On the Adversarial Robustness of Discrete Image Tokenizers
作者: Rishika Bhagwatkar, Irina Rish, Nicolas Flammarion, Francesco Croce
分类: cs.CV, cs.AI
发布日期: 2026-02-20
💡 一句话要点
研究离散图像Tokenizers的对抗鲁棒性,提出高效攻击与无监督防御方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 对抗防御 离散图像Tokenizer 多模态学习 无监督学习
📋 核心要点
- 现有离散图像Tokenizer在多模态任务中应用广泛,但其对抗鲁棒性研究不足,易受攻击。
- 提出一种高效且与应用无关的对抗攻击方法,旨在扰乱Tokenizer提取的特征,改变输出tokens。
- 采用无监督对抗训练微调Tokenizer,显著提升了模型对对抗攻击的鲁棒性,并具有良好的泛化能力。
📝 摘要(中文)
离散图像Tokenizers将视觉输入编码为有限词汇表中的tokens序列,并在多模态系统中日益普及,包括仅编码器、编码器-解码器和仅解码器模型。然而,与CLIP编码器不同,它们对对抗攻击的脆弱性尚未被探索。本研究首次探讨了这一问题,首先提出了旨在扰乱离散Tokenizer提取的特征,从而改变提取的tokens的攻击方法。这些攻击方法计算效率高,与应用无关,并且在分类、多模态检索和图像描述任务中有效。其次,为了防御这种脆弱性,受到最近关于鲁棒CLIP编码器工作的启发,我们使用无监督对抗训练对流行的Tokenizers进行微调,同时保持所有其他组件冻结。虽然是无监督且与任务无关的,但我们的方法显著提高了对无监督和端到端监督攻击的鲁棒性,并且能够很好地泛化到未见过的任务和数据。与监督对抗训练不同,我们的方法可以利用未标记的图像,使其更具通用性。总的来说,我们的工作强调了Tokenizer鲁棒性在下游任务中的关键作用,并为开发安全的多模态基础模型迈出了重要一步。
🔬 方法详解
问题定义:论文旨在解决离散图像Tokenizer在对抗攻击下的脆弱性问题。现有方法,如CLIP模型,已经研究了对抗鲁棒性,但离散图像Tokenizer的鲁棒性尚未被充分探索。这使得基于Tokenizer的多模态系统容易受到恶意攻击,影响其在实际应用中的安全性。
核心思路:论文的核心思路是通过对抗攻击来评估Tokenizer的脆弱性,并利用无监督对抗训练来提高其鲁棒性。通过生成对抗样本来扰乱Tokenizer提取的特征,迫使模型学习更鲁棒的特征表示。无监督训练的优势在于可以利用大量的未标记数据,提高模型的泛化能力。
技术框架:整体框架包括两个主要部分:对抗攻击和对抗防御。对抗攻击部分,设计了针对Tokenizer特征的攻击方法,旨在改变提取的tokens。对抗防御部分,采用无监督对抗训练,通过生成对抗样本并将其输入Tokenizer进行训练,从而提高模型的鲁棒性。整个过程保持下游任务的组件冻结,只训练Tokenizer。
关键创新:最重要的技术创新点在于提出了针对离散图像Tokenizer的对抗攻击方法,并采用无监督对抗训练来提高其鲁棒性。与传统的监督对抗训练相比,无监督方法可以利用未标记数据,更具通用性。此外,该方法是应用无关的,可以应用于各种下游任务。
关键设计:在对抗攻击方面,设计了能够有效扰乱Tokenizer特征的攻击算法,具体细节未知。在对抗训练方面,采用了无监督的方式,损失函数的设计目标是使模型在对抗样本上的表现尽可能接近原始样本。Tokenizer的具体网络结构和参数设置取决于所使用的预训练模型,论文中使用了流行的Tokenizer,并对其进行了微调。
🖼️ 关键图片
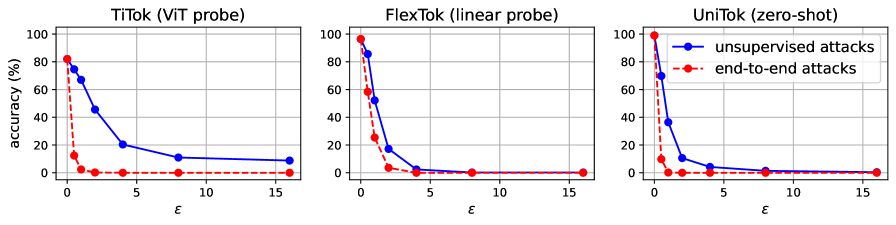


📊 实验亮点
实验结果表明,提出的对抗攻击方法能够有效攻击离散图像Tokenizer,导致下游任务性能显著下降。通过无监督对抗训练,Tokenizer的鲁棒性得到了显著提升,在各种下游任务中均表现出良好的泛化能力。具体性能数据未知,但论文强调了鲁棒性的显著提升。
🎯 应用场景
该研究成果可应用于各种多模态系统中,例如图像描述、视觉问答、多模态检索等。提高Tokenizer的鲁棒性有助于增强这些系统在对抗环境下的安全性,防止恶意攻击,保障用户体验。此外,该研究为开发更安全可靠的多模态基础模型提供了重要参考。
📄 摘要(原文)
Discrete image tokenizers encode visual inputs as sequences of tokens from a finite vocabulary and are gaining popularity in multimodal systems, including encoder-only, encoder-decoder, and decoder-only models. However, unlike CLIP encoders, their vulnerability to adversarial attacks has not been explored. Ours being the first work studying this topic, we first formulate attacks that aim to perturb the features extracted by discrete tokenizers, and thus change the extracted tokens. These attacks are computationally efficient, application-agnostic, and effective across classification, multimodal retrieval, and captioning tasks. Second, to defend against this vulnerability, inspired by recent work on robust CLIP encoders, we fine-tune popular tokenizers with unsupervised adversarial training, keeping all other components frozen. While unsupervised and task-agnostic, our approach significantly improves robustness to both unsupervised and end-to-end supervised attacks and generalizes well to unseen tasks and data. Unlike supervised adversarial training, our approach can leverage unlabeled images, making it more versatile. Overall, our work highlights the critical role of tokenizer robustness in downstream tasks and presents an important step in the development of safe multimodal foundation models.