Benchmarking Computational Pathology Foundation Models For Semantic Segmentation
作者: Lavish Ramchandani, Aashay Tinaikar, Dev Kumar Das, Rohit Garg, Tijo Thomas
分类: cs.CV
发布日期: 2026-02-21
备注: 5 pages, submitted to IEEE ISBI 2026
💡 一句话要点
提出计算病理学分割基准,评估并集成多个Foundation Model以提升组织病理图像语义分割性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算病理学 语义分割 Foundation Model 基准测试 注意力机制 集成学习 组织病理学 XGBoost
📋 核心要点
- 现有方法缺乏对Foundation Model在组织病理学图像语义分割中性能的系统评估和比较。
- 利用Foundation Model的注意力图作为像素级特征,结合XGBoost分类器,构建快速且模型无关的评估框架。
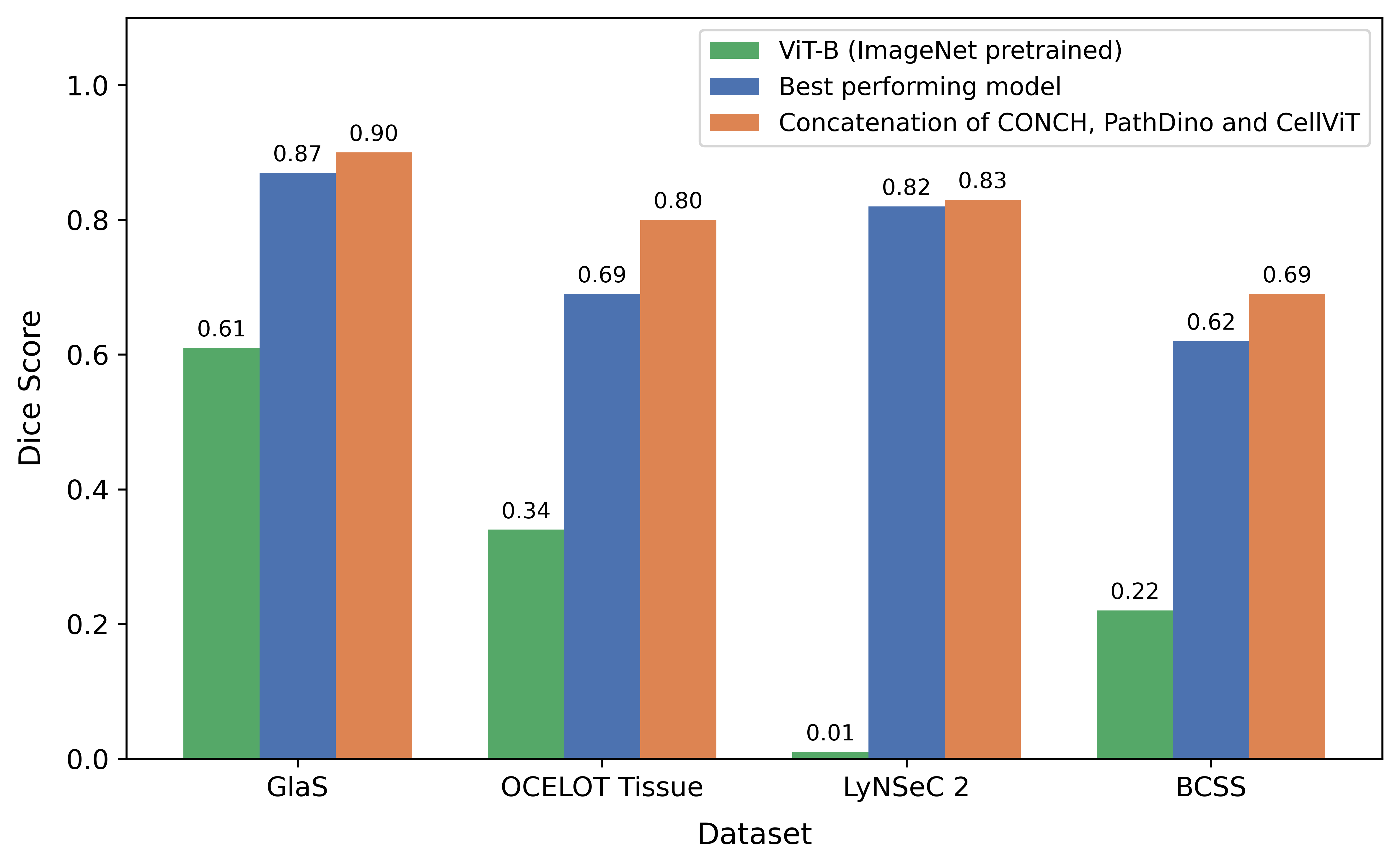
- 实验表明,CONCH表现最佳,且集成多个Foundation Model的特征能显著提升分割性能,平均提升7.95%。
📝 摘要(中文)
近年来,CLIP、DINO和CONCH等Foundation Model在各种图像任务中展现了卓越的领域泛化和无监督特征提取能力。然而,针对组织病理学中像素级语义分割任务,对这些模型进行系统且独立的评估仍然不足。本研究提出了一种稳健的基准测试方法,用于评估10个Foundation Model在四个组织病理学数据集上的性能,这些数据集涵盖了形态组织区域和细胞/核分割任务。该方法利用Foundation Model的注意力图作为像素级特征,然后使用机器学习算法XGBoost进行分类,从而实现快速、可解释且模型无关的评估,无需微调。结果表明,视觉语言Foundation Model CONCH在数据集上的表现优于纯视觉Foundation Model,PathDino紧随其后。进一步分析表明,在不同组织病理学队列上训练的模型能够捕获互补的形态学表示,并且连接它们的特征可以产生更优越的分割性能。CONCH、PathDino和CellViT的特征连接在所有数据集上的性能均优于单个模型,平均提升7.95%,表明Foundation Model的集成可以更好地泛化到不同的组织病理学分割任务。
🔬 方法详解
问题定义:论文旨在解决组织病理学图像语义分割问题,现有方法缺乏对新兴Foundation Model的系统评估,难以有效利用这些模型进行像素级别的精确分割。现有方法通常需要针对特定数据集进行微调,泛化能力有限。
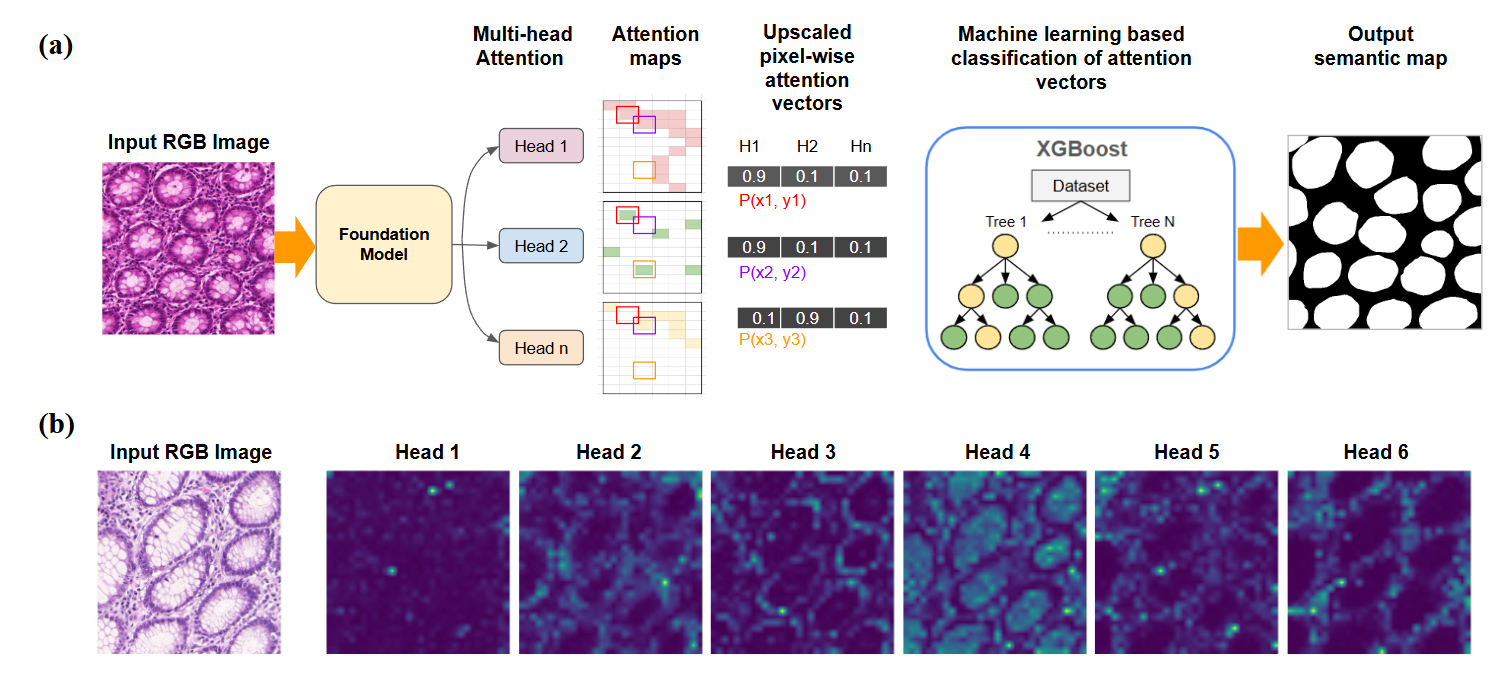
核心思路:论文的核心思路是利用Foundation Model提取的图像特征,特别是注意力图,作为像素级别的语义信息表示。通过将这些特征输入到机器学习分类器中,实现快速、可解释且模型无关的分割评估。此外,通过集成多个Foundation Model的特征,利用它们互补的形态学表示,进一步提升分割性能。
技术框架:整体框架包括以下几个主要阶段:1) 选择和加载多个Foundation Model(如CLIP、DINO、CONCH等);2) 使用这些模型提取组织病理学图像的特征,特别是注意力图;3) 将注意力图作为像素级别的特征输入到XGBoost分类器中进行训练和预测;4) 对不同Foundation Model的性能进行基准测试和比较;5) 将表现较好的Foundation Model的特征进行连接,并再次输入XGBoost分类器进行训练和预测,评估集成效果。
关键创新:最重要的技术创新点在于提出了一种无需微调的、基于注意力图的Foundation Model评估方法。这种方法能够快速评估不同模型在组织病理学分割任务中的性能,并发现集成多个模型可以显著提升分割效果。与传统方法相比,该方法更加高效、可解释,并且具有更好的泛化能力。
关键设计:论文的关键设计包括:1) 选择XGBoost作为分类器,因为它具有训练速度快、可解释性强等优点;2) 使用注意力图作为像素级别的特征,因为它能够反映模型对图像不同区域的关注程度;3) 通过实验选择合适的特征连接方式,以最大程度地利用不同Foundation Model的互补信息;4) 在多个组织病理学数据集上进行评估,以验证方法的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,视觉语言Foundation Model CONCH在组织病理学分割任务中表现最佳,优于纯视觉模型。通过集成CONCH、PathDino和CellViT的特征,在所有数据集上的分割性能平均提升了7.95%,验证了集成多个Foundation Model的有效性。该研究提供了一个评估和利用Foundation Model进行组织病理学图像分割的有效框架。
🎯 应用场景
该研究成果可应用于计算机辅助病理诊断,例如肿瘤区域的自动分割、细胞核的精确计数等。通过集成多个Foundation Model,可以提高诊断的准确性和效率,辅助病理医生进行更快速、更准确的疾病诊断,并为个性化治疗方案的制定提供支持。未来,该方法可以扩展到其他医学图像分析任务中。
📄 摘要(原文)
In recent years, foundation models such as CLIP, DINO,and CONCH have demonstrated remarkable domain generalization and unsupervised feature extraction capabilities across diverse imaging tasks. However, systematic and independent evaluations of these models for pixel-level semantic segmentation in histopathology remain scarce. In this study, we propose a robust benchmarking approach to asses 10 foundational models on four histopathological datasets covering both morphological tissue-region and cellular/nuclear segmentation tasks. Our method leverages attention maps of foundation models as pixel-wise features, which are then classified using a machine learning algorithm, XGBoost, enabling fast, interpretable, and model-agnostic evaluation without finetuning. We show that the vision language foundation model, CONCH performed the best across datasets when compared to vision-only foundation models, with PathDino as close second. Further analysis shows that models trained on distinct histopathology cohorts capture complementary morphological representations, and concatenating their features yields superior segmentation performance. Concatenating features from CONCH, PathDino and CellViT outperformed individual models across all the datasets by 7.95% (averaged across the datasets), suggesting that ensembles of foundation models can better generalize to diverse histopathological segmentation tasks.