VLANeXt: Recipes for Building Strong VLA Models
作者: Xiao-Ming Wu, Bin Fan, Kang Liao, Jian-Jian Jiang, Runze Yang, Yihang Luo, Zhonghua Wu, Wei-Shi Zheng, Chen Change Loy
分类: cs.CV, cs.AI, cs.RO
发布日期: 2026-02-20
备注: 17 pages, 11 figures, Project Page: https://dravenalg.github.io/VLANeXt/
💡 一句话要点
VLANeXt:通过系统性实验,为构建强大的视觉-语言-动作模型提供有效方案。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 VLA模型 机器人学习 通用策略学习 模型设计空间 系统性研究 LIBERO基准 真实世界泛化
📋 核心要点
- 现有VLA模型训练协议和评估标准不统一,难以评估不同设计选择的有效性。
- 通过统一框架和评估,系统性地研究VLA模型设计空间,提炼关键设计原则。
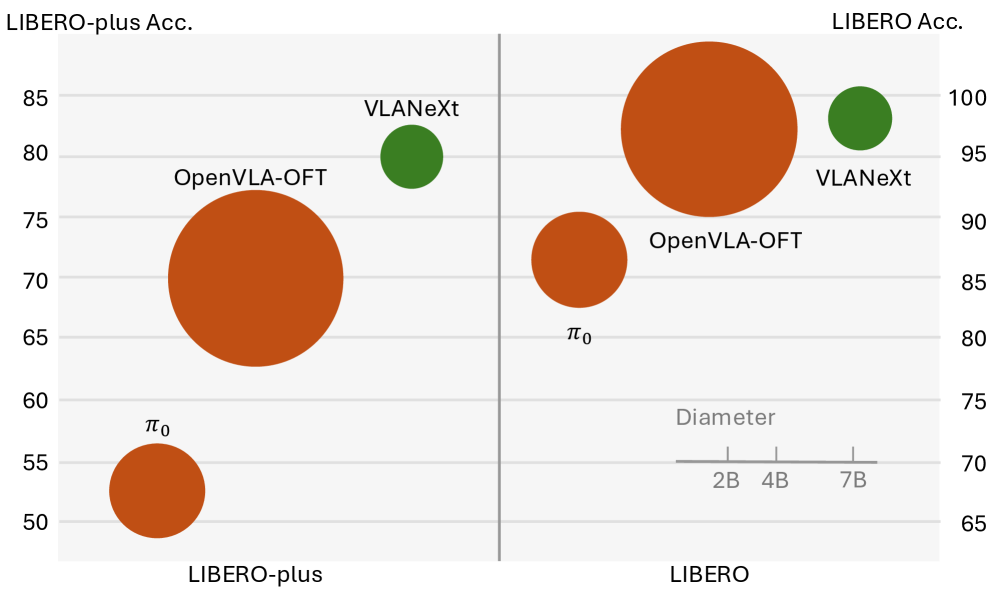
- 提出的VLANeXt模型在LIBERO和LIBERO-plus上超越现有SOTA,并在真实世界中表现出良好的泛化性。
📝 摘要(中文)
随着大型基础模型的兴起,视觉-语言-动作模型(VLA)应运而生,它利用强大的视觉和语言理解能力进行通用策略学习。然而,目前的VLA领域仍然分散且处于探索阶段。尽管许多团队提出了自己的VLA模型,但训练协议和评估设置的不一致使得难以确定哪些设计选择真正重要。为了给这个不断发展的领域带来结构,我们在统一的框架和评估设置下重新审视VLA设计空间。从类似于RT-2和OpenVLA的简单VLA基线开始,我们系统地剖析了三个维度上的设计选择:基础组件、感知要素和动作建模视角。通过这项研究,我们提炼出12个关键发现,共同构成了构建强大VLA模型的实用方案。这项探索的成果是一个简单而有效的模型,VLANeXt。VLANeXt在LIBERO和LIBERO-plus基准测试中优于先前的最先进方法,并在真实世界的实验中表现出强大的泛化能力。我们将发布一个统一的、易于使用的代码库,作为社区重现我们的发现、探索设计空间以及在共享基础上构建新的VLA变体的通用平台。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型领域缺乏统一的训练和评估标准,导致难以确定哪些设计选择对模型性能至关重要。不同的VLA模型在训练方式和评估指标上存在差异,使得比较和改进变得困难。现有方法难以有效指导VLA模型的开发和优化。
核心思路:该论文的核心思路是在统一的框架和评估设置下,系统性地研究VLA模型的设计空间。通过对基础组件、感知要素和动作建模等关键维度进行剖析,识别出影响模型性能的关键因素,并将其总结为构建强大VLA模型的实用方案。这种方法旨在提供一个清晰的指导,帮助研究人员和工程师更有效地构建和优化VLA模型。
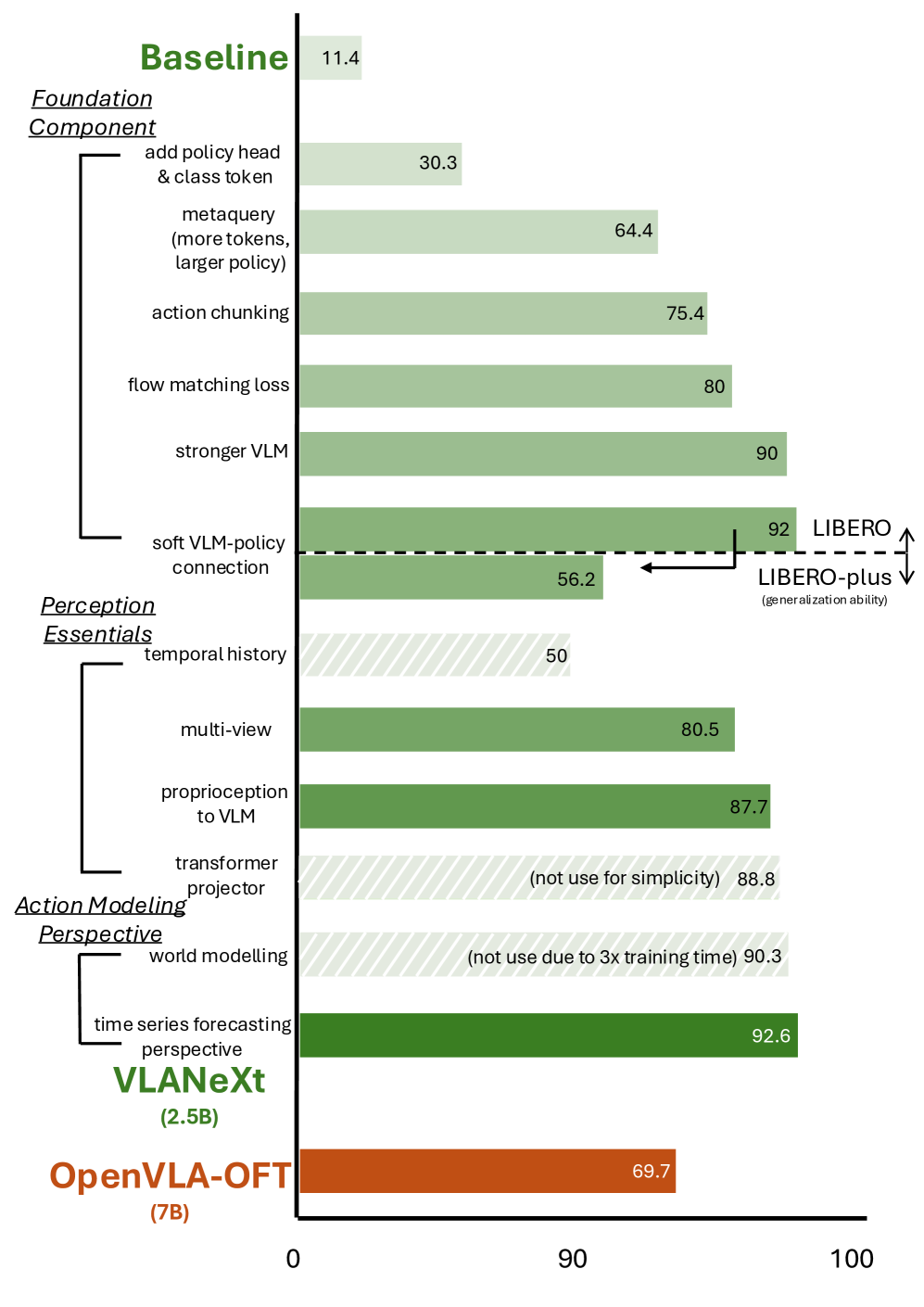
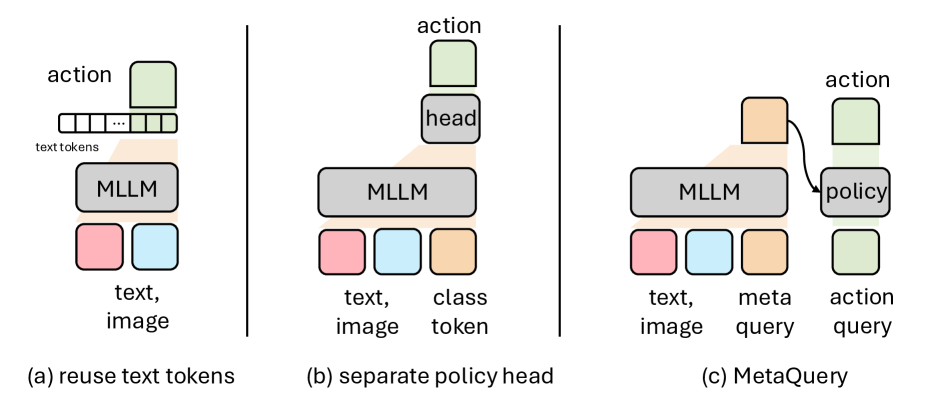
技术框架:该研究的技术框架包括以下几个主要步骤:1) 建立一个简单的VLA基线模型,类似于RT-2和OpenVLA。2) 在统一的框架和评估设置下,系统地剖析VLA模型的设计空间,包括基础组件(如Transformer架构)、感知要素(如视觉编码器)和动作建模视角(如动作预测方法)。3) 通过实验分析不同设计选择对模型性能的影响。4) 提炼出12个关键发现,并将其总结为构建强大VLA模型的实用方案。5) 基于这些发现,构建一个简单而有效的模型VLANeXt。
关键创新:该论文的关键创新在于其系统性的研究方法和对VLA模型设计空间的深入剖析。通过统一的框架和评估设置,该研究能够更准确地评估不同设计选择对模型性能的影响,从而识别出真正重要的因素。此外,该研究还提出了一个简单而有效的VLA模型VLANeXt,并在多个基准测试中取得了优异的性能。
关键设计:论文的关键设计包括:1) 统一的训练和评估流程,确保不同模型的比较公平有效。2) 对VLA模型设计空间进行系统性剖析,涵盖基础组件、感知要素和动作建模等关键维度。3) 基于实验结果,提炼出12个关键发现,为构建强大VLA模型提供指导。4) 提出的VLANeXt模型,其具体网络结构和参数设置在论文中详细描述,但摘要中未明确指出,需要查阅论文全文。
🖼️ 关键图片
📊 实验亮点
VLANeXt在LIBERO和LIBERO-plus基准测试中超越了先前的SOTA方法,证明了其有效性。此外,VLANeXt在真实世界的实验中表现出强大的泛化能力,表明其具有实际应用潜力。论文还将发布统一的代码库,方便社区复现结果和进一步研究。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、智能助手等领域。通过构建强大的VLA模型,可以使机器更好地理解人类指令,并执行复杂的任务。该研究为VLA模型的开发和优化提供了有价值的指导,有望推动相关领域的快速发展。
📄 摘要(原文)
Following the rise of large foundation models, Vision-Language-Action models (VLAs) emerged, leveraging strong visual and language understanding for general-purpose policy learning. Yet, the current VLA landscape remains fragmented and exploratory. Although many groups have proposed their own VLA models, inconsistencies in training protocols and evaluation settings make it difficult to identify which design choices truly matter. To bring structure to this evolving space, we reexamine the VLA design space under a unified framework and evaluation setup. Starting from a simple VLA baseline similar to RT-2 and OpenVLA, we systematically dissect design choices along three dimensions: foundational components, perception essentials, and action modelling perspectives. From this study, we distill 12 key findings that together form a practical recipe for building strong VLA models. The outcome of this exploration is a simple yet effective model, VLANeXt. VLANeXt outperforms prior state-of-the-art methods on the LIBERO and LIBERO-plus benchmarks and demonstrates strong generalization in real-world experiments. We will release a unified, easy-to-use codebase that serves as a common platform for the community to reproduce our findings, explore the design space, and build new VLA variants on top of a shared foundation.