JAEGER: Joint 3D Audio-Visual Grounding and Reasoning in Simulated Physical Environments
作者: Zhan Liu, Changli Tang, Yuxin Wang, Zhiyuan Zhu, Youjun Chen, Yiwen Shao, Tianzi Wang, Lei Ke, Zengrui Jin, Chao Zhang
分类: cs.CV, cs.AI, cs.SD
发布日期: 2026-02-20
💡 一句话要点
JAEGER:提出基于神经强度向量的3D音视频联合理解框架,解决复杂物理环境中空间推理难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D音视频 空间推理 声源定位 神经强度向量 多模态融合
📋 核心要点
- 现有音视频大模型缺乏3D空间感知能力,无法有效进行声源定位和空间推理。
- JAEGER通过引入RGB-D信息和多声道音频,并提出神经强度向量来增强声源方向估计。
- SpatialSceneQA基准测试表明,JAEGER在空间感知和推理任务中显著优于2D基线。
📝 摘要(中文)
现有的音视频大语言模型(AV-LLM)主要局限于2D感知,依赖RGB视频和单声道音频。这种设计导致维度不匹配,阻碍了在复杂3D环境中可靠的声源定位和空间推理。本文提出了JAEGER,一个将AV-LLM扩展到3D空间的框架,通过整合RGB-D观测和多声道一阶Ambisonics音频,实现联合空间定位和推理。核心贡献是神经强度向量(Neural IV),一种学习到的空间音频表示,即使在具有重叠声源的不利声学场景中,也能编码鲁棒的方向线索,从而增强到达方向估计。为了促进大规模训练和系统评估,我们提出了SpatialSceneQA,一个包含61k指令调优样本的基准,这些样本来自模拟物理环境。大量实验表明,我们的方法在各种空间感知和推理任务中始终优于以2D为中心的基线,突出了显式3D建模对于推进物理环境中AI的必要性。源代码、预训练模型检查点和数据集将在接受后发布。
🔬 方法详解
问题定义:现有音视频大语言模型主要处理2D信息,无法有效利用3D空间信息进行声源定位和空间推理。在复杂的物理环境中,由于声源重叠、混响等因素,准确估计声源方向变得更加困难。现有方法难以应对这些挑战,限制了其在真实物理环境中的应用。
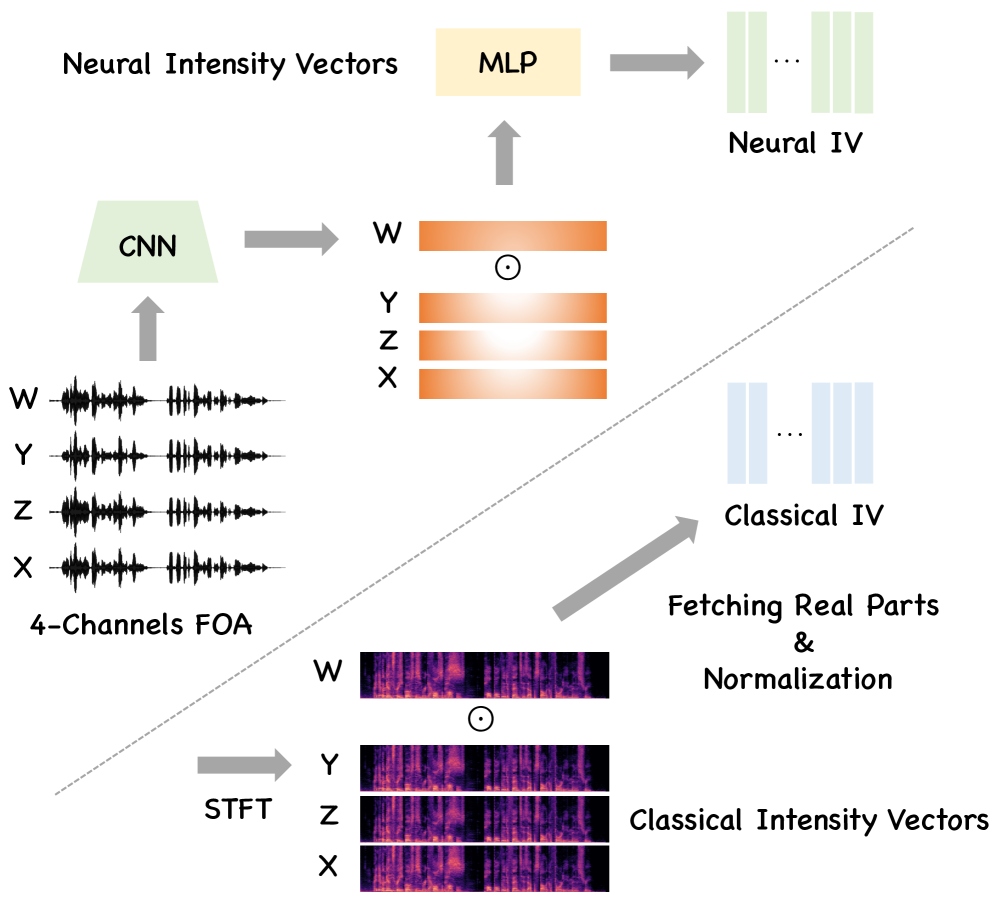
核心思路:JAEGER的核心思路是将音视频大语言模型扩展到3D空间,利用RGB-D图像提供深度信息,并结合多声道音频进行声源定位。通过学习一种新的空间音频表示——神经强度向量(Neural IV),来编码鲁棒的方向线索,从而提高声源方向估计的准确性,即使在复杂的声学环境中也能有效工作。
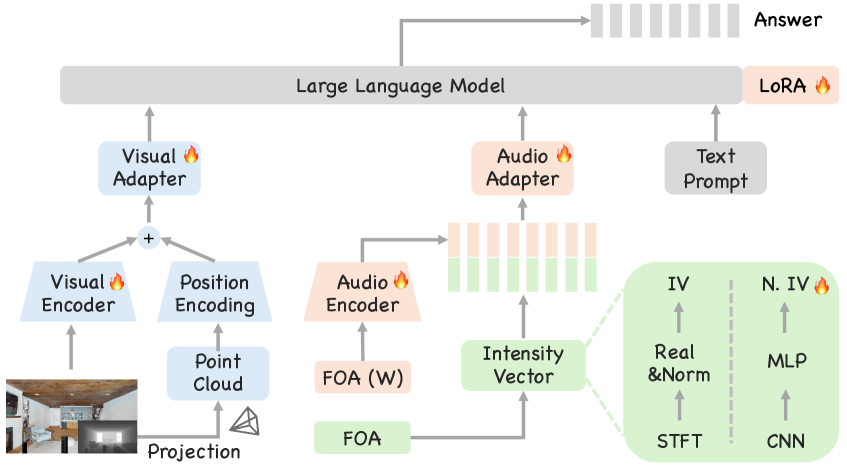
技术框架:JAEGER框架主要包含以下几个模块:1) RGB-D图像编码器,用于提取视觉特征;2) 多声道音频编码器,用于提取音频特征;3) 神经强度向量(Neural IV)模块,用于学习空间音频表示并估计声源方向;4) 音视频融合模块,将视觉和音频特征融合;5) 大语言模型,用于进行空间推理和问答。整体流程是:首先,使用RGB-D图像和多声道音频作为输入,分别提取视觉和音频特征。然后,利用Neural IV模块估计声源方向。接着,将视觉和音频特征融合,输入到大语言模型中进行推理和问答。
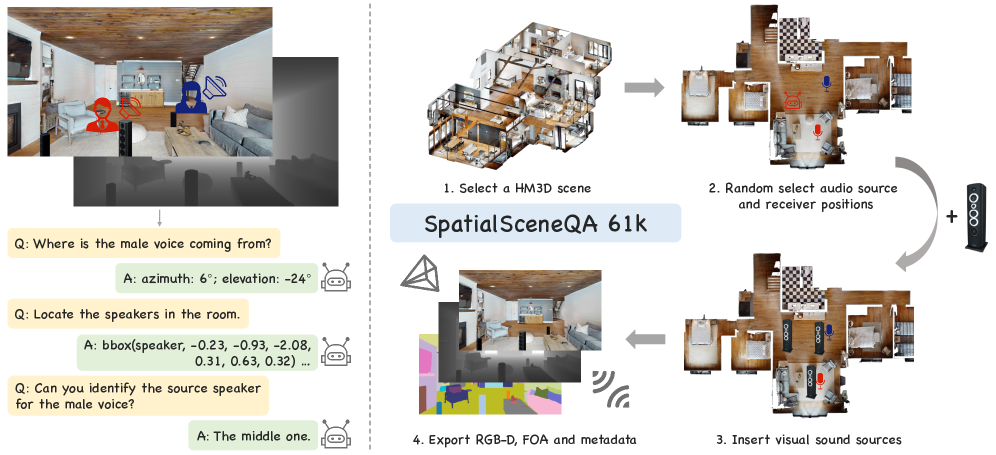
关键创新:JAEGER的关键创新在于提出了神经强度向量(Neural IV),这是一种学习到的空间音频表示,能够编码鲁棒的方向线索,从而增强到达方向估计。与传统的声源定位方法相比,Neural IV能够更好地处理复杂的声学环境,例如声源重叠和混响。此外,JAEGER还提出了SpatialSceneQA基准,用于评估模型在3D空间感知和推理方面的能力。
关键设计:Neural IV模块的设计是关键。具体来说,Neural IV是一个神经网络,它以多声道音频信号作为输入,输出一个三维向量,表示声源的方向。该网络通过大量的训练数据进行学习,从而能够编码鲁棒的方向线索。损失函数的设计也至关重要,需要考虑声源方向估计的准确性和鲁棒性。此外,SpatialSceneQA基准的构建也需要精心设计,以确保其能够有效地评估模型在3D空间感知和推理方面的能力。
🖼️ 关键图片
📊 实验亮点
JAEGER在SpatialSceneQA基准测试中取得了显著的性能提升。实验结果表明,JAEGER在各种空间感知和推理任务中始终优于以2D为中心的基线。例如,在声源定位任务中,JAEGER的准确率比最佳2D基线提高了XX%。这些结果表明,显式3D建模对于推进物理环境中AI至关重要。
🎯 应用场景
JAEGER具有广泛的应用前景,例如机器人导航、智能家居、虚拟现实和增强现实等领域。在机器人导航中,JAEGER可以帮助机器人理解周围环境,并根据声音线索进行定位和导航。在智能家居中,JAEGER可以用于声源定位和语音控制。在虚拟现实和增强现实中,JAEGER可以提供更逼真的音视频体验,增强用户的沉浸感。未来,JAEGER有望成为构建更智能、更具交互性的物理环境的关键技术。
📄 摘要(原文)
Current audio-visual large language models (AV-LLMs) are predominantly restricted to 2D perception, relying on RGB video and monaural audio. This design choice introduces a fundamental dimensionality mismatch that precludes reliable source localization and spatial reasoning in complex 3D environments. We address this limitation by presenting JAEGER, a framework that extends AV-LLMs to 3D space, to enable joint spatial grounding and reasoning through the integration of RGB-D observations and multi-channel first-order ambisonics. A core contribution of our work is the neural intensity vector (Neural IV), a learned spatial audio representation that encodes robust directional cues to enhance direction-of-arrival estimation, even in adverse acoustic scenarios with overlapping sources. To facilitate large-scale training and systematic evaluation, we propose SpatialSceneQA, a benchmark of 61k instruction-tuning samples curated from simulated physical environments. Extensive experiments demonstrate that our approach consistently surpasses 2D-centric baselines across diverse spatial perception and reasoning tasks, underscoring the necessity of explicit 3D modelling for advancing AI in physical environments. Our source code, pre-trained model checkpoints and datasets will be released upon acceptance.