Beyond Stationarity: Rethinking Codebook Collapse in Vector Quantization
作者: Hao Lu, Onur C. Koyun, Yongxin Guo, Zhengjie Zhu, Abbas Alili, Metin Nafi Gurcan
分类: cs.CV
发布日期: 2026-02-21
💡 一句话要点
针对向量量化中码本崩溃问题,提出非平稳向量量化和Transformer向量量化方法
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 向量量化 码本崩溃 非平稳性 生成模型 Transformer 图像重建 自编码器
📋 核心要点
- 向量量化(VQ)存在码本崩溃问题,即大量码向量在训练中未被使用,影响模型性能。
- 论文提出非平稳向量量化(NSVQ)和Transformer向量量化(TransVQ),解决编码器漂移导致的码本崩溃问题。
- 实验表明,新方法在CelebA-HQ数据集上实现了近乎完整的码本利用率和更高的重建质量。
📝 摘要(中文)
向量量化(VQ)是VQ-VAE、VQ-GAN和潜在扩散模型等现代生成框架的基础。然而,它一直受到码本崩溃问题的困扰,即在训练过程中,大部分码向量都未被使用。本文通过将编码器更新的非平稳性确定为该现象的根本原因,提供了一种新的理论解释。我们证明,随着编码器的漂移,未被选择的码向量无法接收到更新,并逐渐变得不活跃。为了解决这个问题,我们提出了两种新方法:非平稳向量量化(NSVQ),它通过基于核的规则将编码器漂移传播到未被选择的代码;以及基于Transformer的向量量化(TransVQ),它采用轻量级映射来自适应地转换整个码本,同时保持收敛到k-means解决方案。在CelebA-HQ数据集上的实验表明,与基线VQ变体相比,这两种方法都实现了接近完整的码本利用率和卓越的重建质量,为未来基于VQ的生成模型提供了原则性和可扩展的基础。
🔬 方法详解
问题定义:向量量化中的码本崩溃问题是指在训练过程中,只有少数码向量被频繁使用,而大部分码向量几乎没有被用到,导致码本利用率低,模型表达能力受限。现有方法难以有效解决由于编码器更新导致的码本向量利用不均衡问题。
核心思路:论文的核心思路是认识到编码器更新的非平稳性是导致码本崩溃的根本原因。随着编码器的更新,未被选择的码向量无法及时更新,逐渐失去代表性,从而导致码本崩溃。因此,需要设计方法来应对编码器漂移,保持码本的有效性。
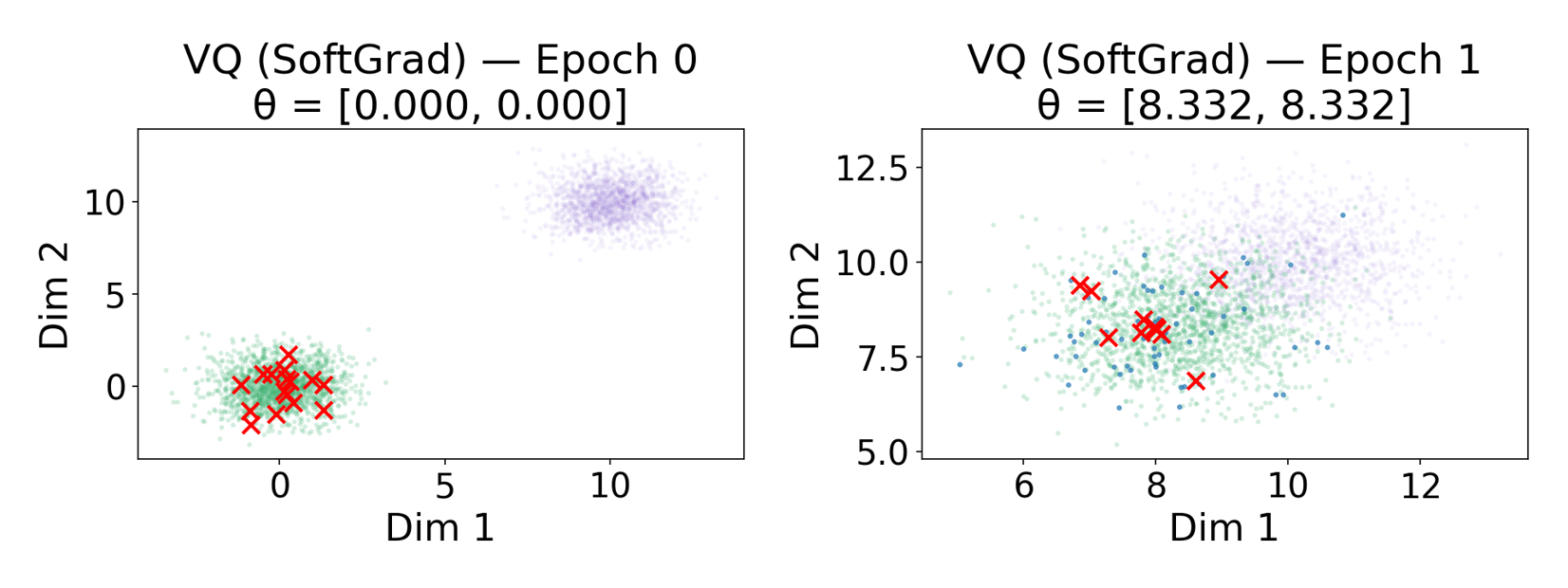
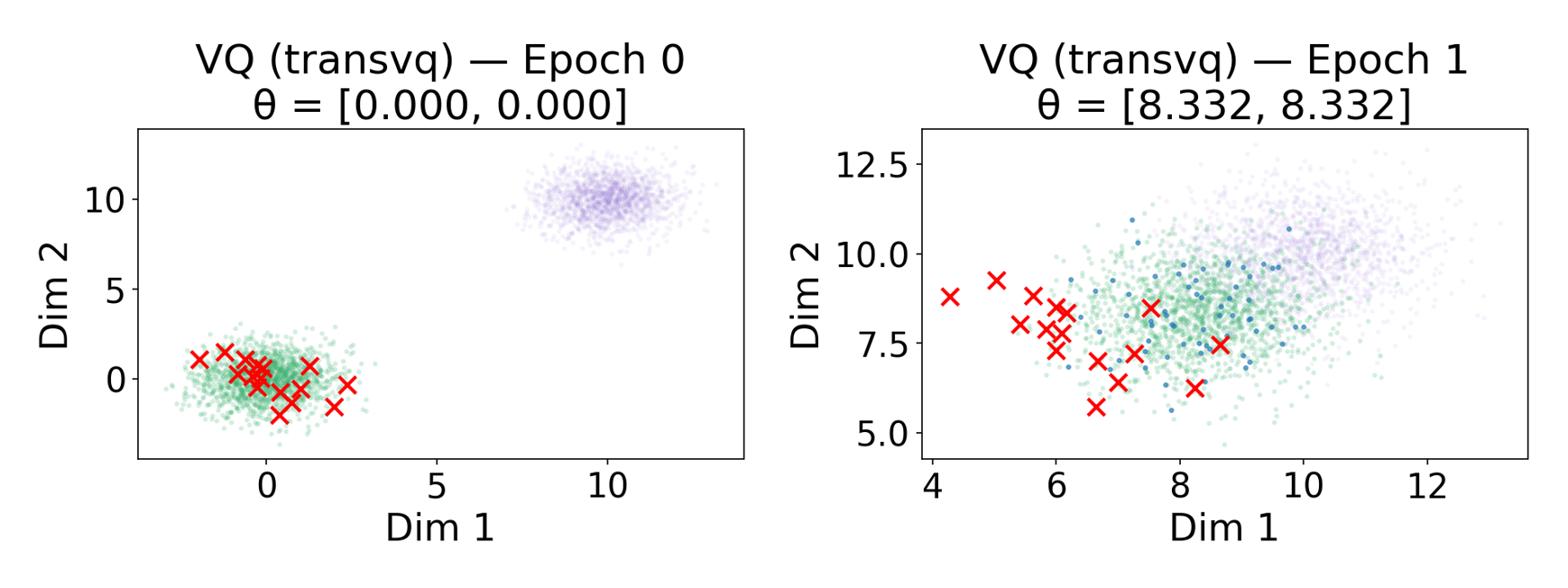
技术框架:论文提出了两种方法:NSVQ和TransVQ。NSVQ通过核函数将编码器漂移信息传播到未被选择的码向量,使其能够跟随编码器的变化进行更新。TransVQ则使用一个轻量级的Transformer网络来动态调整整个码本,使其适应编码器的输出分布。两种方法都旨在提高码本的利用率,避免码本崩溃。
关键创新:论文的关键创新在于将编码器更新的非平稳性与码本崩溃联系起来,并提出了相应的解决方案。NSVQ通过核函数传播编码器漂移,是一种简单有效的策略。TransVQ则利用Transformer的强大表示能力,自适应地调整码本,是一种更灵活的方法。
关键设计:NSVQ的关键设计在于核函数的选择和参数设置,核函数决定了编码器漂移信息如何传播到未被选择的码向量。TransVQ的关键设计在于Transformer网络的结构和训练方式,需要保证Transformer能够有效地学习码本的动态调整策略,同时保持收敛性。损失函数通常包括重建损失和码本利用率相关的损失项。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NSVQ和TransVQ在CelebA-HQ数据集上显著提高了码本利用率,接近完全利用。与基线VQ变体相比,两种方法都取得了更高的重建质量,证明了其有效性。具体性能数据可在论文原文中找到。
🎯 应用场景
该研究成果可应用于图像生成、视频生成、音频生成等领域,尤其是在需要高质量和多样性的生成任务中。通过提高码本利用率,可以提升生成模型的表达能力和生成质量,例如在图像编辑、风格迁移、超分辨率重建等任务中具有潜在的应用价值。
📄 摘要(原文)
Vector Quantization (VQ) underpins many modern generative frameworks such as VQ-VAE, VQ-GAN, and latent diffusion models. Yet, it suffers from the persistent problem of codebook collapse, where a large fraction of code vectors remains unused during training. This work provides a new theoretical explanation by identifying the nonstationary nature of encoder updates as the fundamental cause of this phenomenon. We show that as the encoder drifts, unselected code vectors fail to receive updates and gradually become inactive. To address this, we propose two new methods: Non-Stationary Vector Quantization (NSVQ), which propagates encoder drift to non-selected codes through a kernel-based rule, and Transformer-based Vector Quantization (TransVQ), which employs a lightweight mapping to adaptively transform the entire codebook while preserving convergence to the k-means solution. Experiments on the CelebA-HQ dataset demonstrate that both methods achieve near-complete codebook utilization and superior reconstruction quality compared to baseline VQ variants, providing a principled and scalable foundation for future VQ-based generative models. The code is available at: https://github.com/CAIR- LAB- WFUSM/NSVQ-TransVQ.git