Spatio-temporal Decoupled Knowledge Compensator for Few-Shot Action Recognition
作者: Hongyu Qu, Xiangbo Shu, Rui Yan, Hailiang Gao, Wenguan Wang, Jinhui Tang
分类: cs.CV
发布日期: 2026-02-20
备注: Accepted to TPAMI 2026
💡 一句话要点
提出DiST框架,利用解耦时空知识补偿器提升少样本动作识别性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 少样本学习 动作识别 时空建模 知识补偿 原型学习
📋 核心要点
- 现有少样本动作识别方法依赖粗糙的动作名称作为上下文,缺乏足够的空间和时间背景知识。
- DiST框架通过解耦动作名称为时空属性描述,并利用空间/时间知识补偿器学习多粒度原型。
- 实验结果表明,DiST在五个标准FSAR数据集上取得了state-of-the-art的性能。
📝 摘要(中文)
少样本动作识别(FSAR)是一项具有挑战性的任务,它需要在少量带标签的视频下识别新的动作类别。目前的工作通常使用语义粗糙的类别名称作为辅助上下文来指导判别性视觉特征的学习。然而,动作名称提供的这种上下文过于有限,无法为捕捉动作中的新空间和时间概念提供足够的背景知识。本文提出DiST,一种创新的分解-整合框架,用于FSAR,它利用大型语言模型提供的解耦空间和时间知识来学习富有表现力的多粒度原型。在分解阶段,我们将原始动作名称分解为不同的时空属性描述(与动作相关的知识)。这种常识知识从空间和时间角度补充了语义上下文。在整合阶段,我们提出了空间/时间知识补偿器(SKC/TKC),分别用于发现判别性的对象级和帧级原型。在SKC中,对象级原型在空间知识的指导下自适应地聚合重要的patch tokens。此外,在TKC中,帧级原型利用时间属性来辅助帧间时间关系建模。因此,这些学习到的原型在捕捉细粒度的空间细节和不同的时间模式方面提供了透明性。实验结果表明,DiST在五个标准FSAR数据集上取得了最先进的结果。
🔬 方法详解
问题定义:少样本动作识别(FSAR)旨在仅利用少量带标签的视频样本识别新的动作类别。现有方法主要依赖于动作名称提供的语义信息,但这种信息过于粗糙,无法充分捕捉动作中复杂的时空关系,导致模型泛化能力不足。
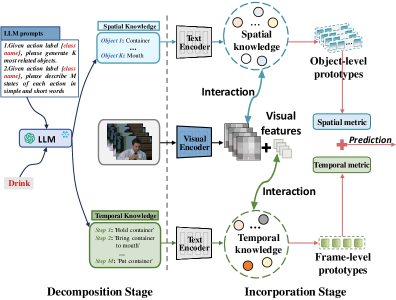
核心思路:DiST框架的核心思路是将动作名称解耦为更细粒度的空间和时间属性描述,从而为模型提供更丰富的背景知识。通过空间知识补偿器(SKC)和时间知识补偿器(TKC),模型能够学习到更具判别性的对象级和帧级原型,从而提升少样本情况下的识别性能。
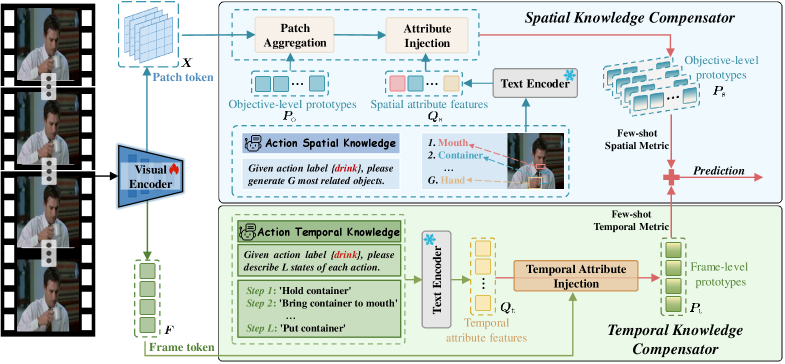
技术框架:DiST框架主要包含两个阶段:分解阶段和整合阶段。在分解阶段,利用大型语言模型将动作名称分解为时空属性描述。在整合阶段,利用SKC和TKC分别学习对象级和帧级原型。SKC通过空间知识引导patch tokens的聚合,TKC利用时间属性辅助帧间关系建模。最终,利用学习到的原型进行动作识别。
关键创新:DiST的关键创新在于引入了时空解耦知识补偿器。与以往方法直接使用动作名称作为上下文不同,DiST将动作名称分解为更细粒度的时空属性,从而为模型提供更丰富的背景知识。SKC和TKC的设计使得模型能够自适应地学习对象级和帧级原型,从而更好地捕捉动作中的时空关系。
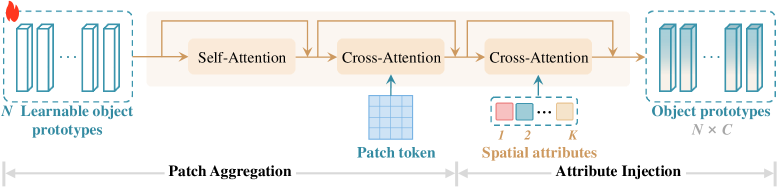
关键设计:SKC利用Transformer结构,通过空间知识引导注意力机制,自适应地聚合重要的patch tokens。TKC利用时间属性作为先验知识,辅助帧间关系建模,例如使用LSTM或Transformer等序列模型。损失函数包括原型对比损失和分类损失,用于优化原型表示和提升分类性能。
🖼️ 关键图片
📊 实验亮点
DiST在五个标准FSAR数据集上取得了state-of-the-art的结果。具体而言,在某些数据集上,DiST的性能相比现有最佳方法提升了显著的百分点,证明了该方法在少样本动作识别任务上的有效性。
🎯 应用场景
该研究成果可应用于视频监控、人机交互、机器人导航等领域。例如,在视频监控中,可以利用该方法识别异常行为;在人机交互中,可以识别用户的手势和动作;在机器人导航中,可以帮助机器人理解人类的指令。
📄 摘要(原文)
Few-Shot Action Recognition (FSAR) is a challenging task that requires recognizing novel action categories with a few labeled videos. Recent works typically apply semantically coarse category names as auxiliary contexts to guide the learning of discriminative visual features. However, such context provided by the action names is too limited to provide sufficient background knowledge for capturing novel spatial and temporal concepts in actions. In this paper, we propose DiST, an innovative Decomposition-incorporation framework for FSAR that makes use of decoupled Spatial and Temporal knowledge provided by large language models to learn expressive multi-granularity prototypes. In the decomposition stage, we decouple vanilla action names into diverse spatio-temporal attribute descriptions (action-related knowledge). Such commonsense knowledge complements semantic contexts from spatial and temporal perspectives. In the incorporation stage, we propose Spatial/Temporal Knowledge Compensators (SKC/TKC) to discover discriminative object-level and frame-level prototypes, respectively. In SKC, object-level prototypes adaptively aggregate important patch tokens under the guidance of spatial knowledge. Moreover, in TKC, frame-level prototypes utilize temporal attributes to assist in inter-frame temporal relation modeling. These learned prototypes thus provide transparency in capturing fine-grained spatial details and diverse temporal patterns. Experimental results show DiST achieves state-of-the-art results on five standard FSAR datasets.