SARAH: Spatially Aware Real-time Agentic Humans
作者: Evonne Ng, Siwei Zhang, Zhang Chen, Michael Zollhoefer, Alexander Richard
分类: cs.CV
发布日期: 2026-02-20
备注: Project page: https://evonneng.github.io/sarah/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SARAH:提出一种空间感知实时Agentic人类建模方法,用于VR和数字人应用。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 空间感知 实时动作生成 具身智能体 VR/AR Transformer VAE Flow Matching 因果模型 人机交互
📋 核心要点
- 现有方法在VR和数字人应用中,无法使智能体根据用户位置和行为做出自然的空间感知反应,限制了交互的真实感。
- SARAH提出了一种实时的、完全因果的空间感知对话运动生成方法,通过结合Transformer VAE和Flow Matching模型,实现自然的人机交互。
- 实验表明,SARAH在运动质量上达到了SOTA,速度超过300FPS,比非因果基线快3倍,并在实时VR系统中验证了其有效性。
📝 摘要(中文)
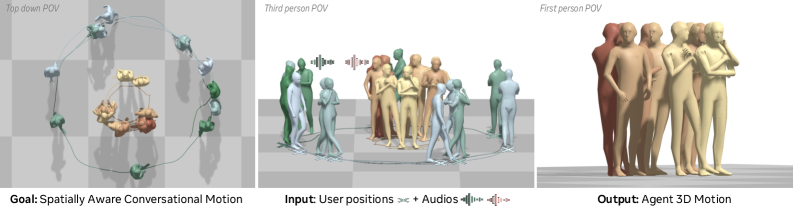
随着具身智能体在VR、远程呈现和数字人应用中变得至关重要,它们的运动必须超越与语音对齐的手势:智能体应该转向用户,响应他们的运动,并保持自然的目光。目前的方法缺乏这种空间感知能力。我们通过第一个实时的、完全因果的空间感知对话运动方法来弥补这一差距,该方法可以部署在流式VR头显上。给定用户的位置和双耳音频,我们的方法产生全身运动,使手势与语音对齐,同时根据用户调整智能体的朝向。我们的架构结合了一个基于因果Transformer的VAE,其中穿插了用于流式推理的潜在token,以及一个以用户轨迹和音频为条件的Flow Matching模型。为了支持不同的目光偏好,我们引入了一种带有无分类器引导的目光评分机制,以将学习与控制分离:该模型从数据中捕获自然的空问对齐,而用户可以在推理时调整眼神交流强度。在Embody 3D数据集上,我们的方法以超过300 FPS的速度实现了最先进的运动质量——比非因果基线快3倍——同时捕捉了自然对话中微妙的空间动态。我们在一个实时的VR系统中验证了我们的方法,将空间感知的对话智能体带到了实时部署中。
🔬 方法详解
问题定义:现有方法在生成虚拟人物的对话动作时,缺乏对用户空间位置的感知能力。这意味着虚拟人物无法根据用户的移动和位置调整其姿态、朝向和目光,导致交互体验不自然。现有方法要么是非实时的,要么无法捕捉到细微的空间动态。
核心思路:SARAH的核心思路是利用因果模型,根据用户的实时位置和语音输入,生成与语音同步且具有空间感知能力的虚拟人物动作。通过解耦学习和控制,允许用户在推理时调整眼神交流强度,从而实现更个性化的交互体验。
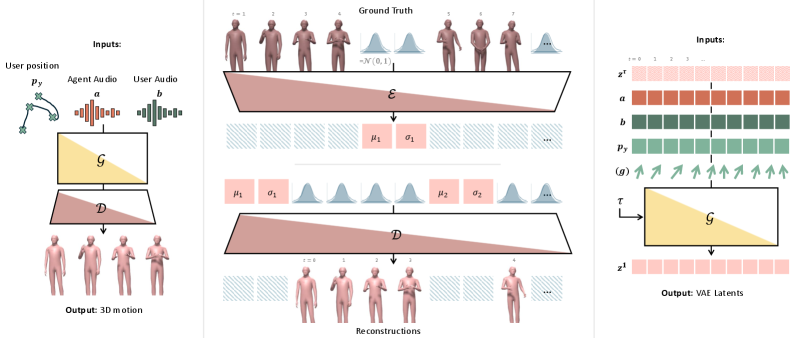
技术框架:SARAH的整体架构包含以下几个主要模块:1) 一个基于因果Transformer的VAE,用于生成与语音对齐的手势;2) 一个Flow Matching模型,用于根据用户轨迹和音频调整虚拟人物的全身运动;3) 一个目光评分机制,用于控制虚拟人物的眼神交流强度。整个流程是实时的,可以部署在流式VR头显上。
关键创新:SARAH的关键创新在于其完全因果的设计,这使得它能够进行实时的流式推理。此外,目光评分机制允许用户在推理时调整眼神交流强度,从而实现更灵活的控制。将Transformer VAE和Flow Matching模型结合,实现了高质量且具有空间感知能力的动作生成。
关键设计:SARAH使用因果Transformer VAE来捕捉语音和手势之间的关系,并使用穿插的潜在token来实现流式推理。Flow Matching模型以用户轨迹和音频为条件,生成全身运动。目光评分机制使用分类器无关的引导,允许用户在推理时调整眼神交流强度。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
SARAH在Embody 3D数据集上实现了最先进的运动质量,并且能够以超过300 FPS的速度运行,比非因果基线快3倍。这表明SARAH不仅能够生成高质量的动作,而且具有很高的实时性,使其能够部署在实际的VR系统中。在实时VR系统中的验证也证明了SARAH的有效性。
🎯 应用场景
SARAH具有广泛的应用前景,包括VR/AR中的虚拟助手、远程呈现系统、数字人交互、游戏角色控制等。它可以提升人机交互的自然性和沉浸感,使虚拟人物能够更真实地响应用户的行为和情感,从而改善用户体验。未来,SARAH可以进一步扩展到更多模态的输入,例如面部表情、肢体语言等,以实现更丰富的交互。
📄 摘要(原文)
As embodied agents become central to VR, telepresence, and digital human applications, their motion must go beyond speech-aligned gestures: agents should turn toward users, respond to their movement, and maintain natural gaze. Current methods lack this spatial awareness. We close this gap with the first real-time, fully causal method for spatially-aware conversational motion, deployable on a streaming VR headset. Given a user's position and dyadic audio, our approach produces full-body motion that aligns gestures with speech while orienting the agent according to the user. Our architecture combines a causal transformer-based VAE with interleaved latent tokens for streaming inference and a flow matching model conditioned on user trajectory and audio. To support varying gaze preferences, we introduce a gaze scoring mechanism with classifier-free guidance to decouple learning from control: the model captures natural spatial alignment from data, while users can adjust eye contact intensity at inference time. On the Embody 3D dataset, our method achieves state-of-the-art motion quality at over 300 FPS -- 3x faster than non-causal baselines -- while capturing the subtle spatial dynamics of natural conversation. We validate our approach on a live VR system, bringing spatially-aware conversational agents to real-time deployment. Please see https://evonneng.github.io/sarah/ for details.