Rethinking Preference Alignment for Diffusion Models with Classifier-Free Guidance
作者: Zhou Jiang, Yandong Wen, Zhen Liu
分类: cs.CV
发布日期: 2026-02-21
💡 一句话要点
提出基于Classifier-Free Guidance的扩散模型偏好对齐方法,无需重训练即可提升图像生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 扩散模型 偏好对齐 无分类器引导 对比学习 文本到图像生成
📋 核心要点
- 现有直接偏好优化方法在微调扩散模型时存在泛化性不足的问题,难以适应复杂的人类偏好。
- 借鉴无分类器引导的思想,将偏好对齐转化为在采样过程中利用偏好模型作为外部控制信号。
- 通过解耦正负偏好学习,并引入对比引导向量,在不重训练基础模型的情况下,提升了图像生成质量。
📝 摘要(中文)
将大规模文本到图像扩散模型与细微的人类偏好对齐仍然具有挑战性。虽然直接偏好优化(DPO)简单有效,但大规模微调通常表现出泛化差距。本文从测试时引导中获得灵感,将偏好对齐视为无分类器引导(CFG):微调的偏好模型在采样期间充当外部控制信号。在此基础上,提出了一种简单的方法,无需重新训练基础模型即可提高对齐效果。为了进一步提高泛化能力,将偏好学习解耦为分别在正负数据上训练的两个模块,并在推理时通过减去它们的预测(正减负)来形成对比引导向量,该向量按用户选择的强度缩放,并在每个步骤中添加到基础预测中。这产生了一个更清晰且可控的对齐信号。在Stable Diffusion 1.5和Stable Diffusion XL上使用Pick-a-Pic v2和HPDv3进行评估,显示出一致的定量和定性收益。
🔬 方法详解
问题定义:现有方法在对齐扩散模型与人类偏好时,存在泛化性问题。直接偏好优化(DPO)虽然有效,但在大规模微调时,模型容易过拟合训练数据,导致在未见过的数据上表现不佳。因此,如何提高偏好对齐的泛化能力,使其能够适应更广泛的人类偏好,是一个关键问题。
核心思路:本文的核心思路是将偏好对齐问题转化为一个无分类器引导(CFG)问题。通过训练一个偏好模型,该模型可以预测图像相对于给定文本提示的偏好得分。在图像生成过程中,利用该偏好模型作为外部控制信号,引导扩散模型的采样过程,从而生成更符合人类偏好的图像。这种方法的优势在于,它不需要重新训练基础扩散模型,而是通过在采样过程中引入偏好信息来实现对齐。
技术框架:该方法主要包含两个阶段:偏好模型训练和引导采样。在偏好模型训练阶段,使用正负样本数据训练一个偏好模型,该模型能够预测图像的偏好得分。在引导采样阶段,利用训练好的偏好模型,在扩散模型的采样过程中引入偏好信息。具体来说,通过计算正负偏好模型的预测差值,得到一个对比引导向量,然后将该向量按一定比例添加到扩散模型的预测中,从而引导采样过程。
关键创新:本文的关键创新在于将偏好对齐问题转化为一个无分类器引导问题,并提出了对比引导向量的概念。通过解耦正负偏好学习,并利用对比引导向量,可以更有效地引导扩散模型的采样过程,从而生成更符合人类偏好的图像。此外,该方法不需要重新训练基础扩散模型,而是通过在采样过程中引入偏好信息来实现对齐,从而降低了计算成本。
关键设计:在偏好模型训练阶段,使用了正负样本数据,并采用了对比损失函数来训练模型。在引导采样阶段,通过调整对比引导向量的缩放比例,可以控制偏好对齐的强度。此外,还探索了不同的偏好模型结构和训练策略,以提高偏好模型的预测精度。
🖼️ 关键图片
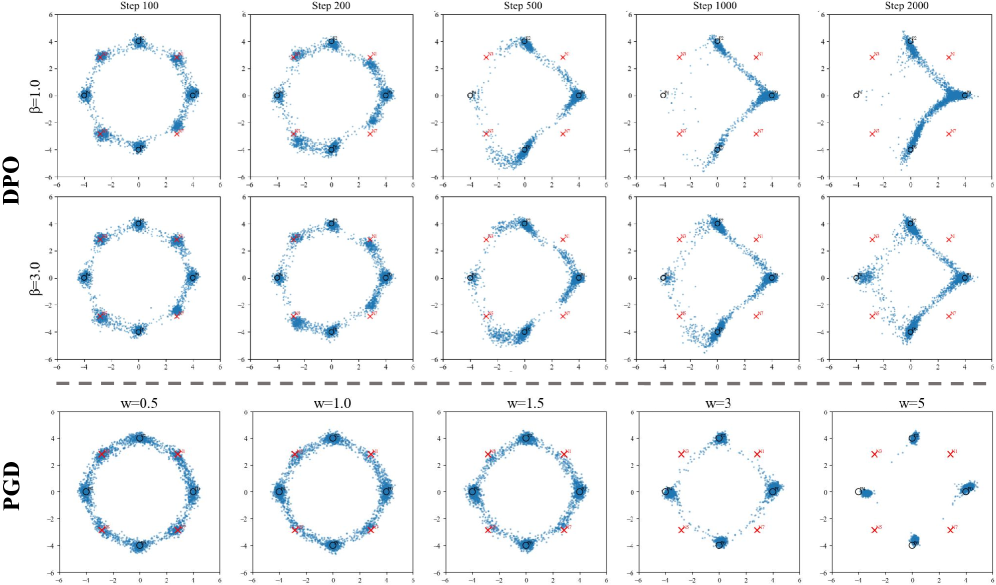


📊 实验亮点
实验结果表明,该方法在Stable Diffusion 1.5和Stable Diffusion XL上使用Pick-a-Pic v2和HPDv3数据集进行评估时,能够显著提高图像生成质量。与现有方法相比,该方法在定量和定性指标上均取得了显著提升,证明了其有效性和优越性。具体性能数据未知,但论文强调了“一致的定量和定性收益”。
🎯 应用场景
该研究成果可应用于各种文本到图像生成任务中,例如艺术创作、产品设计、虚拟现实等。通过将扩散模型与人类偏好对齐,可以生成更符合用户需求的图像,提高用户体验和满意度。此外,该方法还可以应用于其他生成模型中,例如视频生成、3D模型生成等,具有广泛的应用前景。
📄 摘要(原文)
Aligning large-scale text-to-image diffusion models with nuanced human preferences remains challenging. While direct preference optimization (DPO) is simple and effective, large-scale finetuning often shows a generalization gap. We take inspiration from test-time guidance and cast preference alignment as classifier-free guidance (CFG): a finetuned preference model acts as an external control signal during sampling. Building on this view, we propose a simple method that improves alignment without retraining the base model. To further enhance generalization, we decouple preference learning into two modules trained on positive and negative data, respectively, and form a \emph{contrastive guidance} vector at inference by subtracting their predictions (positive minus negative), scaled by a user-chosen strength and added to the base prediction at each step. This yields a sharper and controllable alignment signal. We evaluate on Stable Diffusion 1.5 and Stable Diffusion XL with Pick-a-Pic v2 and HPDv3, showing consistent quantitative and qualitative gains.