Generated Reality: Human-centric World Simulation using Interactive Video Generation with Hand and Camera Control
作者: Linxi Xie, Lisong C. Sun, Ashley Neall, Tong Wu, Shengqu Cai, Gordon Wetzstein
分类: cs.CV
发布日期: 2026-02-20
备注: Project page here: https://codeysun.github.io/generated-reality
💡 一句话要点
提出基于手部和相机控制的交互式视频生成方法,用于人机交互世界模拟。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视频生成 扩散模型 人机交互 扩展现实 手部姿势估计 头部姿势估计 知识蒸馏 具身智能
📋 核心要点
- 现有视频世界模型控制信号粗糙,无法满足扩展现实中对具身交互的需求。
- 提出一种以人为中心的视频世界模型,通过头部和手部姿势控制生成虚拟环境。
- 实验表明,该系统能有效提高任务性能,并增强用户对动作的控制感。
📝 摘要(中文)
扩展现实(XR)需要能够响应用户跟踪的真实世界运动的生成模型,但当前的视频世界模型只接受粗略的控制信号,如文本或键盘输入,限制了它们在具身交互中的效用。本文提出了一种以人为中心的视频世界模型,该模型以跟踪的头部姿势和关节级的手部姿势为条件。为此,我们评估了现有的扩散Transformer条件策略,并提出了一种有效的3D头部和手部控制机制,从而实现灵巧的手部-物体交互。我们使用这种策略训练了一个双向视频扩散模型教师,并将其提炼成一个因果的、交互式的系统,该系统生成以自我为中心的虚拟环境。我们用人类受试者评估了这个生成的现实系统,并证明了与相关的基线相比,任务性能得到了提高,并且对所执行的动作的感知控制水平也显著提高。
🔬 方法详解
问题定义:现有视频世界模型主要依赖文本或键盘等粗略控制信号,无法实现自然、流畅的具身交互。在扩展现实(XR)应用中,用户需要通过头部和手部的精细动作与虚拟环境进行交互,而现有模型难以满足这种需求。因此,如何构建一个能够响应用户头部和手部运动的、可交互的视频生成模型是本文要解决的核心问题。
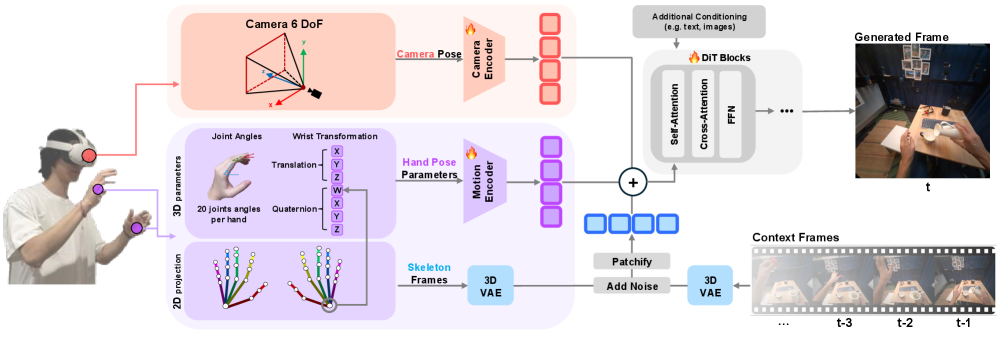
核心思路:本文的核心思路是利用扩散模型强大的生成能力,并将其与头部和手部姿势的精确控制相结合。通过将头部姿势和手部姿势作为条件输入,引导扩散模型生成与用户动作相一致的视频内容。此外,采用知识蒸馏技术,将离线的双向扩散模型转化为在线的、因果的交互式系统。
技术框架:该方法包含以下主要模块:1) 数据收集:收集包含头部姿势和手部姿势的视频数据。2) 双向扩散模型训练:使用收集到的数据训练一个双向视频扩散模型,该模型以头部姿势和手部姿势为条件。3) 知识蒸馏:将训练好的双向扩散模型蒸馏成一个因果的、交互式的系统。4) 交互式视频生成:用户通过头部和手部运动与系统交互,系统根据用户的动作生成相应的视频内容。
关键创新:本文的关键创新在于提出了一种有效的3D头部和手部控制机制,用于条件化视频扩散模型。该机制能够精确地控制生成视频中头部和手部的运动,从而实现灵巧的手部-物体交互。此外,通过知识蒸馏,将离线的双向扩散模型转化为在线的交互式系统,提高了系统的实用性。
关键设计:在扩散模型方面,采用了扩散Transformer架构。在条件控制方面,设计了一种专门的3D头部和手部控制机制,具体细节未知。在知识蒸馏方面,采用了标准的蒸馏训练方法,目标是最小化学生模型和教师模型之间的输出差异。损失函数未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与相关基线相比,该系统在任务性能方面有所提高,并且用户对所执行的动作的感知控制水平也显著提高。具体的性能数据和提升幅度未知,但主观评价显示用户对系统的交互体验感到满意。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏等领域,为用户提供更加沉浸式和交互式的体验。例如,用户可以在虚拟环境中通过手势操作物体,进行绘画、组装等任务。未来,该技术有望应用于远程协作、教育培训等领域,实现更加高效和自然的远程交互。
📄 摘要(原文)
Extended reality (XR) demands generative models that respond to users' tracked real-world motion, yet current video world models accept only coarse control signals such as text or keyboard input, limiting their utility for embodied interaction. We introduce a human-centric video world model that is conditioned on both tracked head pose and joint-level hand poses. For this purpose, we evaluate existing diffusion transformer conditioning strategies and propose an effective mechanism for 3D head and hand control, enabling dexterous hand--object interactions. We train a bidirectional video diffusion model teacher using this strategy and distill it into a causal, interactive system that generates egocentric virtual environments. We evaluate this generated reality system with human subjects and demonstrate improved task performance as well as a significantly higher level of perceived amount of control over the performed actions compared with relevant baselines.