Echoes of Ownership: Adversarial-Guided Dual Injection for Copyright Protection in MLLMs
作者: Chengwei Xia, Fan Ma, Ruijie Quan, Yunqiu Xu, Kun Zhan, Yi Yang
分类: cs.CV
发布日期: 2026-02-21
备注: Accepted to CVPR 2026!
💡 一句话要点
提出基于对抗引导的双重注入方法,用于多模态大语言模型的版权保护
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 版权保护 对抗学习 信息隐藏 模型溯源
📋 核心要点
- 多模态大语言模型面临模型所有权和版本归属的挑战,缺乏有效的版权保护机制。
- 提出一种基于对抗学习和双重信息注入的版权触发器生成框架,将所有权信息嵌入模型。
- 实验证明该方法在各种微调和领域迁移场景下,能有效追踪模型沿袭,具有良好的鲁棒性。
📝 摘要(中文)
随着多模态大语言模型(MLLM)的快速部署和广泛应用,关于模型版本归属和所有权的争议日益频繁,引发了对知识产权保护的严重担忧。本文提出了一个为MLLM生成版权触发器的框架,使模型发布者能够将可验证的所有权信息嵌入到模型中。目标是构建触发图像,这些图像仅在原始模型的微调衍生模型中引发与所有权相关的文本响应,而在其他非衍生模型中保持惰性。我们的方法通过将图像视为可学习的张量,并利用所有权相关的语义信息的双重注入进行对抗优化,来构建跟踪触发图像。第一次注入是通过强制辅助MLLM的输出与预定义的所有权相关目标文本之间的文本一致性来实现的;一致性损失被反向传播以将此所有权相关信息注入到图像中。第二次注入是在语义级别执行的,方法是最小化图像的CLIP特征与目标文本的CLIP特征之间的距离。此外,我们引入了一个额外的对抗训练阶段,涉及从原始模型本身派生的辅助模型。该辅助模型经过专门训练以抵抗生成所有权相关的目标文本,从而增强了在经过大量微调的衍生模型中的鲁棒性。大量的实验表明,我们的双重注入方法在各种微调和领域转移场景下跟踪模型沿袭的有效性。
🔬 方法详解
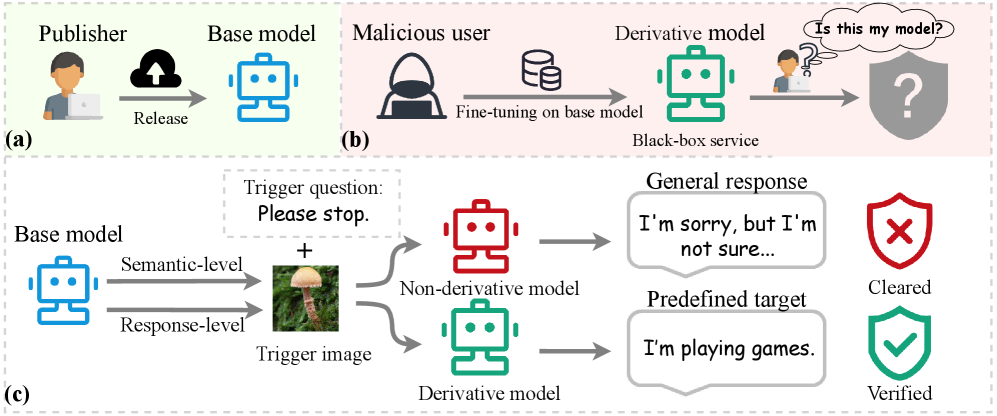
问题定义:论文旨在解决多模态大语言模型(MLLM)的版权保护问题。现有方法缺乏有效的机制来验证模型的来源和所有权,尤其是在模型经过微调或领域迁移后,难以追踪模型的沿袭。这使得模型容易被盗用或未经授权地修改和使用,损害了模型所有者的权益。
核心思路:论文的核心思路是通过生成特定的触发图像,将所有权信息嵌入到MLLM中。这些触发图像在原始模型的衍生版本中会触发与所有权相关的特定文本响应,而在非衍生模型中则不会。通过这种方式,模型所有者可以通过检查模型对触发图像的响应来验证其所有权。
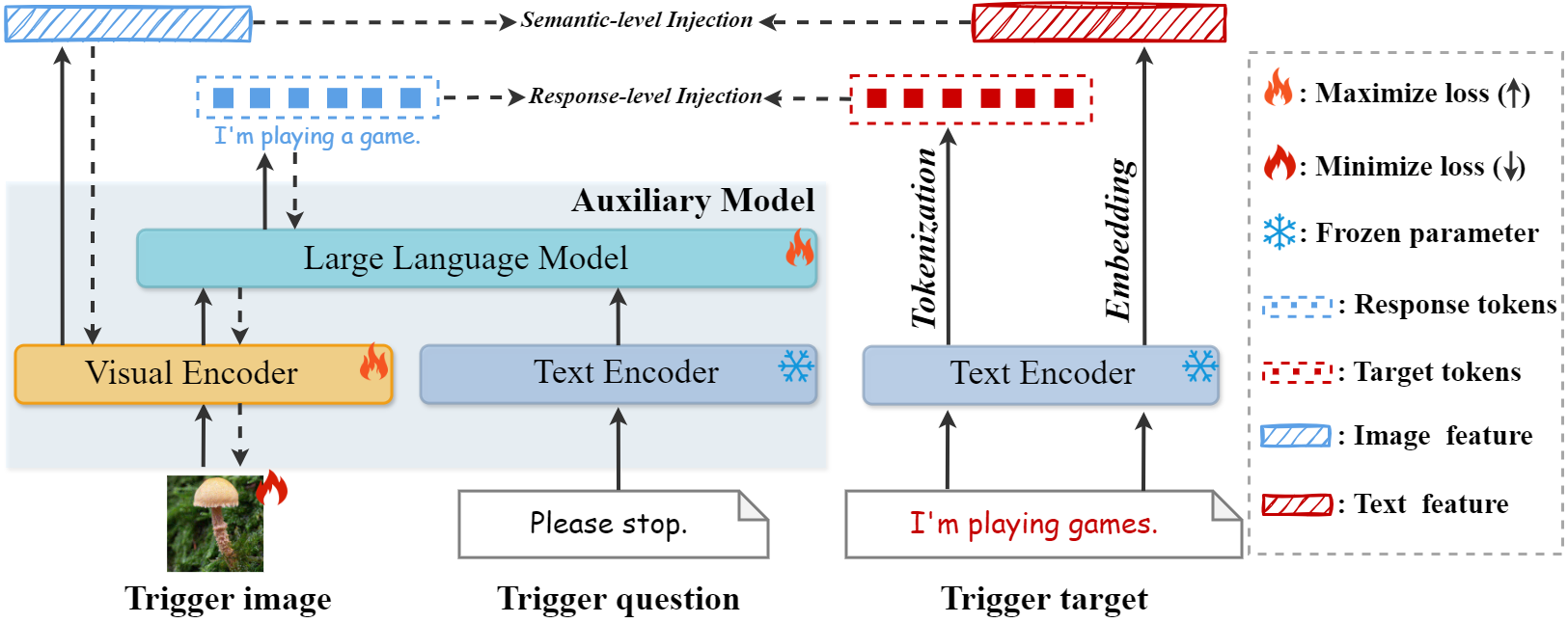
技术框架:该框架包含以下主要步骤:1) 将触发图像视为可学习的张量。2) 使用对抗优化方法,通过双重注入所有权相关的语义信息来生成触发图像。3) 第一次注入通过强制辅助MLLM的输出与预定义的所有权相关目标文本之间的一致性来实现。4) 第二次注入通过最小化图像和目标文本的CLIP特征之间的距离来实现。5) 引入一个额外的对抗训练阶段,使用从原始模型派生的辅助模型来抵抗生成所有权相关的目标文本。
关键创新:该方法的主要创新点在于双重注入策略和对抗训练阶段。双重注入策略结合了文本一致性和语义相似性,从而更有效地将所有权信息嵌入到图像中。对抗训练阶段通过训练辅助模型来抵抗生成所有权相关的文本,从而提高了触发器的鲁棒性,使其在经过大量微调的衍生模型中仍然有效。
关键设计:关键设计包括:1) 使用可学习的张量表示触发图像,使其可以通过梯度下降进行优化。2) 使用CLIP模型提取图像和文本的语义特征,并最小化它们之间的距离。3) 设计一致性损失函数,用于衡量辅助MLLM的输出与目标文本之间的相似度。4) 设计对抗训练策略,通过训练辅助模型来提高触发器的鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在各种微调和领域迁移场景下,能够有效地追踪模型沿袭。即使在经过大量微调的衍生模型中,触发器仍然能够触发与所有权相关的文本响应,表明该方法具有良好的鲁棒性。该方法优于现有的水印方法,在保护模型所有权方面具有显著优势。
🎯 应用场景
该研究成果可应用于多模态大语言模型的版权保护、模型溯源和知识产权管理。模型发布者可以使用该方法生成版权触发器,嵌入到模型中,以便在模型被盗用或未经授权使用时进行追踪和验证。这有助于维护模型所有者的权益,促进人工智能技术的健康发展。
📄 摘要(原文)
With the rapid deployment and widespread adoption of multimodal large language models (MLLMs), disputes regarding model version attribution and ownership have become increasingly frequent, raising significant concerns about intellectual property protection. In this paper, we propose a framework for generating copyright triggers for MLLMs, enabling model publishers to embed verifiable ownership information into the model. The goal is to construct trigger images that elicit ownership-related textual responses exclusively in fine-tuned derivatives of the original model, while remaining inert in other non-derivative models. Our method constructs a tracking trigger image by treating the image as a learnable tensor, performing adversarial optimization with dual-injection of ownership-relevant semantic information. The first injection is achieved by enforcing textual consistency between the output of an auxiliary MLLM and a predefined ownership-relevant target text; the consistency loss is backpropagated to inject this ownership-related information into the image. The second injection is performed at the semantic-level by minimizing the distance between the CLIP features of the image and those of the target text. Furthermore, we introduce an additional adversarial training stage involving the auxiliary model derived from the original model itself. This auxiliary model is specifically trained to resist generating ownership-relevant target text, thereby enhancing robustness in heavily fine-tuned derivative models. Extensive experiments demonstrate the effectiveness of our dual-injection approach in tracking model lineage under various fine-tuning and domain-shift scenarios.