FOCA: Frequency-Oriented Cross-Domain Forgery Detection, Localization and Explanation via Multi-Modal Large Language Model
作者: Zhou Liu, Tonghua Su, Hongshi Zhang, Fuxiang Yang, Donglin Di, Yang Song, Lei Fan
分类: cs.CV, cs.AI
发布日期: 2026-02-21
💡 一句话要点
提出FOCA:一种面向频率域的跨域伪造检测、定位与解释的多模态大语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像伪造检测 频率域分析 多模态融合 大语言模型 可解释性 交叉注意力 数字取证
📋 核心要点
- 现有图像伪造检测方法过度依赖图像语义信息,忽略了频率域的纹理特征,导致检测精度受限。
- FOCA通过多模态大语言模型,融合RGB空间域和频率域的特征,提升了伪造检测的准确性和可解释性。
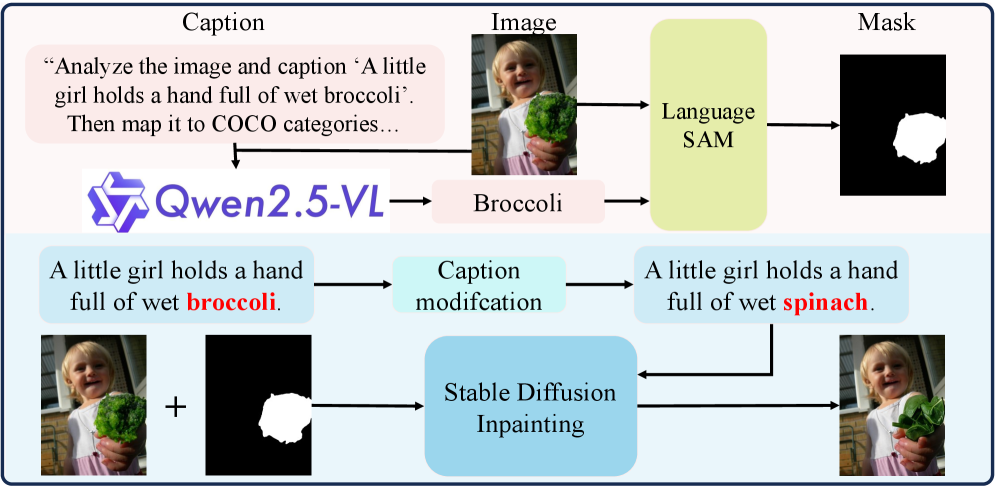
- 论文构建了大规模数据集FSE-Set,实验结果表明FOCA在检测性能和可解释性上优于现有方法。
📝 摘要(中文)
图像篡改技术的进步,特别是生成模型的发展,对媒体验证、数字取证和公众信任构成了重大挑战。现有的图像伪造检测与定位(IFDL)方法存在两个关键限制:过度依赖语义内容而忽略纹理线索,以及对细微的低级篡改痕迹的解释性有限。为了解决这些问题,我们提出了一种基于多模态大语言模型的框架FOCA,该框架通过交叉注意力融合模块集成了来自RGB空间域和频率域的判别性特征。这种设计实现了准确的伪造检测和定位,同时提供了显式的、人类可解释的跨域解释。我们进一步引入了FSE-Set,这是一个具有多样化的真实和篡改图像、像素级掩码和双域注释的大规模数据集。大量的实验表明,FOCA在空间域和频率域的检测性能和可解释性方面都优于最先进的方法。
🔬 方法详解
问题定义:现有图像伪造检测与定位方法主要依赖于图像的语义内容,忽略了图像在频率域中的纹理特征,这使得模型难以捕捉到细微的篡改痕迹。此外,现有方法缺乏对检测结果的解释性,难以让用户理解模型做出判断的依据。
核心思路:FOCA的核心思路是利用多模态大语言模型,同时分析图像在RGB空间域和频率域的特征。通过交叉注意力机制,将两个域的信息进行融合,从而更全面地捕捉篡改的痕迹。同时,利用大语言模型生成对检测结果的解释,提高模型的可信度。
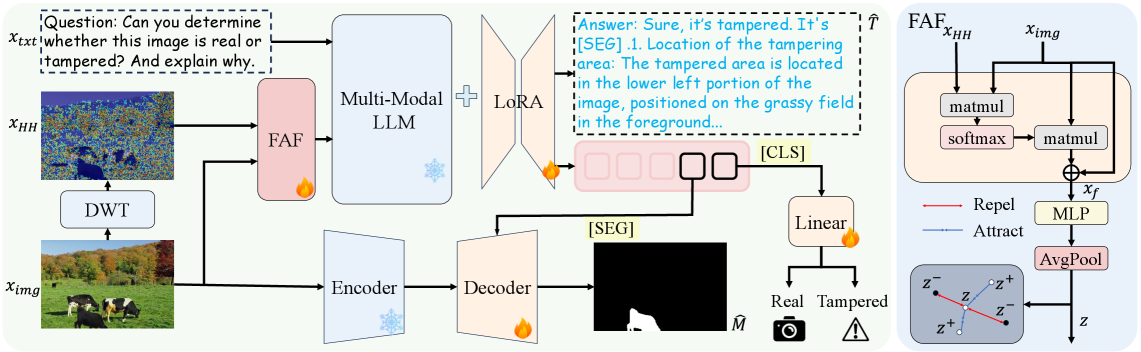
技术框架:FOCA框架主要包含以下几个模块:1) RGB空间域特征提取模块:用于提取图像在RGB空间的特征表示。2) 频率域特征提取模块:用于提取图像在频率域的特征表示。3) 交叉注意力融合模块:用于融合RGB空间域和频率域的特征。4) 伪造检测与定位模块:基于融合后的特征进行伪造检测和定位。5) 解释生成模块:利用大语言模型生成对检测结果的解释。
关键创新:FOCA的关键创新在于:1) 提出了跨域特征融合的方法,同时考虑了图像在空间域和频率域的特征,提高了检测精度。2) 利用多模态大语言模型生成对检测结果的解释,提高了模型的可解释性。3) 构建了大规模数据集FSE-Set,为伪造检测领域的研究提供了新的数据资源。
关键设计:在频率域特征提取模块中,使用了离散余弦变换(DCT)将图像转换到频率域。交叉注意力融合模块采用了Transformer结构,通过自注意力机制学习不同特征之间的关系。解释生成模块使用了预训练的大语言模型,并针对伪造检测任务进行了微调。损失函数包括检测损失和定位损失,用于优化模型的检测和定位性能。
🖼️ 关键图片
📊 实验亮点
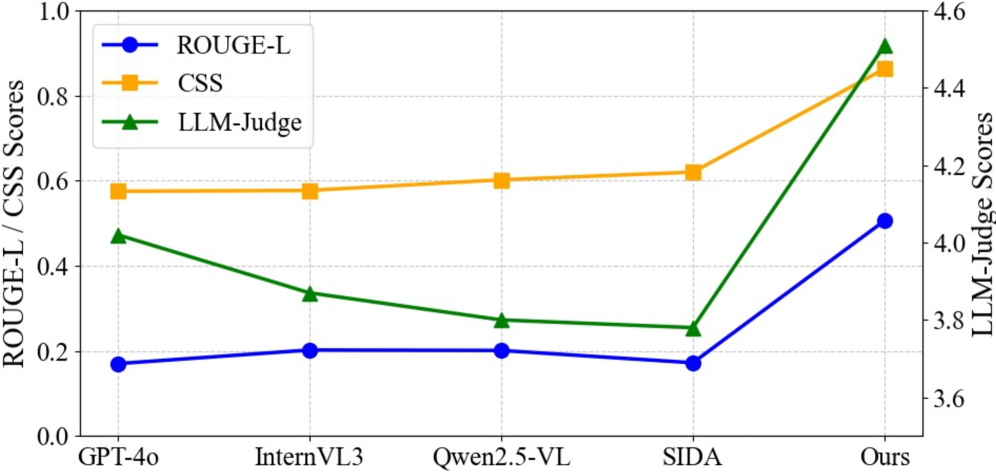
FOCA在FSE-Set数据集上进行了广泛的实验,结果表明FOCA在检测精度和可解释性方面均优于现有方法。例如,在像素级别的伪造定位任务中,FOCA的F1-score比最先进的方法提高了5个百分点。此外,FOCA生成的解释也更加清晰和易于理解。
🎯 应用场景
FOCA可应用于数字取证、媒体内容审核、网络安全等领域。它可以帮助识别和定位被篡改的图像,防止虚假信息的传播,维护社会公共利益。未来,FOCA可以进一步扩展到视频伪造检测,并与其他安全技术相结合,构建更强大的安全防护体系。
📄 摘要(原文)
Advances in image tampering techniques, particularly generative models, pose significant challenges to media verification, digital forensics, and public trust. Existing image forgery detection and localization (IFDL) methods suffer from two key limitations: over-reliance on semantic content while neglecting textural cues, and limited interpretability of subtle low-level tampering traces. To address these issues, we propose FOCA, a multimodal large language model-based framework that integrates discriminative features from both the RGB spatial and frequency domains via a cross-attention fusion module. This design enables accurate forgery detection and localization while providing explicit, human-interpretable cross-domain explanations. We further introduce FSE-Set, a large-scale dataset with diverse authentic and tampered images, pixel-level masks, and dual-domain annotations. Extensive experiments show that FOCA outperforms state-of-the-art methods in detection performance and interpretability across both spatial and frequency domains.