HIME: Mitigating Object Hallucinations in LVLMs via Hallucination Insensitivity Model Editing
作者: Ahmed Akl, Abdelwahed Khamis, Ali Cheraghian, Zhe Wang, Sara Khalifa, Kewen Wang
分类: cs.CV
发布日期: 2026-02-21
💡 一句话要点
提出HIME:通过幻觉不敏感模型编辑缓解LVLM中的对象幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型视觉语言模型 对象幻觉 模型编辑 幻觉不敏感性分数 层自适应 免训练 多模态学习
📋 核心要点
- 现有LVLM易产生对象幻觉,影响实际应用,而微调成本高昂,缺乏高效的免训练方法。
- 提出HIME方法,通过计算幻觉不敏感性分数(HIS)来指导层自适应的权重编辑,选择性地抑制幻觉。
- 实验表明,HIME在多个基准测试中显著降低了幻觉,平均降低61.8%,且没有引入额外的计算开销。
📝 摘要(中文)
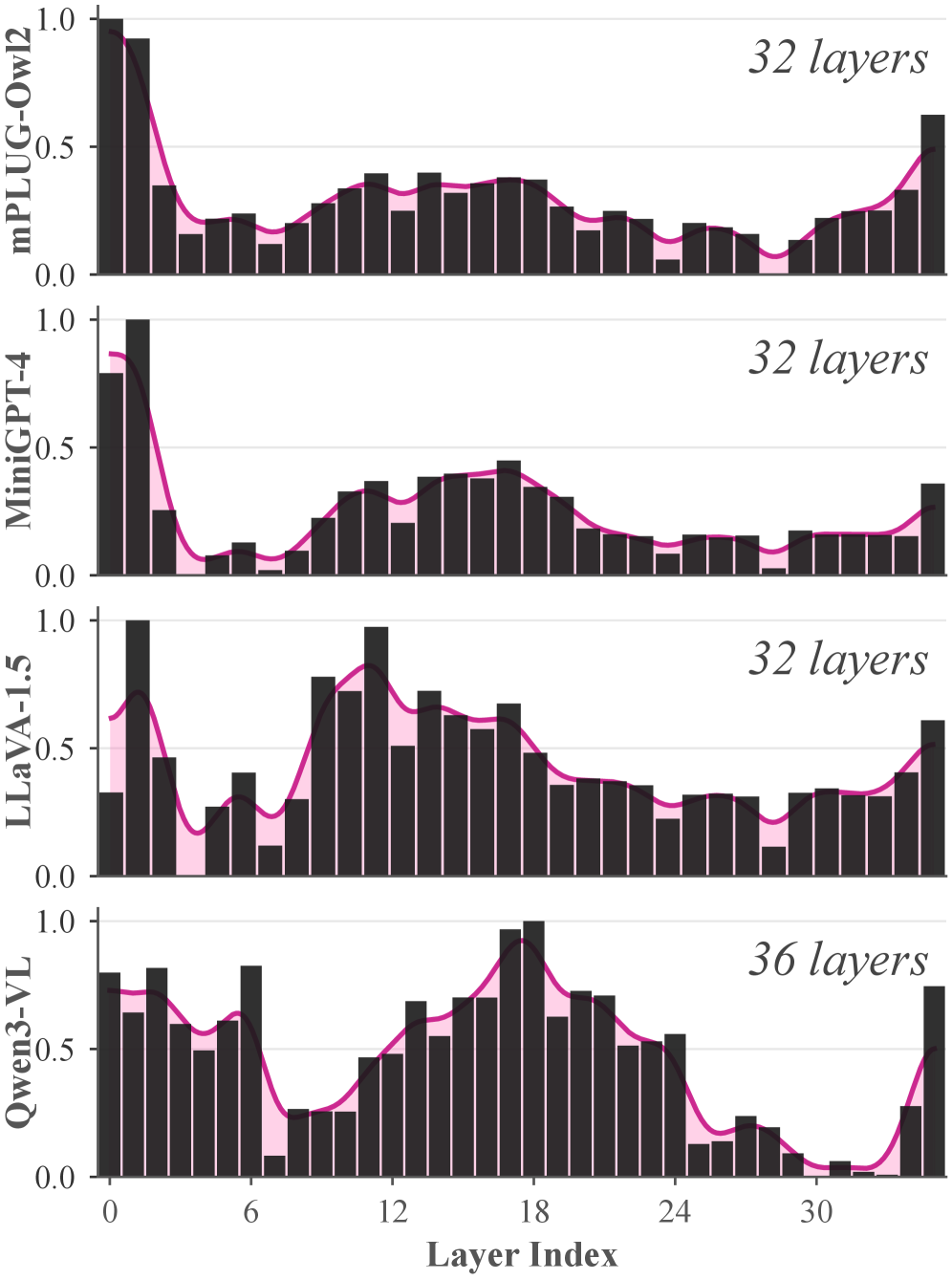
大型视觉语言模型(LVLM)展现了令人印象深刻的多模态理解能力,但它们仍然容易产生对象幻觉,即模型描述不存在的对象或归因不正确的客观信息,这引起了对可靠的实际部署的严重担忧。虽然微调是一种常用的缓解策略,但其高计算成本和实际困难促使人们需要免训练的替代方案,其中模型编辑最近已成为一个有希望的方向。然而,不加区分的编辑可能会破坏预训练LVLM中编码的丰富的隐性知识,从而引出一个根本问题:在每一层需要多少干预才能抑制幻觉,同时保留预训练的知识?为了解决这个问题,我们对基于三种广泛使用的大型语言模型骨干(Qwen、LLaMA 和 Vicuna)构建的 LVLM 解码器进行了系统分析,揭示了对对象幻觉的敏感性方面明显的层间差异。基于这些见解,我们引入了幻觉不敏感性分数(HIS),这是一个原则性指标,用于量化每一层对幻觉的敏感性,并为有针对性的干预提供指导。利用 HIS,我们提出了一种简单而有效的层自适应权重编辑方法,即幻觉不敏感性模型编辑(HIME),它选择性地修改潜在特征以抑制幻觉,同时保留预训练的知识。广泛的实验表明,HIME 在开放式生成基准测试(包括 CHAIR、MME 和 GPT-4V 辅助评估)中,平均减少了 61.8% 的幻觉,而没有引入额外的参数、推理时延迟或计算开销。
🔬 方法详解
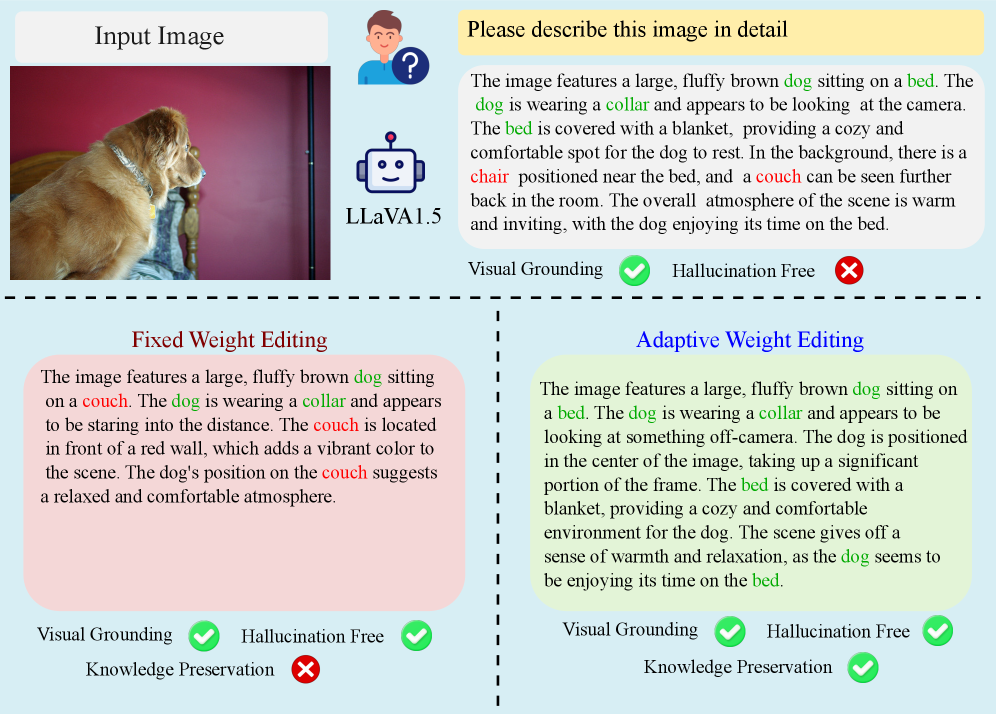
问题定义:论文旨在解决大型视觉语言模型(LVLM)中存在的对象幻觉问题,即模型会描述不存在的对象或赋予对象错误的属性。现有方法,如微调,计算成本高昂且难以实际应用。因此,需要一种免训练的方法来缓解LVLM中的幻觉问题,同时避免破坏模型预训练的知识。
核心思路:论文的核心思路是并非所有层对幻觉的贡献相同。通过分析不同层对幻觉的敏感性,可以有选择性地编辑模型权重,从而在抑制幻觉的同时,保留模型预训练的知识。关键在于找到一种方法来量化每一层对幻觉的敏感性,并基于此进行有针对性的干预。
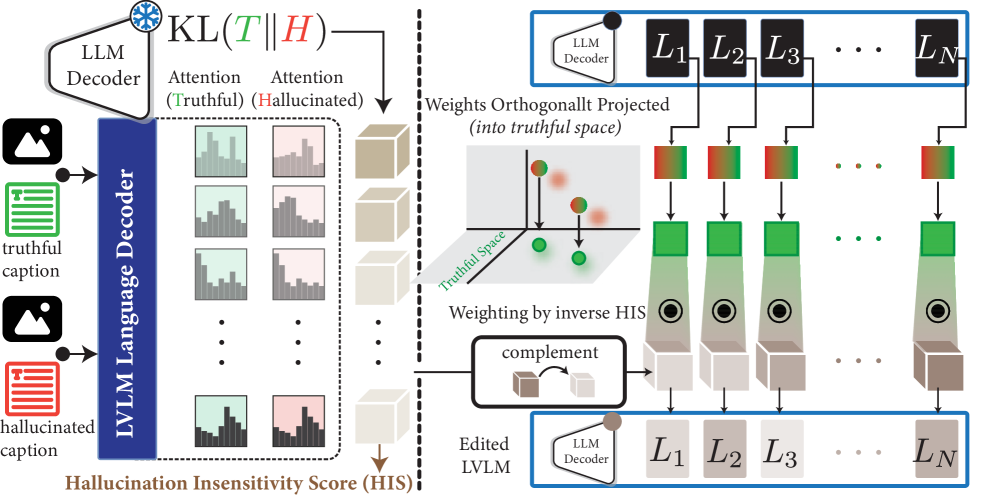
技术框架:HIME方法包含两个主要步骤:1) 计算幻觉不敏感性分数(HIS)。HIS用于量化LVLM解码器中每一层对幻觉的敏感程度。2) 基于HIS进行层自适应的权重编辑。根据HIS,选择性地修改模型权重,以抑制幻觉,同时保留预训练知识。整个过程无需训练,直接在预训练模型上进行。
关键创新:论文的关键创新在于提出了幻觉不敏感性分数(HIS),这是一个原则性的指标,用于量化每一层对幻觉的敏感性。HIS的提出使得可以进行有针对性的模型编辑,避免了盲目编辑可能导致的性能下降。此外,HIME方法是一种免训练的方法,避免了微调带来的高计算成本。
关键设计:HIS的计算方法未知,论文中可能涉及一些特定的参数设置和权重编辑策略,这些细节决定了HIME方法的有效性。层自适应权重编辑的具体实现方式,例如如何根据HIS调整权重,也是关键的设计细节。损失函数未知,因为该方法是免训练的。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HIME方法在CHAIR、MME和GPT-4V辅助评估等开放式生成基准测试中,平均降低了61.8%的幻觉。该方法无需引入额外的参数、推理时延迟或计算开销,在降低幻觉的同时,保持了模型的效率和性能。这表明HIME是一种有效的、实用的LVLM幻觉缓解方法。
🎯 应用场景
该研究成果可应用于各种需要可靠视觉语言理解的场景,例如自动驾驶、智能客服、医疗诊断等。通过减少LVLM中的对象幻觉,可以提高这些应用的安全性和可靠性,促进人工智能技术在实际场景中的广泛应用。此外,该方法无需训练,具有很高的实用价值。
📄 摘要(原文)
Large Vision-Language Models (LVLMs) have demonstrated impressive multimodal understanding capabilities, yet they remain prone to object hallucination, where models describe non-existent objects or attribute incorrect factual information, raising serious concerns for reliable real-world deployment. While fine-tuning is a commonly adopted mitigation strategy, its high computational cost and practical difficulty motivate the need for training-free alternatives, among which model editing has recently emerged as a promising direction. However, indiscriminate editing risks disrupting the rich implicit knowledge encoded in pre-trained LVLMs, leading to a fundamental question: how much intervention is necessary at each layer to suppress hallucinations while preserving pre-trained knowledge? To address this question, we present a systematic analysis of LVLM decoders built on three widely used large language model backbones-Qwen, LLaMA, and Vicuna-revealing clear layer-wise differences in susceptibility to object hallucination. Building on these insights, we introduce the Hallucination Insensitivity Score (HIS), a principled metric that quantifies each layer's sensitivity to hallucination and provides guidance for targeted intervention. Leveraging HIS, we propose Hallucination Insensitivity Model Editing (HIME), a simple yet effective layer-adaptive weight editing approach that selectively modifies latent features to suppress hallucinations while preserving pre-trained knowledge. Extensive experiments demonstrate that HIME reduces hallucinations by an average of 61.8% across open-ended generation benchmarks, including CHAIR, MME, and GPT-4V-aided evaluation, without introducing additional parameters, inference-time latency, or computational overhead.