Think with Grounding: Curriculum Reinforced Reasoning with Video Grounding for Long Video Understanding
作者: Houlun Chen, Xin Wang, Guangyao Li, Yuwei Zhou, Yihan Chen, Jia Jia, Wenwu Zhu
分类: cs.CV, cs.AI
发布日期: 2026-02-21
💡 一句话要点
提出Video-TwG,通过课程强化推理和视频定位提升长视频理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 视频定位 多模态推理 强化学习 课程学习
📋 核心要点
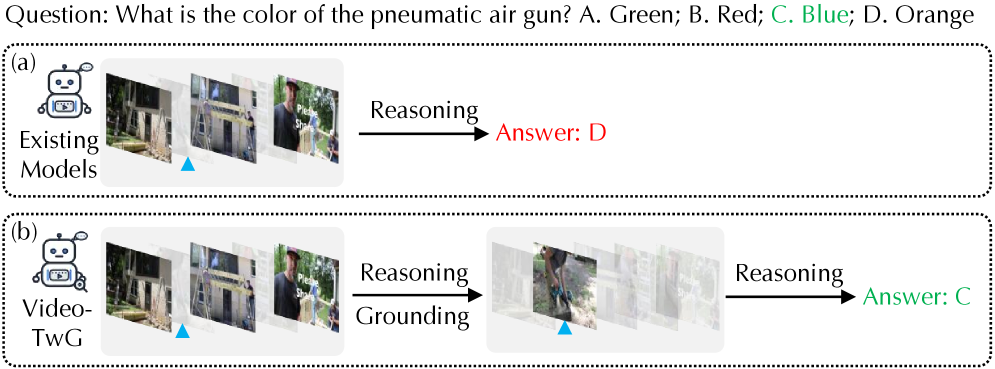
- 现有长视频理解方法在固定视频上下文中进行纯文本推理,易忽略关键细节,导致幻觉问题。
- 论文提出Video-TwG框架,采用“Think-with-Grounding”范式,使模型能按需定位关键视频片段。
- 实验表明,Video-TwG在多个长视频理解数据集上优于现有基线模型,验证了方法的有效性。
📝 摘要(中文)
长视频理解面临着时间跨度长、多模态信息丰富的挑战。现有方法采用文本形式的推理来提升模型分析复杂视频线索的能力,但由于长视频的时间冗余性,固定视频上下文的纯文本推理可能加剧幻觉问题,忽略关键细节。为了解决这个问题,我们提出了Video-TwG,一个课程强化框架,采用了一种新颖的“Think-with-Grounding”范式,使视频LLM能够主动决定何时执行按需定位,仅在必要时选择性地放大与问题相关的片段。Video-TwG可以以直接的方式进行端到端训练,无需复杂的辅助模块或大量标注的推理轨迹。具体来说,我们设计了一个两阶段强化课程策略,模型首先在一个带有定位标签的小型短视频GQA数据集上学习“Think-with-Grounding”行为,然后扩展到具有不同领域视频的各种通用QA数据,以鼓励泛化。此外,为了处理各种数据的复杂“Think-with-Grounding”推理,我们提出了TwG-GRPO算法,该算法具有细粒度的定位奖励、自我确认的伪奖励和准确率门控机制。最后,我们提出了一个新的TwG-51K数据集,以促进训练。在Video-MME、LongVideoBench和MLVU上的实验表明,Video-TwG始终优于强大的LVU基线。进一步的消融实验验证了我们的两阶段强化课程策略的必要性,并表明我们的TwG-GRPO更好地利用了各种未标记数据来提高定位质量并减少冗余定位,而不会牺牲QA性能。
🔬 方法详解
问题定义:现有长视频理解方法主要依赖于文本推理,但在处理长视频时,由于时间冗余性和信息复杂性,固定长度的视频上下文可能导致模型忽略关键视觉线索,从而产生幻觉,降低问答准确性。现有方法缺乏在推理过程中动态关注关键视频片段的能力。
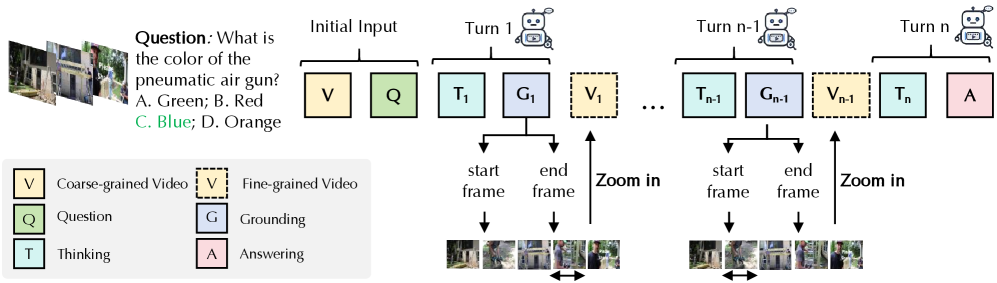
核心思路:论文的核心思路是让模型在推理过程中能够主动决定何时需要进行视频片段的定位(grounding),即“Think-with-Grounding”。模型不再是被动地接收固定长度的视频上下文,而是根据当前的推理状态,选择性地关注与问题相关的视频片段。这种按需定位的方式可以减少冗余信息的干扰,提高模型对关键信息的敏感度。
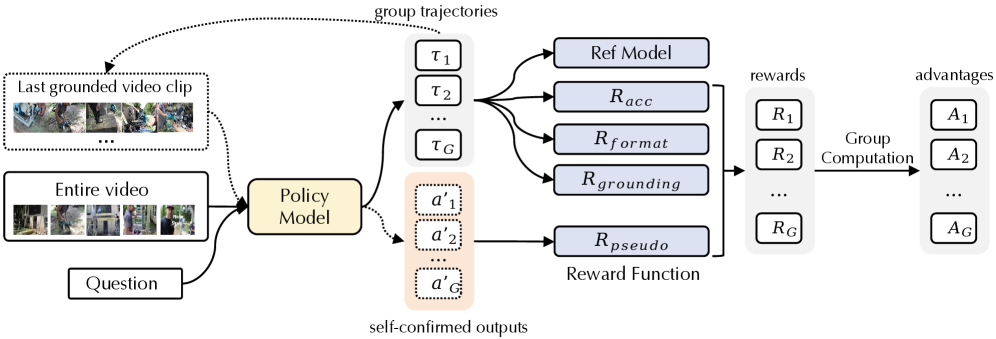
技术框架:Video-TwG框架主要包含以下几个关键模块:1) 视频编码器:用于提取视频特征。2) 文本编码器:用于提取问题和推理过程中的文本特征。3) 推理模块:基于LLM进行文本推理,并决定何时需要进行视频定位。4) 定位模块:根据推理模块的决策,从视频中定位与问题相关的片段。5) 奖励机制:用于训练模型学习何时进行定位,包括细粒度的定位奖励、自我确认的伪奖励和准确率门控机制。整体流程是,模型首先对视频和问题进行编码,然后通过推理模块进行推理,如果推理模块认为需要定位,则调用定位模块定位相关片段,并将定位到的片段信息融入到推理过程中,最终给出答案。
关键创新:该论文的关键创新在于提出了“Think-with-Grounding”范式,将视频定位融入到推理过程中,使模型能够主动地关注关键视频片段。此外,论文还提出了两阶段强化课程策略和TwG-GRPO算法,用于更好地训练模型学习何时进行定位。与现有方法的本质区别在于,现有方法通常采用固定长度的视频上下文,而该论文提出的方法可以根据推理状态动态地选择视频片段。
关键设计:1) 两阶段强化课程策略:首先在小规模的短视频数据集上预训练模型,学习基本的定位能力,然后在更大规模的长视频数据集上进行微调,提高模型的泛化能力。2) TwG-GRPO算法:采用细粒度的定位奖励,鼓励模型定位到更准确的片段;采用自我确认的伪奖励,利用未标注数据提高定位质量;采用准确率门控机制,防止定位操作影响问答准确率。3) 新数据集TwG-51K:用于支持模型的训练和评估。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Video-TwG在Video-MME、LongVideoBench和MLVU等数据集上均取得了显著的性能提升,优于现有的强基线模型。消融实验验证了两阶段强化课程策略和TwG-GRPO算法的有效性,表明该方法能够提高定位质量,减少冗余定位,同时保证问答准确率。
🎯 应用场景
该研究成果可应用于智能视频分析、视频问答、视频搜索等领域。例如,在智能监控中,可以帮助快速定位异常事件;在视频搜索中,可以根据用户的问题快速找到相关的视频片段;在教育领域,可以用于创建更具互动性的视频学习体验。
📄 摘要(原文)
Long video understanding is challenging due to rich and complicated multimodal clues in long temporal range.Current methods adopt reasoning to improve the model's ability to analyze complex video clues in long videos via text-form reasoning.However,the existing literature suffers from the fact that the text-only reasoning under fixed video context may exacerbate hallucinations since detailed crucial clues are often ignored under limited video context length due to the temporal redundancy of long videos.To address this gap,we propose Video-TwG,a curriculum reinforced framework that employs a novel Think-with-Grounding paradigm,enabling video LLMs to actively decide when to perform on-demand grounding during interleaved text-video reasoning, selectively zooming into question-relevant clips only when necessary.Video-TwG can be trained end-to-end in a straightforward manner, without relying on complex auxiliary modules or heavily annotated reasoning tracesIn detail,we design a Two-stage Reinforced Curriculum Strategy, where the model first learns think-with-grounding behavior on a small short-video GQA dataset with grounding labels,and then scales to diverse general QA data with videos of diverse domains to encourage generalization. Further, to handle complex think-with-grounding reasoning for various kinds of data,we propose TwG-GRPO algorithm which features the fine-grained grounding reward, self-confirmed pseudo reward and accuracy-gated mechanism.Finally,we propose to construct a new TwG-51K dataset that facilitates training. Experiments on Video-MME, LongVideoBench, and MLVU show that Video-TwG consistently outperforms strong LVU baselines.Further ablation validates the necessity of our Two-stage Reinforced Curriculum Strategy and shows our TwG-GRPO better leverages diverse unlabeled data to improve grounding quality and reduce redundant groundings without sacrificing QA performance.