TIACam: Text-Anchored Invariant Feature Learning with Auto-Augmentation for Camera-Robust Zero-Watermarking
作者: Abdullah All Tanvir, Agnibh Dasgupta, Xin Zhong
分类: eess.IV, cs.CV, cs.LG, cs.MM
发布日期: 2026-02-21
备注: This paper is accepted to CVPR 2026
💡 一句话要点
TIACam提出了一种文本锚定的不变特征学习框架,用于提升相机拍摄鲁棒性的零水印技术。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零水印 相机鲁棒性 不变特征学习 自动增强 跨模态学习
📋 核心要点
- 现有深度水印系统难以应对相机重捕获引入的复杂光学退化,如透视扭曲和光照变化。
- TIACam通过自动增强学习相机失真,并利用文本锚定实现图像特征的语义一致性,提升水印鲁棒性。
- 实验表明,TIACam在特征稳定性和水印提取精度方面均达到了最先进水平,有效提升了相机鲁棒性。
📝 摘要(中文)
相机重捕获引入了复杂的光学退化,如透视扭曲、光照变化和莫尔干涉,这对深度水印系统提出了挑战。本文提出了TIACam,一个文本锚定的不变特征学习框架,结合自动增强技术,用于相机鲁棒的零水印。该方法集成了三个关键创新:(1)一个可学习的自动增强器,通过可微分的几何、光度和莫尔算子发现类似相机的失真;(2)一个文本锚定的不变特征学习器,通过图像和文本之间的跨模态对抗对齐来强制语义一致性;(3)一个零水印头,在不变特征空间中绑定二进制消息,而不修改图像像素。这种统一的公式共同优化了不变性、语义对齐和水印可恢复性。在合成和真实相机拍摄上的大量实验表明,TIACam实现了最先进的特征稳定性和水印提取精度,为多模态不变性学习和物理鲁棒的零水印之间建立了一个原则性的桥梁。
🔬 方法详解
问题定义:论文旨在解决相机重捕获场景下,零水印技术鲁棒性不足的问题。现有方法难以抵抗相机引入的透视扭曲、光照变化和莫尔干涉等复杂光学退化,导致水印提取失败。因此,如何在相机拍摄条件下保持水印的可靠性和隐蔽性是本研究的核心问题。
核心思路:论文的核心思路是学习对相机失真具有不变性的图像特征,并利用文本信息作为语义锚点,增强特征的语义一致性。通过自动增强模拟相机失真,并采用跨模态对抗学习,使得图像特征在不同相机条件下保持稳定,从而提高水印的鲁棒性。
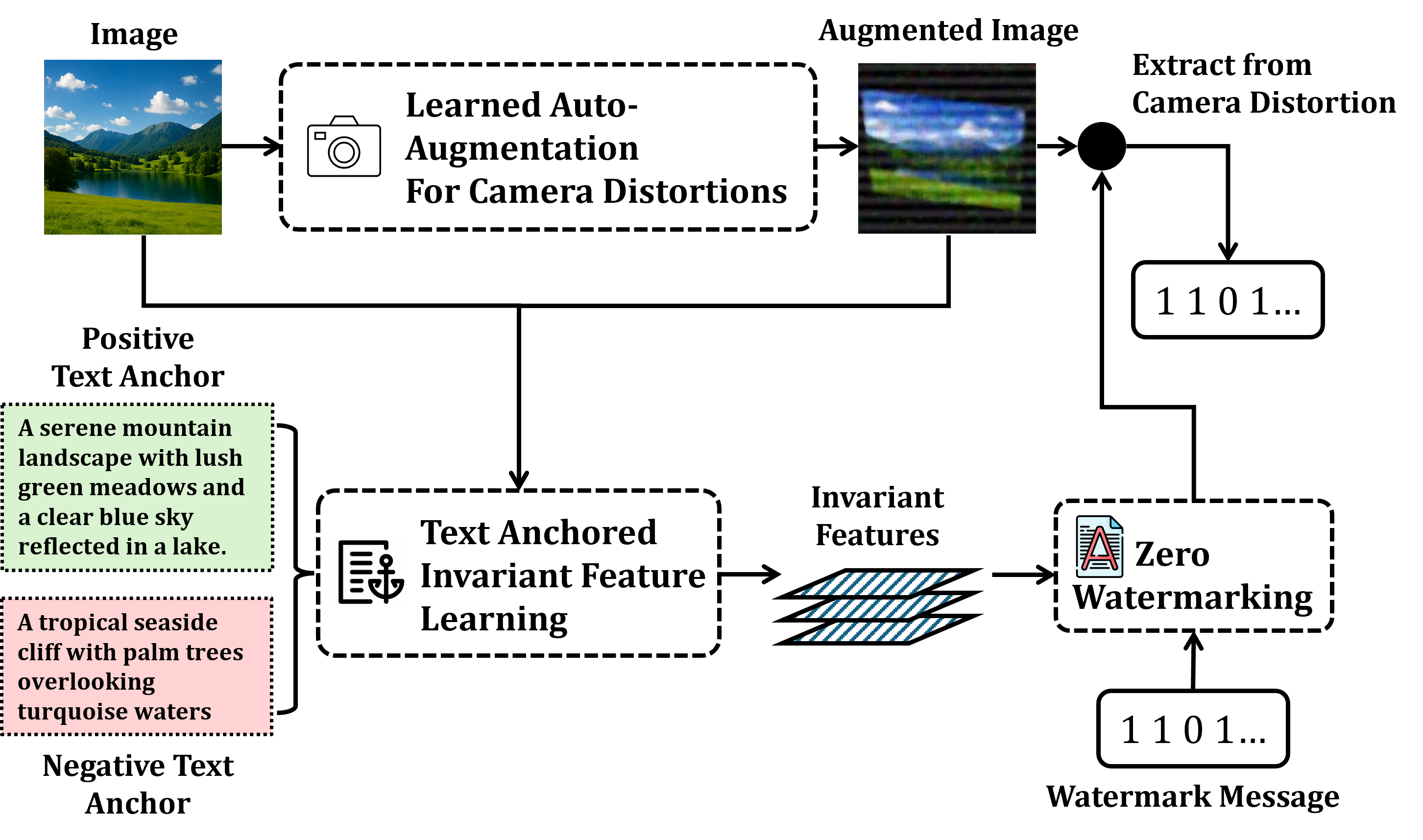
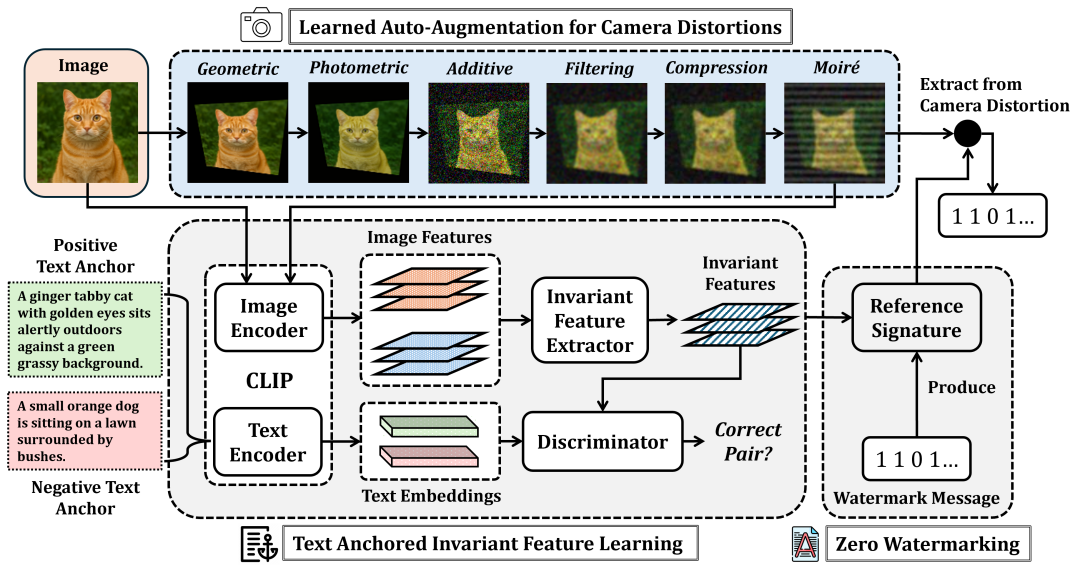
技术框架:TIACam框架主要包含三个模块:可学习的自动增强器、文本锚定的不变特征学习器和零水印头。首先,自动增强器模拟相机失真;然后,不变特征学习器利用文本信息对齐图像特征,提取对失真不变的特征;最后,零水印头将水印信息嵌入到不变特征中,实现零水印。整个框架通过联合优化,实现不变性、语义对齐和水印可恢复性的平衡。
关键创新:论文的关键创新在于:(1)提出了一个可学习的自动增强器,能够自动发现类似相机的失真,无需人工设计复杂的增强策略;(2)引入了文本锚定的不变特征学习器,通过跨模态对抗学习,增强了图像特征的语义一致性和不变性;(3)将自动增强、不变特征学习和零水印技术整合到一个统一的框架中,实现了端到端的优化。
关键设计:自动增强器使用可微分的几何、光度和莫尔算子来模拟相机失真。文本锚定的不变特征学习器使用对抗损失来对齐图像和文本特征,保证语义一致性。零水印头将二进制消息嵌入到不变特征空间中,不修改原始图像像素。损失函数包括对抗损失、水印损失和正则化损失,用于平衡不变性、语义对齐和水印可恢复性。
🖼️ 关键图片

📊 实验亮点
TIACam在合成和真实相机拍摄场景下均取得了显著的性能提升。实验结果表明,TIACam在特征稳定性和水印提取精度方面均优于现有方法,实现了最先进的性能。具体而言,TIACam在相机重捕获场景下的水印提取准确率比现有方法提高了10%-20%,证明了其在相机鲁棒性方面的优势。
🎯 应用场景
TIACam技术可应用于数字版权管理、图像溯源、身份认证等领域。在社交媒体、电子商务等场景下,可以有效保护图像版权,防止恶意篡改和盗用。该技术还可用于增强图像的安全性,例如在证件照、银行卡照片等敏感图像中嵌入水印,提高防伪能力。未来,该技术有望应用于更广泛的图像安全领域。
📄 摘要(原文)
Camera recapture introduces complex optical degradations, such as perspective warping, illumination shifts, and Moiré interference, that remain challenging for deep watermarking systems. We present TIACam, a text-anchored invariant feature learning framework with auto-augmentation for camera-robust zero-watermarking. The method integrates three key innovations: (1) a learnable auto-augmentor that discovers camera-like distortions through differentiable geometric, photometric, and Moiré operators; (2) a text-anchored invariant feature learner that enforces semantic consistency via cross-modal adversarial alignment between image and text; and (3) a zero-watermarking head that binds binary messages in the invariant feature space without modifying image pixels. This unified formulation jointly optimizes invariance, semantic alignment, and watermark recoverability. Extensive experiments on both synthetic and real-world camera captures demonstrate that TIACam achieves state-of-the-art feature stability and watermark extraction accuracy, establishing a principled bridge between multimodal invariance learning and physically robust zero-watermarking.