Rodent-Bench
作者: Thomas Heap, Laurence Aitchison, Emma Cahill, Adriana Casado Rodriguez
分类: cs.CV, cs.AI
发布日期: 2026-02-20
💡 一句话要点
Rodent-Bench:用于评估多模态大模型在啮齿动物行为标注能力的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 行为标注 啮齿动物行为 基准测试 视频分析
📋 核心要点
- 现有方法在自动标注啮齿动物行为视频方面存在不足,尤其是在处理长时间视频和区分细微行为状态时。
- Rodent-Bench基准旨在提供一个标准化的平台,用于评估和比较多模态大模型在啮齿动物行为标注任务中的性能。
- 实验结果表明,当前最先进的多模态大模型在Rodent-Bench上表现不佳,揭示了其在时间分割和行为识别方面的局限性。
📝 摘要(中文)
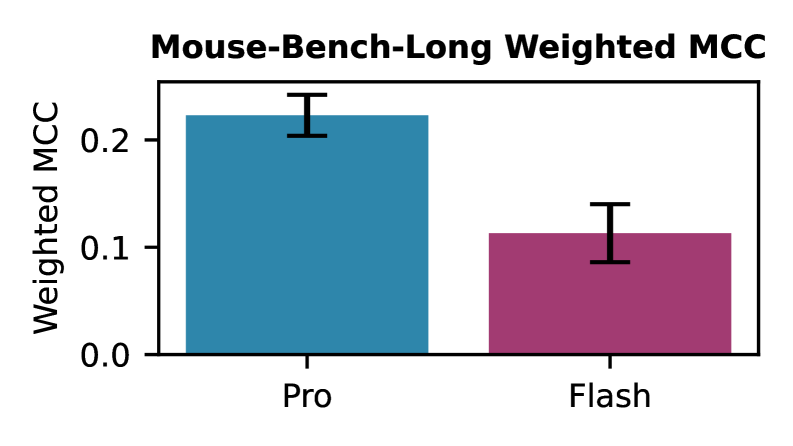
本文提出了Rodent-Bench,这是一个新的基准,旨在评估多模态大型语言模型(MLLM)标注啮齿动物行为视频的能力。我们使用该基准评估了最先进的MLLM,包括Gemini-2.5-Pro、Gemini-2.5-Flash和Qwen-VL-Max,发现这些模型都没有表现出足够强大的性能,无法用作该任务的助手。我们的基准包含多样化的数据集,涵盖多种行为范式,包括社交互动、梳理、抓挠和冻结行为,视频长度从10分钟到35分钟不等。我们提供了两个基准版本,以适应不同的模型能力,并建立了标准化的评估指标,包括秒级准确率、宏F1、平均精度均值、互信息和马修斯相关系数。虽然一些模型在某些数据集上表现出适度的性能(特别是梳理检测),但总体结果表明在时间分割、处理扩展视频序列和区分细微的行为状态方面存在重大挑战。我们的分析确定了当前MLLM在科学视频注释方面的主要局限性,并为未来的模型开发提供了见解。Rodent-Bench为跟踪神经科学研究中可靠的自动行为注释的进展奠定了基础。
🔬 方法详解
问题定义:论文旨在解决自动标注啮齿动物行为视频的问题。现有的方法,特别是依赖人工标注的方式,耗时且成本高昂。现有的多模态大模型在处理长时间视频、区分细微行为差异以及进行精确的时间分割方面存在不足,导致无法有效应用于该任务。
核心思路:论文的核心思路是构建一个标准化的基准测试集Rodent-Bench,用于系统性地评估多模态大模型在啮齿动物行为标注任务中的性能。通过提供多样化的数据集和标准化的评估指标,可以客观地衡量不同模型的能力,并促进相关算法的改进。
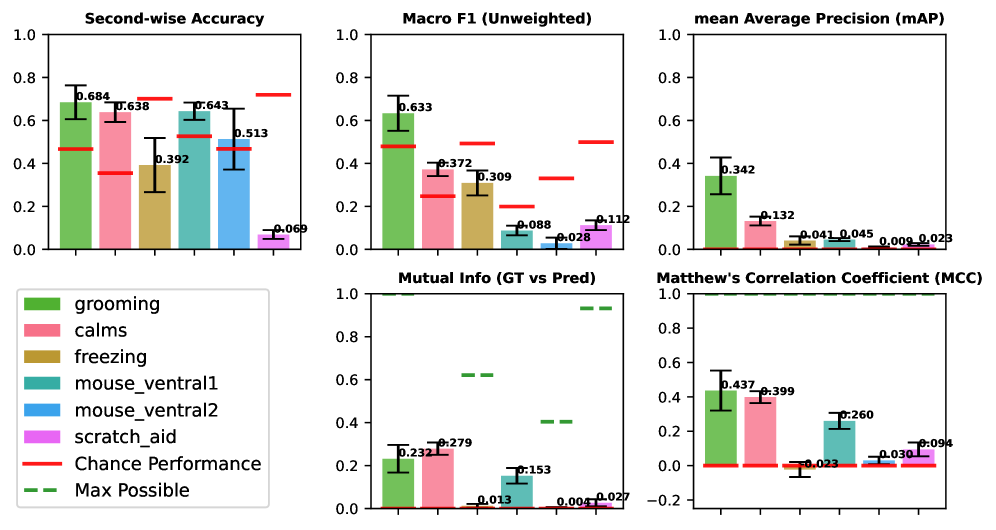
技术框架:Rodent-Bench包含多个啮齿动物行为视频数据集,涵盖社交互动、梳理、抓挠和冻结等多种行为。视频长度从10分钟到35分钟不等。基准测试提供了两个版本,以适应不同模型的能力。评估指标包括秒级准确率、宏F1、平均精度均值、互信息和马修斯相关系数,用于全面评估模型的性能。
关键创新:Rodent-Bench的关键创新在于其作为首个专门针对多模态大模型在啮齿动物行为标注任务上的评估基准。它提供了多样化的数据集和标准化的评估指标,为该领域的研究提供了一个统一的平台。
关键设计:Rodent-Bench包含两个版本,以适应不同模型的能力。数据集涵盖多种行为范式和视频长度,以评估模型在不同场景下的性能。评估指标的选择旨在全面衡量模型在时间分割、行为识别和整体性能方面的能力。具体参数设置和损失函数取决于被评估的多模态大模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,当前最先进的多模态大模型(包括Gemini-2.5-Pro、Gemini-2.5-Flash和Qwen-VL-Max)在Rodent-Bench上表现不佳,无法有效应用于啮齿动物行为的自动标注。虽然某些模型在梳理检测方面表现出适度的性能,但总体结果表明在时间分割和区分细微行为状态方面存在重大挑战。这些结果突出了当前多模态大模型在科学视频注释方面的局限性。
🎯 应用场景
Rodent-Bench的研究成果可应用于神经科学研究领域,实现啮齿动物行为的自动标注,从而加速行为实验的分析过程,降低人工成本。该基准的建立有助于推动多模态大模型在生物行为分析领域的应用,并为未来的模型开发提供指导。
📄 摘要(原文)
We present Rodent-Bench, a novel benchmark designed to evaluate the ability of Multimodal Large Language Models (MLLMs) to annotate rodent behaviour footage. We evaluate state-of-the-art MLLMs, including Gemini-2.5-Pro, Gemini-2.5-Flash and Qwen-VL-Max, using this benchmark and find that none of these models perform strongly enough to be used as an assistant for this task. Our benchmark encompasses diverse datasets spanning multiple behavioral paradigms including social interactions, grooming, scratching, and freezing behaviors, with videos ranging from 10 minutes to 35 minutes in length. We provide two benchmark versions to accommodate varying model capabilities and establish standardized evaluation metrics including second-wise accuracy, macro F1, mean average precision, mutual information, and Matthew's correlation coefficient. While some models show modest performance on certain datasets (notably grooming detection), overall results reveal significant challenges in temporal segmentation, handling extended video sequences, and distinguishing subtle behavioral states. Our analysis identifies key limitations in current MLLMs for scientific video annotation and provides insights for future model development. Rodent-Bench serves as a foundation for tracking progress toward reliable automated behavioral annotation in neuroscience research.