3DMedAgent: Unified Perception-to-Understanding for 3D Medical Analysis
作者: Ziyue Wang, Linghan Cai, Chang Han Low, Haofeng Liu, Junde Wu, Jingyu Wang, Rui Wang, Lei Song, Jiang Bian, Jingjing Fu, Yueming Jin
分类: cs.CV
发布日期: 2026-02-20
备注: 19 pages, 7 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出3DMedAgent,利用2D MLLM实现3D医学影像的统一感知与理解。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D医学影像分析 多模态学习 大型语言模型 临床理解 智能代理
📋 核心要点
- 现有3D医学影像分析方法缺乏对感知证据的系统积累,限制了下游推理能力。
- 3DMedAgent利用2D MLLM,通过分解任务和维护长期记忆,实现3D医学影像的统一分析。
- 实验表明,3DMedAgent在多个任务上优于现有模型,为通用3D临床助手提供了可行方案。
📝 摘要(中文)
3D CT分析涵盖从低级感知到高级临床理解的连续过程。现有的3D分析方法采用孤立的特定任务建模或任务无关的端到端范式,产生单步输出,阻碍了感知证据的系统积累以进行下游推理。同时,最近的多模态大型语言模型(MLLM)表现出改进的视觉感知,可以有效地整合视觉和文本信息,但其主要面向2D的设计从根本上限制了它们感知和分析体积医学数据的能力。为了弥合这一差距,我们提出了3DMedAgent,一个统一的代理,使2D MLLM能够执行通用的3D CT分析,而无需3D特定的微调。3DMedAgent通过灵活的MLLM代理协调异构的视觉和文本工具,逐步将复杂的3D分析分解为易于处理的子任务,这些子任务从全局到区域视图,从3D体积到信息丰富的2D切片,以及从视觉证据到结构化文本表示。该设计的核心是,3DMedAgent维护一个长期结构化记忆,聚合中间工具的输出,并支持查询自适应的、证据驱动的多步推理。我们进一步引入了DeepChestVQA基准,用于评估3D胸部成像中统一的感知到理解的能力。超过40个任务的实验表明,3DMedAgent始终优于通用、医学和3D特定的MLLM,突出了通往通用3D临床助手的一条可扩展的路径。
🔬 方法详解
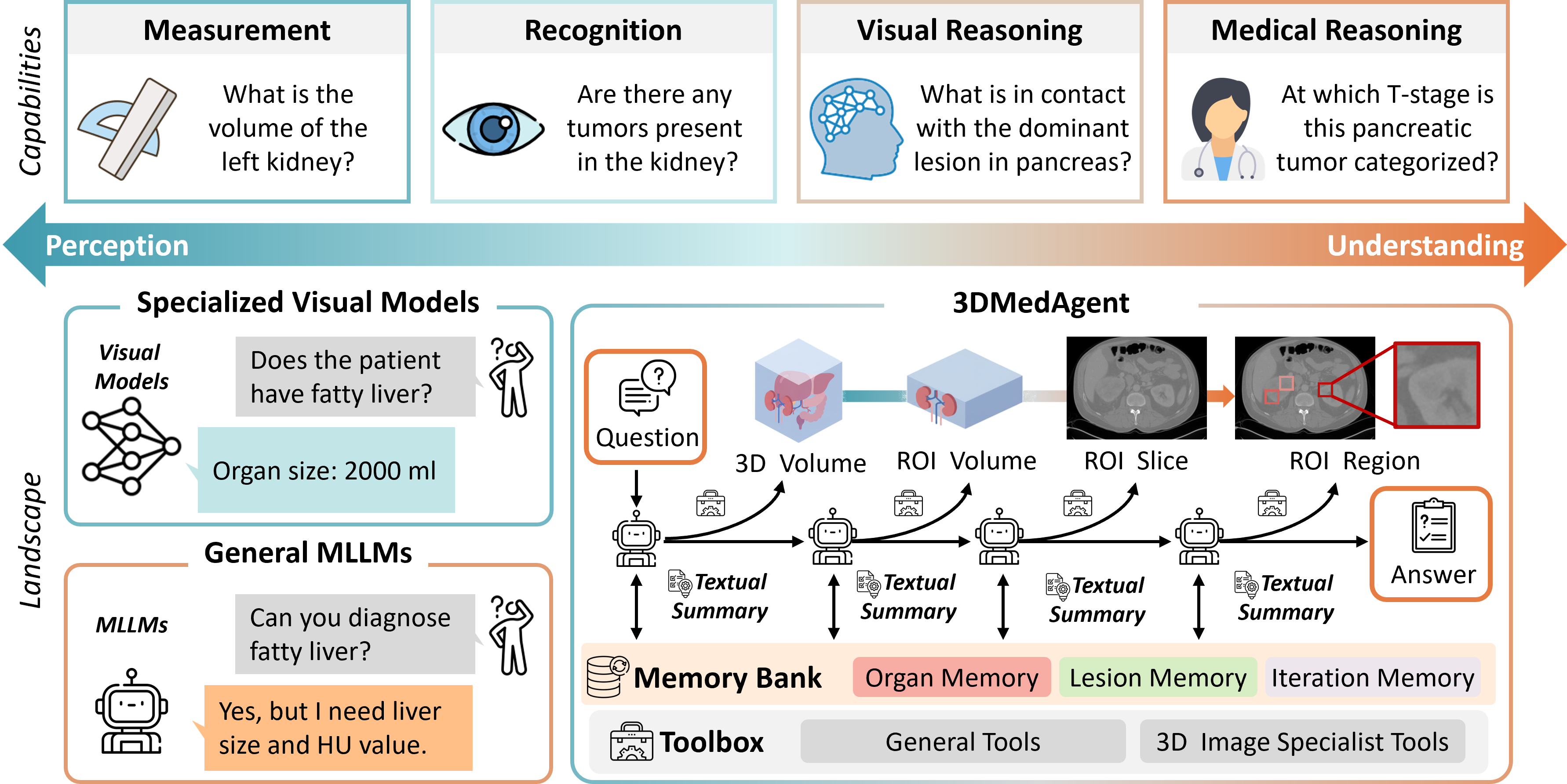
问题定义:现有3D医学影像分析方法,如CT图像分析,通常采用孤立的特定任务建模或端到端范式,导致无法有效积累感知证据,阻碍了高级临床理解。此外,虽然多模态大型语言模型(MLLM)在视觉感知和文本整合方面表现出色,但其2D设计限制了它们在3D医学数据分析中的应用。因此,如何利用现有的2D MLLM能力,实现对3D医学影像的有效分析和理解,是一个亟待解决的问题。
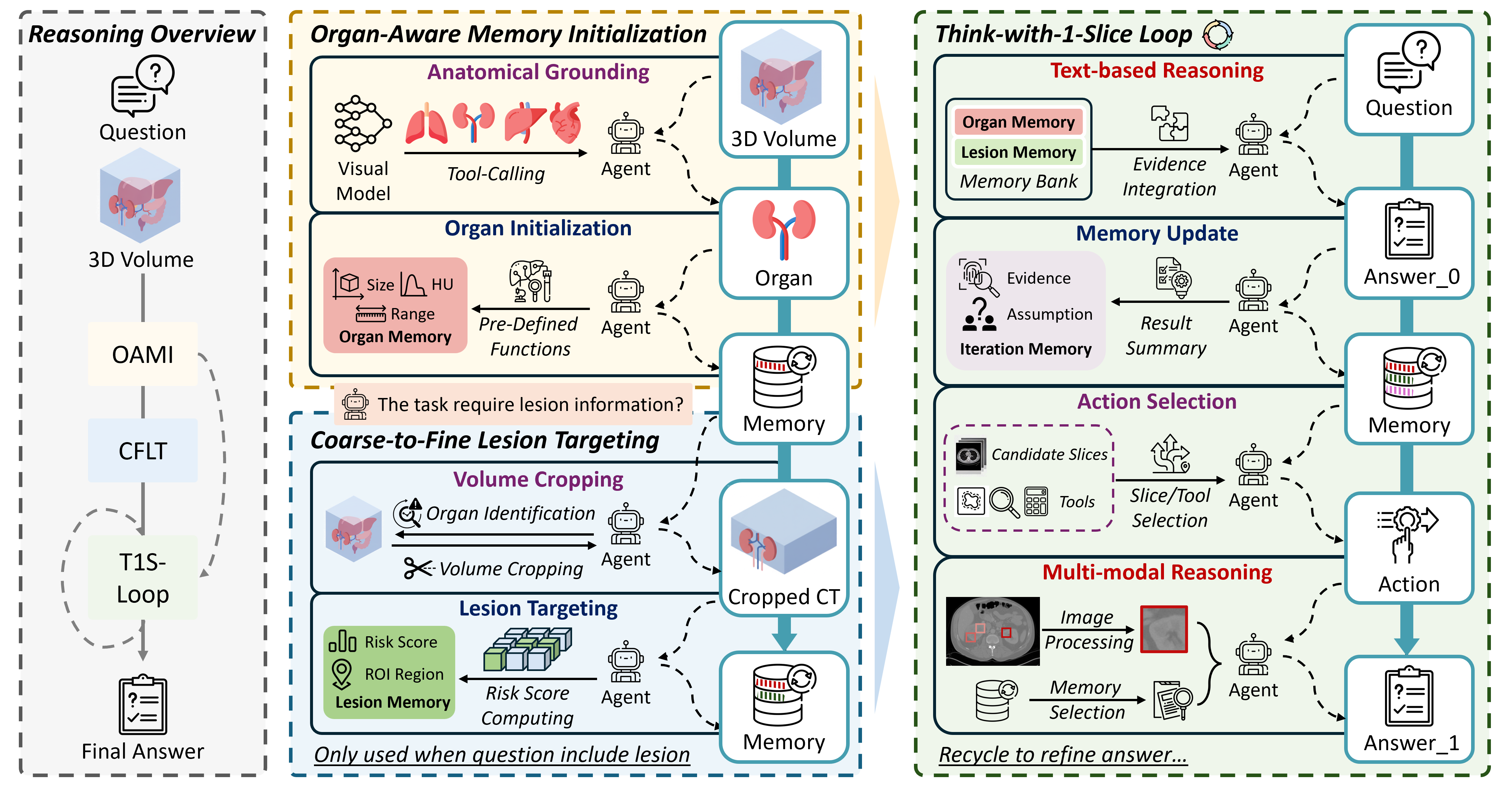
核心思路:3DMedAgent的核心思路是将复杂的3D医学影像分析任务分解为一系列可管理的子任务,并利用2D MLLM作为代理来协调异构的视觉和文本工具。通过这种方式,3DMedAgent能够逐步从全局到区域视图,从3D体积到信息丰富的2D切片,以及从视觉证据到结构化文本表示,从而实现对3D医学影像的全面理解。这种分解和协调的策略使得2D MLLM能够有效地处理3D数据,而无需进行3D特定的微调。
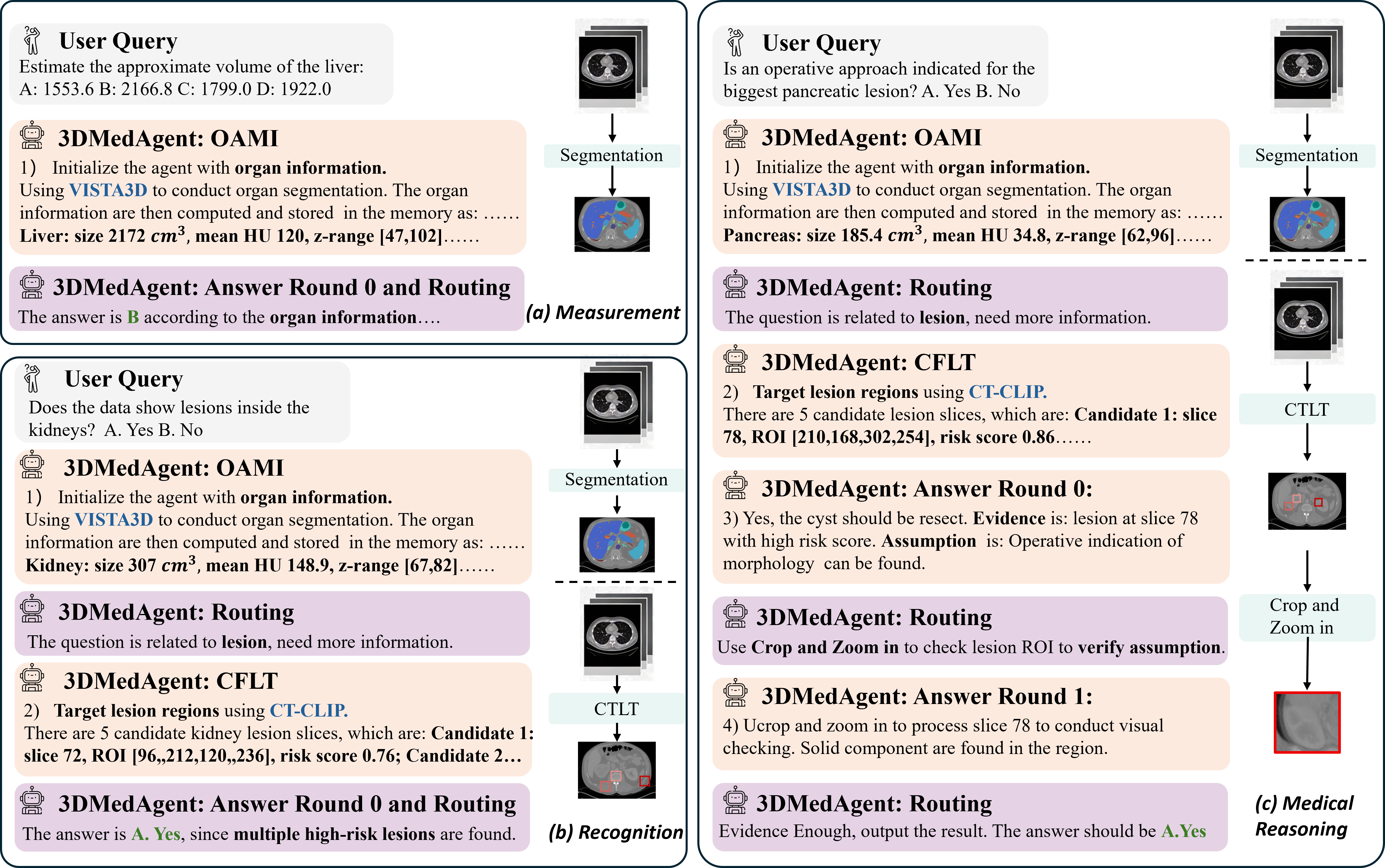
技术框架:3DMedAgent的整体架构包含以下几个主要模块:1) 任务分解模块:将复杂的3D分析任务分解为一系列子任务,例如病灶检测、区域分割、特征提取等。2) 工具选择模块:根据子任务的需求,选择合适的视觉和文本工具,例如图像分割模型、目标检测模型、文本摘要模型等。3) MLLM代理:利用2D MLLM作为代理,协调各个工具的执行,并将中间结果整合到长期结构化记忆中。4) 长期结构化记忆:维护一个长期结构化记忆,用于存储中间工具的输出,并支持查询自适应的、证据驱动的多步推理。
关键创新:3DMedAgent的关键创新在于其统一的感知到理解的框架,该框架能够利用2D MLLM实现对3D医学影像的有效分析,而无需进行3D特定的微调。与现有方法相比,3DMedAgent能够更好地积累感知证据,并支持多步推理,从而实现更高级的临床理解。此外,3DMedAgent的模块化设计使得其具有很强的可扩展性,可以方便地集成新的视觉和文本工具。
关键设计:3DMedAgent的关键设计包括:1) 查询自适应的工具选择策略:根据当前子任务的需求,动态选择合适的视觉和文本工具。2) 证据驱动的多步推理机制:利用长期结构化记忆中的中间结果,进行多步推理,从而实现更高级的临床理解。3) 灵活的MLLM代理:利用2D MLLM作为代理,协调各个工具的执行,并将中间结果整合到长期结构化记忆中。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
3DMedAgent在DeepChestVQA基准测试中取得了显著的成果,在超过40个任务上始终优于通用、医学和3D特定的MLLM。具体性能数据和提升幅度在论文中未详细给出,属于未知信息。但总体而言,实验结果表明3DMedAgent在3D医学影像分析方面具有显著的优势,为通用3D临床助手的发展提供了一条可行的路径。
🎯 应用场景
3DMedAgent具有广泛的应用前景,可用于辅助医生进行疾病诊断、治疗方案制定和预后评估。例如,它可以帮助医生快速准确地检测和分割肿瘤,评估肿瘤的大小和位置,并预测患者的生存率。此外,3DMedAgent还可以用于医学教育和研究,例如,它可以帮助学生更好地理解人体解剖结构和病理生理过程,并为研究人员提供一个强大的3D医学影像分析平台。
📄 摘要(原文)
3D CT analysis spans a continuum from low-level perception to high-level clinical understanding. Existing 3D-oriented analysis methods adopt either isolated task-specific modeling or task-agnostic end-to-end paradigms to produce one-hop outputs, impeding the systematic accumulation of perceptual evidence for downstream reasoning. In parallel, recent multimodal large language models (MLLMs) exhibit improved visual perception and can integrate visual and textual information effectively, yet their predominantly 2D-oriented designs fundamentally limit their ability to perceive and analyze volumetric medical data. To bridge this gap, we propose 3DMedAgent, a unified agent that enables 2D MLLMs to perform general 3D CT analysis without 3D-specific fine-tuning. 3DMedAgent coordinates heterogeneous visual and textual tools through a flexible MLLM agent, progressively decomposing complex 3D analysis into tractable subtasks that transition from global to regional views, from 3D volumes to informative 2D slices, and from visual evidence to structured textual representations. Central to this design, 3DMedAgent maintains a long-term structured memory that aggregates intermediate tool outputs and supports query-adaptive, evidence-driven multi-step reasoning. We further introduce the DeepChestVQA benchmark for evaluating unified perception-to-understanding capabilities in 3D thoracic imaging. Experiments across over 40 tasks demonstrate that 3DMedAgent consistently outperforms general, medical, and 3D-specific MLLMs, highlighting a scalable path toward general-purpose 3D clinical assistants.Code and data are available at \href{https://github.com/jinlab-imvr/3DMedAgent}{https://github.com/jinlab-imvr/3DMedAgent}.