Temporal Consistency-Aware Text-to-Motion Generation
作者: Hongsong Wang, Wenjing Yan, Qiuxia Lai, Xin Geng
分类: cs.CV
发布日期: 2026-02-20
备注: Code is on https://github.com/Giat995/TCA-T2M/
💡 一句话要点
提出TCA-T2M框架,解决文本到动作生成中时序一致性问题。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 文本到动作生成 时序一致性 VQ-VAE Transformer 运动学约束 人体动作生成 跨序列对齐
📋 核心要点
- 现有两阶段文本到动作生成框架忽略了跨序列的时序一致性,导致语义错位和不合理的动作。
- TCA-T2M框架通过时序一致性感知空间VQ-VAE进行跨序列时序对齐,并使用掩码动作Transformer生成动作。
- 实验表明,TCA-T2M在HumanML3D和KIT-ML数据集上取得了SOTA性能,验证了时序一致性的重要性。
📝 摘要(中文)
本文提出了一种时序一致性感知的文本到动作生成框架TCA-T2M,旨在解决现有方法忽略跨序列时序一致性的问题,即同一动作的不同实例之间存在的共享时序结构。该框架包含一个用于跨序列时序对齐的时序一致性感知空间VQ-VAE (TCaS-VQ-VAE) 和一个用于文本条件动作生成的掩码动作Transformer。此外,还引入了一个运动学约束块来缓解离散化伪影,确保物理合理性。在HumanML3D和KIT-ML基准测试上的实验表明,TCA-T2M达到了最先进的性能,突出了时序一致性在鲁棒和连贯的文本到动作生成中的重要性。
🔬 方法详解
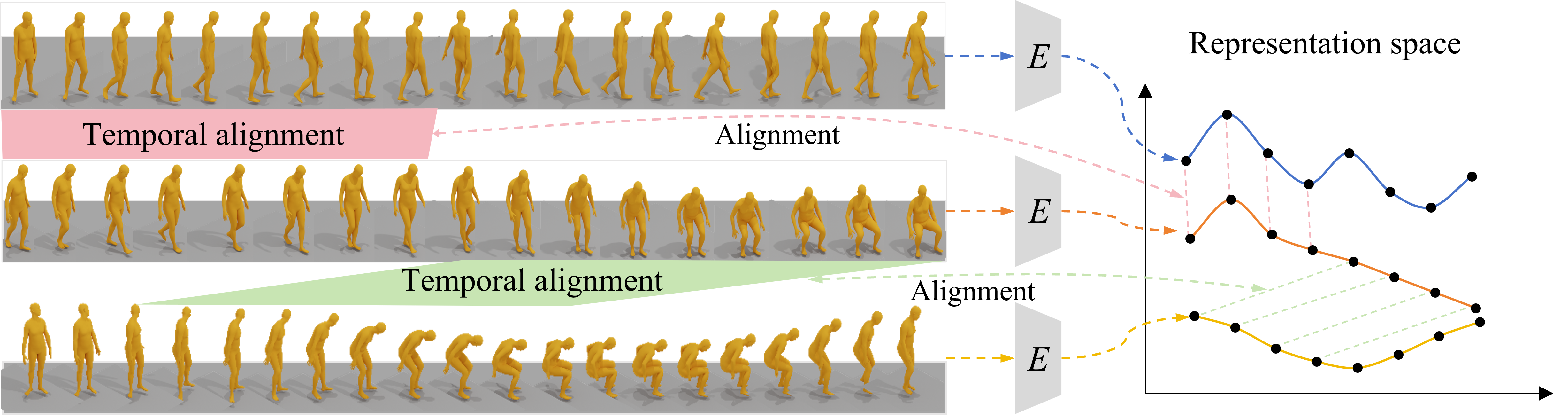
问题定义:文本到动作生成旨在根据自然语言描述合成逼真的人体动作序列。现有方法,特别是那些利用离散运动表示的两阶段框架,常常忽略了跨序列的时序一致性。这意味着它们没有充分利用同一动作的不同实例之间共享的时序结构,导致生成的动作在语义上与文本描述不一致,或者在物理上不合理。
核心思路:本文的核心思路是显式地建模和利用跨序列的时序一致性。通过学习一个能够对齐不同动作序列时序结构的潜在空间,可以确保生成的动作在时间上更加连贯和自然。此外,通过引入运动学约束,可以进一步提高生成动作的物理合理性。
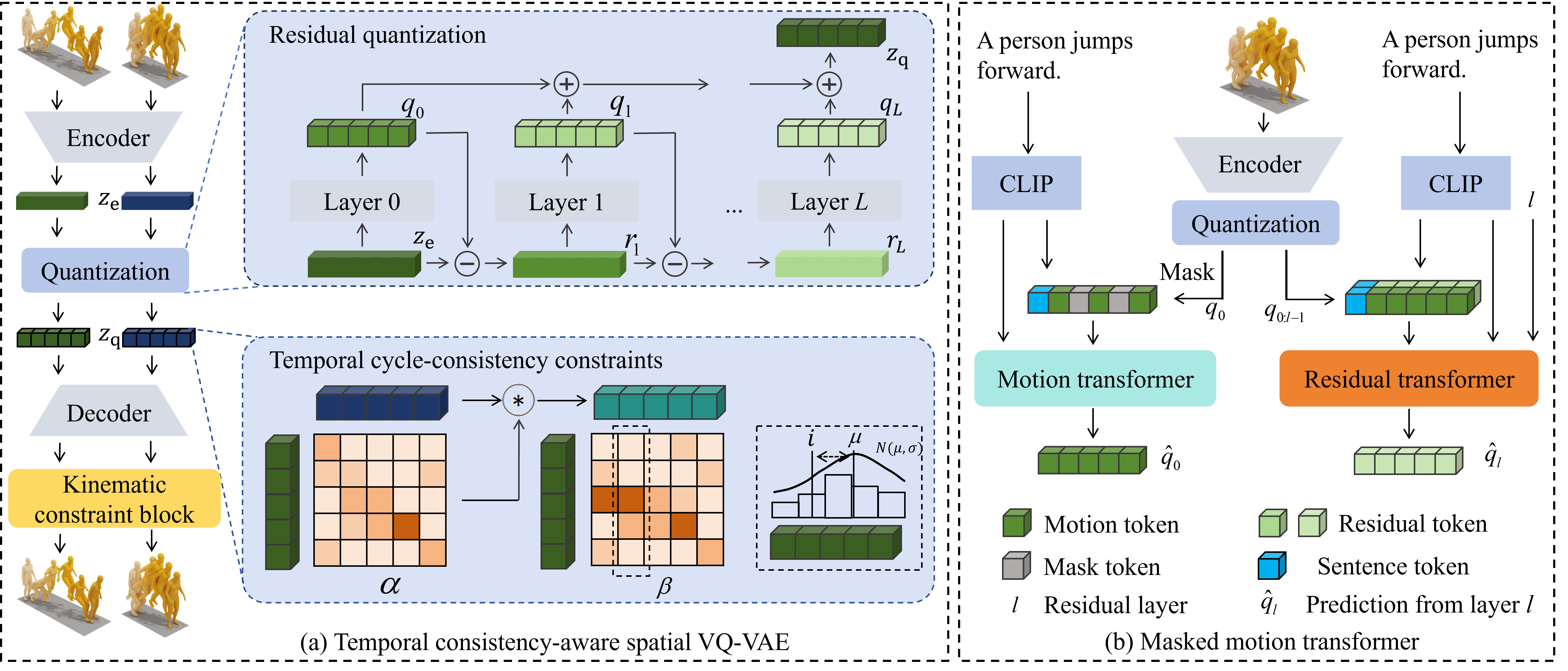
技术框架:TCA-T2M框架主要包含三个模块:1) 时序一致性感知空间VQ-VAE (TCaS-VQ-VAE):用于学习跨序列的时序对齐的离散运动表示。2) 掩码动作Transformer:用于在文本条件的约束下生成动作序列。3) 运动学约束块:用于缓解离散化伪影,确保生成的动作在物理上是合理的。整个流程是,首先使用TCaS-VQ-VAE将动作序列编码到离散潜在空间,然后使用掩码动作Transformer根据文本描述生成离散的动作序列,最后通过运动学约束块对生成的动作序列进行优化。
关键创新:该论文的关键创新在于提出了时序一致性感知的空间VQ-VAE (TCaS-VQ-VAE),它能够学习跨序列的时序对齐的离散运动表示。与传统的VQ-VAE相比,TCaS-VQ-VAE在训练过程中显式地考虑了不同动作序列之间的时序关系,从而能够更好地捕捉动作的时序结构。此外,运动学约束块也是一个重要的创新,它可以有效地缓解离散化伪影,提高生成动作的物理合理性。
关键设计:TCaS-VQ-VAE的设计关键在于如何有效地建模跨序列的时序关系。论文采用了一种基于动态时间规整 (DTW) 的方法来对齐不同动作序列的时序结构。具体来说,首先使用DTW计算不同动作序列之间的相似度矩阵,然后使用该相似度矩阵来指导VQ-VAE的训练过程。掩码动作Transformer的设计与标准的Transformer类似,但针对动作生成任务进行了优化。运动学约束块的设计基于人体运动学的基本原理,通过对生成的动作序列施加运动学约束来提高其物理合理性。损失函数包括VQ-VAE的重构损失、量化损失,以及运动学约束损失。
🖼️ 关键图片

📊 实验亮点
TCA-T2M在HumanML3D和KIT-ML数据集上取得了显著的性能提升。在HumanML3D数据集上,TCA-T2M在FID指标上优于现有最佳方法,表明生成的动作在质量和多样性上都有所提高。在KIT-ML数据集上,TCA-T2M在R精度指标上取得了显著的提升,表明生成的动作与文本描述的匹配度更高。这些实验结果充分证明了时序一致性在文本到动作生成中的重要性。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏、动画制作等领域,例如,可以根据用户的文本描述自动生成虚拟角色的动作,从而提高用户体验。此外,该技术还可以用于康复训练,例如,可以根据医生的文本指令生成康复动作,帮助患者进行康复训练。未来,该技术有望在人机交互、机器人控制等领域发挥更大的作用。
📄 摘要(原文)
Text-to-Motion (T2M) generation aims to synthesize realistic human motion sequences from natural language descriptions. While two-stage frameworks leveraging discrete motion representations have advanced T2M research, they often neglect cross-sequence temporal consistency, i.e., the shared temporal structures present across different instances of the same action. This leads to semantic misalignments and physically implausible motions. To address this limitation, we propose TCA-T2M, a framework for temporal consistency-aware T2M generation. Our approach introduces a temporal consistency-aware spatial VQ-VAE (TCaS-VQ-VAE) for cross-sequence temporal alignment, coupled with a masked motion transformer for text-conditioned motion generation. Additionally, a kinematic constraint block mitigates discretization artifacts to ensure physical plausibility. Experiments on HumanML3D and KIT-ML benchmarks demonstrate that TCA-T2M achieves state-of-the-art performance, highlighting the importance of temporal consistency in robust and coherent T2M generation.