局指挥者和局部执行者可以使用不同的模型架构。例如,全局指挥者可以使用大型语言模型(LLM)进行高层推理和规划,局部执行者可以使用卷积神经网络(CNN)或Transformer网络进行视觉感知和动作预测。损失函数的设计需要考虑全局规划和局部执行的协同,例如可以使用强化学习方法训练局部执行者,使其更好地完成全局指挥者设定的子目标。
🖼️ 关键图片
📊 实验亮点
DACo在R2R、REVERIE和R4R数据集上进行了广泛的评估,结果表明,DACo在零样本设置下,相对于最佳基线分别实现了4.9%、6.5%、5.4%的绝对性能提升。此外,DACo能够有效地泛化到闭源(如GPT-4o)和开源(如Qwen-VL系列)骨干网络,证明了其良好的泛化能力和可扩展性。
🎯 应用场景
DACo框架可应用于机器人导航、虚拟助手、智能家居等领域。例如,在机器人导航中,DACo可以帮助机器人在复杂环境中根据人类指令完成任务。在虚拟助手中,DACo可以帮助用户在虚拟环境中进行探索和交互。在智能家居中,DACo可以帮助智能设备理解用户的意图并执行相应的操作。该研究为构建更智能、更可靠的具身智能体奠定了基础。
📄 摘要(原文)
Vision-and-Language Scene navigation is a fundamental capability for embodied human-AI collaboration, requiring agents to follow natural language instructions to execute coherent action sequences in complex environments. Existing approaches either rely on multiple agents, incurring high coordination and resource costs, or adopt a single-agent paradigm, which overloads the agent with both global planning and local perception, often leading to degraded reasoning and instruction drift in long-horizon settings. To address these issues, we introduce DACo, a planning-grounding decoupled architecture that disentangles global deliberation from local grounding. Concretely, it employs a Global Commander for high-level strategic planning and a Local Operative for egocentric observing and fine-grained execution. By disentangling global reasoning from local action, DACo alleviates cognitive overload and improves long-horizon stability. The framework further integrates dynamic subgoal planning and adaptive replanning to enable structured and resilient navigation. Extensive evaluations on R2R, REVERIE, and R4R demonstrate that DACo achieves 4.9%, 6.5%, 5.4% absolute improvements over the best-performing baselines in zero-shot settings, and generalizes effectively across both closed-source (e.g., GPT-4o) and open-source (e.g., Qwen-VL Series) backbones. DACo provides a principled and extensible paradigm for robust long-horizon navigation. Project page: https://github.com/ChocoWu/DACo