Self-Aware Object Detection via Degradation Manifolds
作者: Stefan Becker, Simon Weiss, Wolfgang Hübner, Michael Arens
分类: cs.CV
发布日期: 2026-02-20
💡 一句话要点
提出基于退化流形的自感知目标检测框架,解决恶劣条件下检测器失效问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自感知目标检测 退化流形 对比学习 领域泛化 鲁棒性
📋 核心要点
- 现有目标检测器在恶劣成像条件下性能显著下降,且缺乏对自身预测可靠性的评估能力。
- 论文提出基于退化流形的自感知框架,通过对比学习构建退化感知的特征空间,实现对图像退化的内在评估。
- 实验表明,该方法在合成退化、跨数据集迁移和自然天气变化等场景下均表现出良好的原始-退化可分离性和泛化能力。
📝 摘要(中文)
目标检测器在理想成像条件下表现出色,但在模糊、噪声、压缩、恶劣天气或分辨率变化等情况下可能会失效。在安全攸关的场景中,仅生成预测是不够的,还需要评估输入是否仍在检测器的正常工作范围内。我们将这种能力称为自感知目标检测。本文提出了一种基于退化流形的自感知框架,该框架根据图像退化而非语义内容显式地构建检测器的特征空间。我们的方法通过多层对比学习,用一个轻量级的嵌入头来增强标准的检测骨干网络。共享相同退化组成的图像被拉到一起,而不同的退化配置被推开,从而产生一个几何组织化的表示,该表示捕获退化类型和严重程度,而无需退化标签或显式密度建模。为了锚定学习到的几何结构,我们从干净的训练嵌入中估计一个原始原型,从而在表示空间中定义一个标称工作点。自感知表现为与该参考的几何偏差,提供了一个内在的、图像级的退化诱导偏移信号,该信号独立于检测置信度。在合成损坏基准、跨数据集零样本迁移和自然天气诱导的分布偏移上的大量实验表明,原始-退化可分离性强,在多个检测器架构中行为一致,并且在语义偏移下具有鲁棒的泛化能力。这些结果表明,退化感知的表示几何结构提供了一个实用且与检测器无关的基础。
🔬 方法详解
问题定义:现有目标检测器在理想条件下表现良好,但在实际应用中,图像常常受到各种退化的影响,如模糊、噪声、压缩等。这些退化会导致检测器性能显著下降,甚至完全失效。更重要的是,检测器通常无法意识到自身预测的不可靠性,这在安全攸关的应用中是不可接受的。因此,如何使目标检测器具备自感知能力,即能够判断输入图像是否在其正常工作范围内,是一个重要的研究问题。
核心思路:论文的核心思路是构建一个退化感知的特征空间,使得具有相似退化的图像在特征空间中彼此靠近,而具有不同退化的图像彼此远离。通过这种方式,检测器可以学习到图像退化与特征空间几何结构之间的关系。然后,通过定义一个“原始”原型,即干净图像在特征空间中的表示,检测器可以通过测量输入图像的特征与原始原型之间的距离来判断图像的退化程度。
技术框架:该方法在标准的目标检测骨干网络上增加了一个轻量级的嵌入头。该嵌入头通过多层对比学习进行训练,其目标是将具有相似退化的图像的嵌入拉近,并将具有不同退化的图像的嵌入推远。训练完成后,对于给定的输入图像,首先通过骨干网络和嵌入头提取其特征表示,然后计算该特征表示与原始原型之间的距离。该距离被用作图像退化程度的度量,从而实现自感知目标检测。
关键创新:该方法最重要的创新点在于它显式地构建了一个退化感知的特征空间,而不是像传统方法那样只关注语义内容。通过这种方式,检测器可以学习到图像退化与特征空间几何结构之间的关系,从而实现对图像退化的内在评估。此外,该方法不需要退化标签或显式密度建模,使其更易于应用。
关键设计:该方法使用多层对比学习来训练嵌入头。对比学习的目标是最小化正样本对之间的距离,并最大化负样本对之间的距离。正样本对是指具有相似退化的图像对,而负样本对是指具有不同退化的图像对。损失函数通常采用InfoNCE损失或类似的对比损失函数。此外,原始原型的估计方法也很重要,通常可以通过计算干净训练图像嵌入的均值或中值来获得。
🖼️ 关键图片

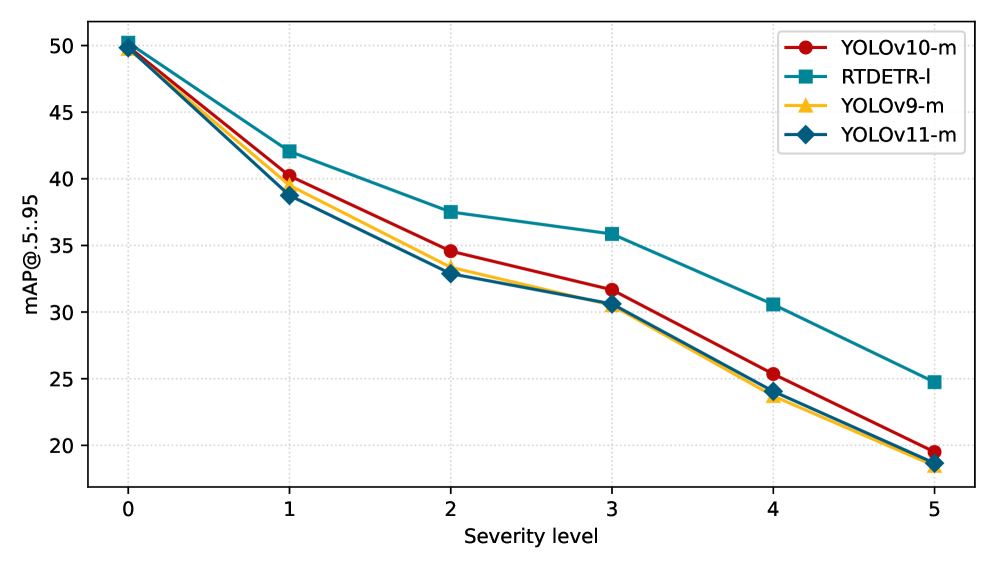
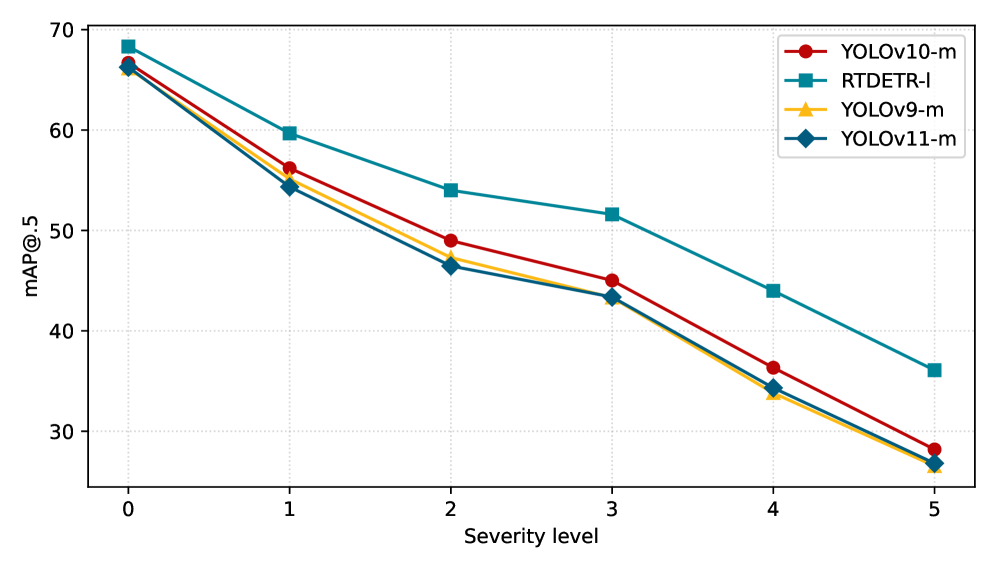
📊 实验亮点
论文在合成损坏基准测试、跨数据集零样本迁移和自然天气引起的分布偏移上进行了广泛的实验。实验结果表明,该方法能够有效地分离原始图像和退化图像,并且在不同的检测器架构中表现出一致的性能。此外,该方法在语义偏移下也表现出鲁棒的泛化能力,证明了其在实际应用中的潜力。
🎯 应用场景
该研究成果可应用于自动驾驶、安防监控、医学影像等安全攸关领域。通过提高目标检测器在恶劣条件下的鲁棒性和自感知能力,可以有效降低误检和漏检的风险,提升系统的可靠性和安全性。未来,该方法还可以扩展到其他视觉任务中,如图像分类、图像分割等。
📄 摘要(原文)
Object detectors achieve strong performance under nominal imaging conditions but can fail silently when exposed to blur, noise, compression, adverse weather, or resolution changes. In safety-critical settings, it is therefore insufficient to produce predictions without assessing whether the input remains within the detector's nominal operating regime. We refer to this capability as self-aware object detection. We introduce a degradation-aware self-awareness framework based on degradation manifolds, which explicitly structure a detector's feature space according to image degradation rather than semantic content. Our method augments a standard detection backbone with a lightweight embedding head trained via multi-layer contrastive learning. Images sharing the same degradation composition are pulled together, while differing degradation configurations are pushed apart, yielding a geometrically organized representation that captures degradation type and severity without requiring degradation labels or explicit density modeling. To anchor the learned geometry, we estimate a pristine prototype from clean training embeddings, defining a nominal operating point in representation space. Self-awareness emerges as geometric deviation from this reference, providing an intrinsic, image-level signal of degradation-induced shift that is independent of detection confidence. Extensive experiments on synthetic corruption benchmarks, cross-dataset zero-shot transfer, and natural weather-induced distribution shifts demonstrate strong pristine-degraded separability, consistent behavior across multiple detector architectures, and robust generalization under semantic shift. These results suggest that degradation-aware representation geometry provides a practical and detector-agnostic foundation.