Open-Vocabulary Domain Generalization in Urban-Scene Segmentation
作者: Dong Zhao, Qi Zang, Nan Pu, Wenjing Li, Nicu Sebe, Zhun Zhong
分类: cs.CV
发布日期: 2026-02-21
期刊: CVPR2026
💡 一句话要点
提出S2-Corr机制,解决城市场景分割中开放词汇域泛化问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇语义分割 域泛化 视觉-语言模型 状态空间模型 自动驾驶 跨域学习 文本-图像相关性
📋 核心要点
- 现有域泛化语义分割方法受限于已知类别,无法应对开放世界中未见类别和域偏移的挑战。
- 提出S2-Corr机制,通过状态空间驱动的文本-图像相关性细化,减轻域偏移造成的文本-图像相关性扭曲。
- 在构建的OVDG-SS基准上,S2-Corr方法在跨域性能和效率上优于现有开放词汇语义分割方法。
📝 摘要(中文)
语义分割中的域泛化(DG-SS)旨在使分割模型在未见环境中表现出鲁棒性。然而,传统的DG-SS方法仅限于一组已知的类别,限制了它们在开放世界场景中的适用性。视觉-语言模型(VLM)的最新进展通过使模型能够识别更广泛的概念,推动了开放词汇语义分割(OV-SS)的发展。然而,这些模型仍然对域偏移敏感,并且在部署到未见环境时难以保持鲁棒性,这在城市驾驶场景中尤其严重。为了弥合这一差距,我们引入了开放词汇语义分割中的域泛化(OVDG-SS),这是一个新的设置,共同解决了未见域和未见类别的问题。我们为自动驾驶领域构建了第一个OVDG-SS基准,解决了以前未探索的问题,并涵盖了跨不同未见域和未见类别的合成到真实和真实到真实的泛化。在OVDG-SS中,我们观察到域偏移通常会扭曲预训练VLM中的文本-图像相关性,这阻碍了OV-SS模型的性能。为了应对这一挑战,我们提出了一种状态空间驱动的文本-图像相关性细化机制S2-Corr,该机制减轻了域引起的失真,并在分布变化下产生更一致的文本-图像相关性。在我们构建的基准上进行的大量实验表明,与现有的OV-SS方法相比,所提出的方法实现了卓越的跨域性能和效率。
🔬 方法详解
问题定义:论文旨在解决开放词汇域泛化语义分割(OVDG-SS)问题,即在同时存在未见过的领域和未见过的类别的情况下,如何使语义分割模型具有良好的泛化能力。现有方法要么只能处理固定类别的域泛化,要么在开放词汇语义分割中对域偏移敏感,无法同时解决这两个问题。特别是在城市驾驶场景中,这种挑战尤为突出。
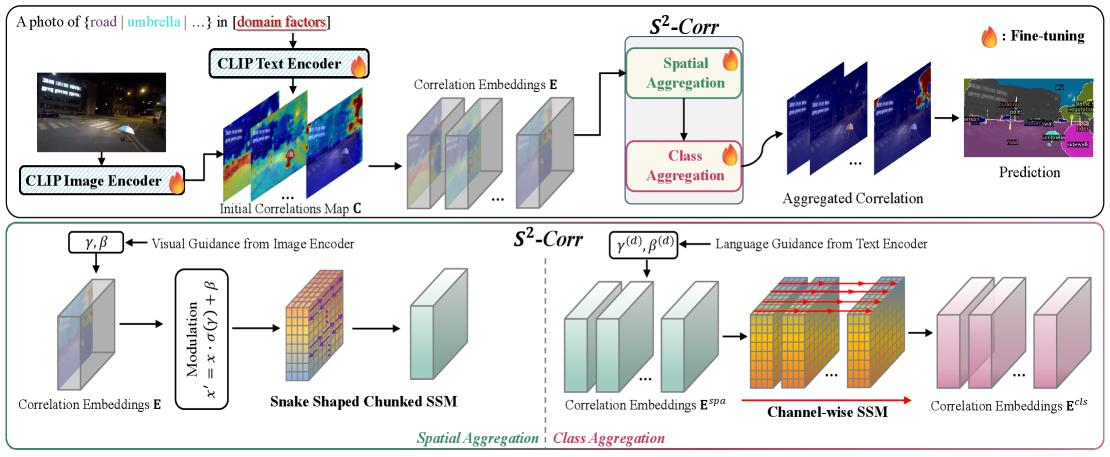
核心思路:论文的核心思路是,域偏移会扭曲预训练视觉-语言模型(VLM)中的文本-图像相关性,从而影响开放词汇语义分割的性能。因此,需要一种机制来细化这种相关性,使其在不同领域之间更加一致。论文提出的S2-Corr机制正是为了实现这一目标。
技术框架:S2-Corr机制的核心在于利用状态空间模型来建模文本-图像相关性的变化。整体流程可以概括为:首先,利用预训练的VLM提取文本和图像的特征;然后,使用状态空间模型对文本-图像相关性进行建模和细化,以减轻域偏移带来的影响;最后,利用细化后的相关性进行语义分割。
关键创新:S2-Corr的关键创新在于使用状态空间模型来显式地建模和细化文本-图像相关性。与直接使用预训练VLM的特征进行分割的方法相比,S2-Corr能够更好地适应不同领域的数据分布,从而提高泛化能力。此外,S2-Corr的设计使其能够以高效的方式进行计算,适用于实际应用。
关键设计:S2-Corr使用了一个简单的线性状态空间模型来建模文本-图像相关性。状态转移矩阵和观测矩阵可以通过学习得到,也可以直接使用预训练VLM的参数进行初始化。损失函数的设计旨在鼓励细化后的相关性与原始相关性保持一致,同时能够适应不同领域的数据分布。具体而言,可以使用对比损失或交叉熵损失来训练状态空间模型。
🖼️ 关键图片


📊 实验亮点
论文构建了首个自动驾驶场景下的OVDG-SS基准,并在该基准上验证了S2-Corr的有效性。实验结果表明,S2-Corr在跨域性能和效率上均优于现有OV-SS方法。具体性能数据和提升幅度在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、城市规划等领域。通过提升模型在未见环境和类别下的分割能力,可以提高自动驾驶系统的安全性,扩展机器人应用场景,并为城市规划提供更准确的环境理解。
📄 摘要(原文)
Domain Generalization in Semantic Segmentation (DG-SS) aims to enable segmentation models to perform robustly in unseen environments. However, conventional DG-SS methods are restricted to a fixed set of known categories, limiting their applicability in open-world scenarios. Recent progress in Vision-Language Models (VLMs) has advanced Open-Vocabulary Semantic Segmentation (OV-SS) by enabling models to recognize a broader range of concepts. Yet, these models remain sensitive to domain shifts and struggle to maintain robustness when deployed in unseen environments, a challenge that is particularly severe in urban-driving scenarios. To bridge this gap, we introduce Open-Vocabulary Domain Generalization in Semantic Segmentation (OVDG-SS), a new setting that jointly addresses unseen domains and unseen categories. We introduce the first benchmark for OVDG-SS in autonomous driving, addressing a previously unexplored problem and covering both synthetic-to-real and real-to-real generalization across diverse unseen domains and unseen categories. In OVDG-SS, we observe that domain shifts often distort text-image correlations in pre-trained VLMs, which hinders the performance of OV-SS models. To tackle this challenge, we propose S2-Corr, a state-space-driven text-image correlation refinement mechanism that mitigates domain-induced distortions and produces more consistent text-image correlations under distribution changes. Extensive experiments on our constructed benchmark demonstrate that the proposed method achieves superior cross-domain performance and efficiency compared to existing OV-SS approaches.