Narrating For You: Prompt-guided Audio-visual Narrating Face Generation Employing Multi-entangled Latent Space
作者: Aashish Chandra, Aashutosh A, Abhijit Das
分类: cs.CV
发布日期: 2026-02-20
备注: To appear in the Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2026. Presented at Poster Session 1
💡 一句话要点
提出一种基于多重纠缠潜在空间的提示引导式音视频叙事人脸生成方法
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 说话人脸生成 多模态融合 潜在空间 音视频同步 深度学习
📋 核心要点
- 现有方法难以从静态图像、声音轮廓和目标文本生成逼真的说话人脸。
- 该方法利用多重纠缠潜在空间,在音频和视频模态之间建立时空人物特定特征。
- 通过编码提示文本、驱动图像和声音轮廓,模型能够生成高质量的音视频内容。
📝 摘要(中文)
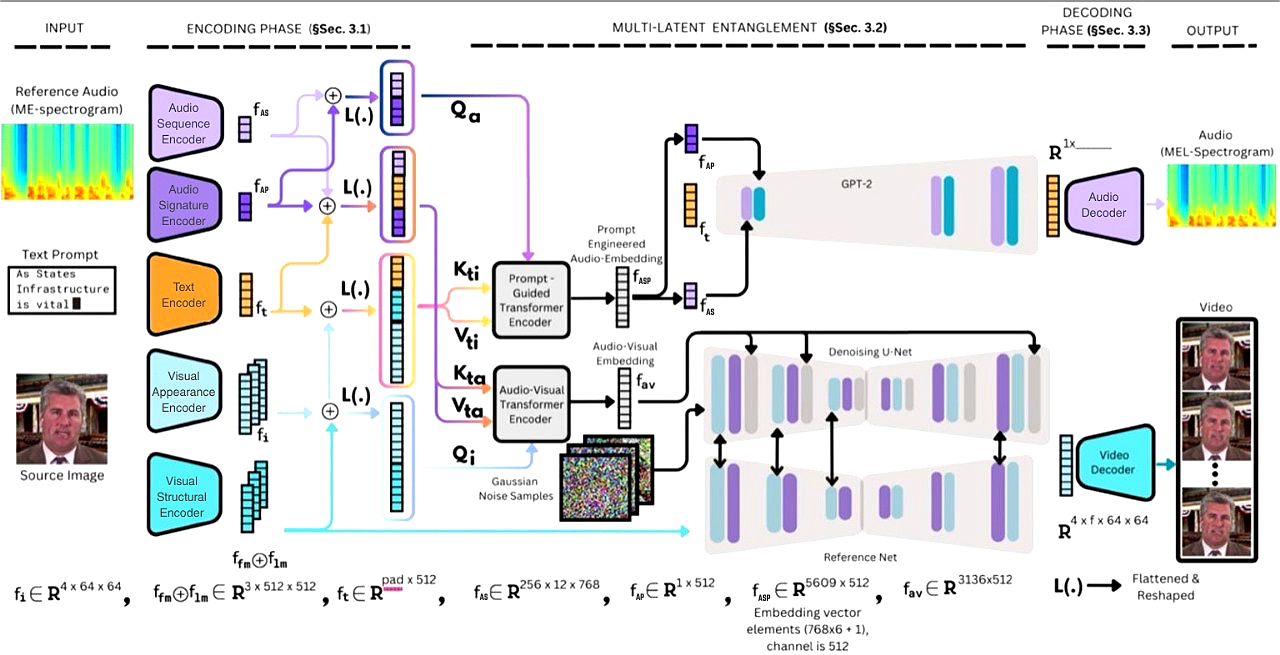
本文提出了一种新颖的方法,用于生成逼真的说话人脸,通过从静态图像、声音轮廓和目标文本合成一个人的声音和面部动作来实现。该模型编码提示/驱动文本、驱动图像和个人的声音轮廓,然后将它们组合起来传递到多重纠缠潜在空间,以促进音频和视频模态生成管道的关键值对和查询。多重纠缠潜在空间负责建立模态之间的时空人物特定特征。此外,纠缠的特征被传递到每个模态的各自解码器,用于输出音频和视频生成。
🔬 方法详解
问题定义:论文旨在解决从静态图像、声音轮廓和目标文本生成逼真说话人脸的问题。现有方法通常难以在音频和视频模态之间建立一致的时空人物特定特征,导致生成的人脸不够自然和真实。
核心思路:论文的核心思路是利用多重纠缠潜在空间,将提示文本、驱动图像和声音轮廓编码到该空间中,从而在音频和视频模态之间建立联系。通过这种方式,模型可以学习到人物特定的时空特征,并生成更逼真的说话人脸。
技术框架:整体框架包括三个主要模块:编码器、多重纠缠潜在空间和解码器。编码器负责将提示文本、驱动图像和声音轮廓编码成潜在向量。多重纠缠潜在空间负责建立模态之间的联系,并提取人物特定的时空特征。解码器则根据潜在空间中的特征生成音频和视频。
关键创新:最重要的技术创新点在于多重纠缠潜在空间的设计。该空间能够有效地将不同模态的信息融合在一起,并学习到人物特定的时空特征。这使得模型能够生成更逼真、更自然的说话人脸。与现有方法相比,该方法能够更好地捕捉音频和视频之间的关联性。
关键设计:论文中使用了Transformer网络作为编码器和解码器的基础架构。损失函数包括对抗损失、重构损失和一致性损失。对抗损失用于提高生成图像的真实性,重构损失用于保证生成内容与输入信息的一致性,一致性损失用于约束音频和视频模态之间的一致性。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
论文的主要亮点在于提出了多重纠缠潜在空间,并将其应用于说话人脸生成任务。实验结果表明,该方法能够生成比现有方法更逼真、更自然的说话人脸。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究具有广泛的应用前景,例如虚拟助手、电影制作、游戏开发和在线教育等领域。它可以用于创建逼真的虚拟人物,并使其能够根据文本和语音进行自然的交流。此外,该技术还可以用于修复老电影中的音频和视频,或者为无声电影配音。
📄 摘要(原文)
We present a novel approach for generating realistic speaking and talking faces by synthesizing a person's voice and facial movements from a static image, a voice profile, and a target text. The model encodes the prompt/driving text, the driving image, and the voice profile of an individual and then combines them to pass them to the multi-entangled latent space to foster key-value pairs and queries for the audio and video modality generation pipeline. The multi-entangled latent space is responsible for establishing the spatiotemporal person-specific features between the modalities. Further, entangled features are passed to the respective decoder of each modality for output audio and video generation.