Dual-Channel Attention Guidance for Training-Free Image Editing Control in Diffusion Transformers
作者: Guandong Li, Mengxia Ye
分类: cs.CV, cs.AI
发布日期: 2026-02-20
💡 一句话要点
提出双通道注意力引导(DCAG),用于Diffusion Transformer的免训练图像编辑控制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: Diffusion Transformer 图像编辑 注意力机制 免训练 双通道引导 Key-Value注意力 图像生成
📋 核心要点
- 现有基于Diffusion Transformer的图像编辑方法缺乏对编辑强度的免训练控制,且仅关注Key空间的注意力操控。
- 论文提出双通道注意力引导(DCAG),同时操纵Key和Value通道,实现更精细的编辑控制和保真度权衡。
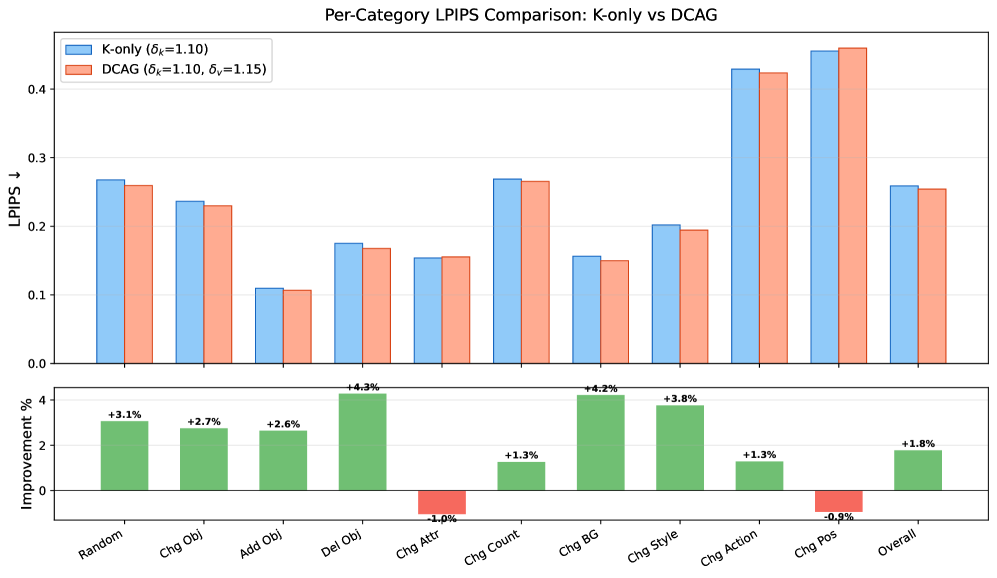
- 实验表明,DCAG在PIE-Bench基准测试中,显著优于仅使用Key的引导方法,尤其在局部编辑任务中。
📝 摘要(中文)
本文针对基于Diffusion Transformer (DiT) 架构的扩散模型图像编辑,提出了一种免训练的编辑强度控制方法。现有注意力操控方法仅关注Key空间以调节注意力路由,完全忽略了控制特征聚合的Value空间。本文首先揭示了DiT多模态注意力层中的Key和Value投影都表现出明显的偏置-delta结构,即token嵌入紧密地聚集在特定层的偏置向量周围。基于此,我们提出了双通道注意力引导(DCAG),一个免训练框架,可以同时操纵Key通道(控制关注位置)和Value通道(控制聚合内容)。我们提供理论分析表明,Key通道通过非线性softmax函数操作,作为粗略的控制旋钮,而Value通道通过线性加权求和操作,作为精细的补充。双维参数空间(δ_k, δ_v)能够实现比任何单通道方法更精确的编辑-保真度权衡。在PIE-Bench基准测试(700张图像,10个编辑类别)上的大量实验表明,DCAG在所有保真度指标上始终优于仅使用Key的引导方法,在诸如对象删除(LPIPS降低4.9%)和对象添加(LPIPS降低3.2%)等局部编辑任务中观察到最显著的改进。
🔬 方法详解
问题定义:现有基于Diffusion Transformer的图像编辑方法,在控制编辑强度时,主要依赖于训练特定的模型或额外的参数。对于免训练的方法,现有技术主要集中在操纵注意力机制的Key空间,以改变注意力路由,但忽略了Value空间在特征聚合中的作用,导致编辑控制不够精细,编辑质量受限。
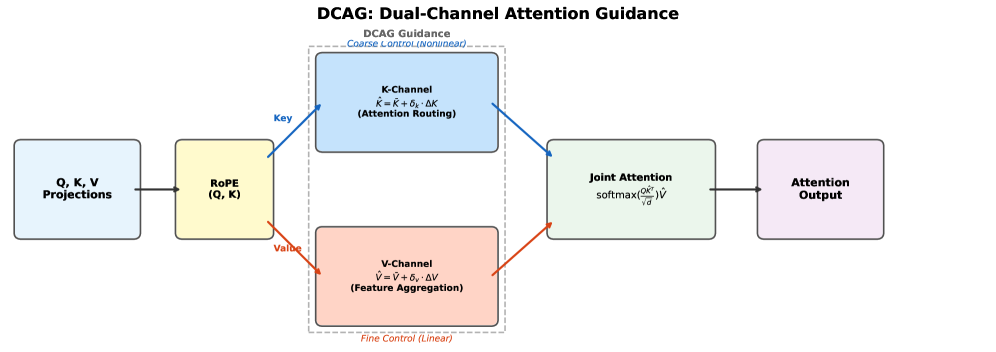
核心思路:论文的核心思路是同时利用Diffusion Transformer中多头注意力机制的Key和Value通道进行引导。Key通道负责控制“在哪里”关注,Value通道负责控制“聚合什么”特征。通过同时调整这两个通道,可以实现更精细的编辑控制,并在编辑效果和图像保真度之间取得更好的平衡。论文观察到Key和Value投影都呈现出偏置-delta结构,这为操控这两个通道提供了理论基础。
技术框架:DCAG框架主要包含以下几个步骤:1) 分析Diffusion Transformer中多头注意力层的Key和Value投影,发现其偏置-delta结构。2) 设计Key通道的引导策略,通过调整Key的delta值(δ_k)来控制注意力权重,从而影响模型关注的区域。3) 设计Value通道的引导策略,通过调整Value的delta值(δ_v)来控制特征聚合的方式,从而影响生成图像的内容。4) 将Key和Value通道的引导策略结合起来,形成双通道注意力引导(DCAG),通过调整δ_k和δ_v两个参数,实现对编辑强度和保真度的精细控制。
关键创新:该论文的关键创新在于:1) 首次提出同时利用Diffusion Transformer中多头注意力机制的Key和Value通道进行图像编辑引导。2) 揭示了DiT中Key和Value投影的偏置-delta结构,为操控这两个通道提供了理论依据。3) 设计了一种免训练的双通道注意力引导框架(DCAG),可以实现更精细的编辑控制和更好的编辑质量。
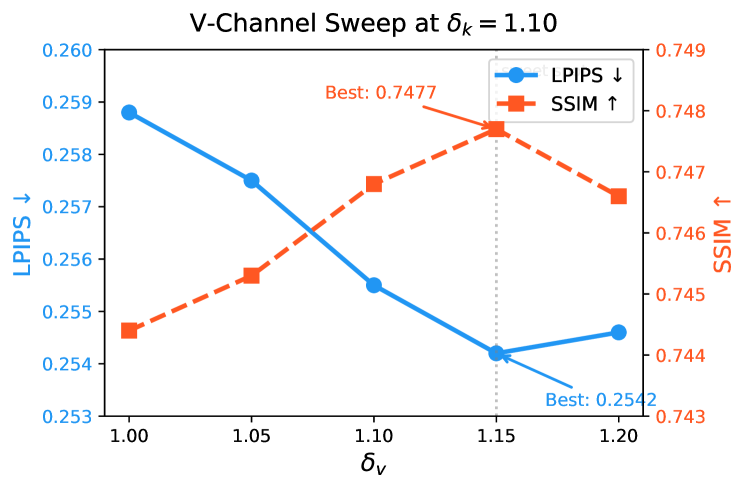
关键设计:DCAG的关键设计包括:1) Key通道的引导策略,通过调整Key的delta值(δ_k)来控制注意力权重,δ_k的调整范围需要根据具体任务进行调整。2) Value通道的引导策略,通过调整Value的delta值(δ_v)来控制特征聚合的方式,δ_v的调整范围也需要根据具体任务进行调整。3) δ_k和δ_v的组合方式,需要根据具体任务进行调整,以实现最佳的编辑效果和保真度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DCAG在PIE-Bench基准测试中,在所有保真度指标上始终优于仅使用Key的引导方法。在对象删除任务中,DCAG的LPIPS降低了4.9%,在对象添加任务中,LPIPS降低了3.2%。这些结果表明,DCAG能够实现更精细的编辑控制和更好的编辑质量。
🎯 应用场景
该研究成果可应用于图像编辑、图像修复、图像生成等领域。例如,用户可以通过调整Key和Value通道的引导强度,实现对图像中特定对象的精确编辑,如删除、添加或修改对象。该方法无需重新训练模型,具有很高的实用价值和应用前景,可以广泛应用于艺术创作、内容生成、图像处理等领域。
📄 摘要(原文)
Training-free control over editing intensity is a critical requirement for diffusion-based image editing models built on the Diffusion Transformer (DiT) architecture. Existing attention manipulation methods focus exclusively on the Key space to modulate attention routing, leaving the Value space -- which governs feature aggregation -- entirely unexploited. In this paper, we first reveal that both Key and Value projections in DiT's multi-modal attention layers exhibit a pronounced bias-delta structure, where token embeddings cluster tightly around a layer-specific bias vector. Building on this observation, we propose Dual-Channel Attention Guidance (DCAG), a training-free framework that simultaneously manipulates both the Key channel (controlling where to attend) and the Value channel (controlling what to aggregate). We provide a theoretical analysis showing that the Key channel operates through the nonlinear softmax function, acting as a coarse control knob, while the Value channel operates through linear weighted summation, serving as a fine-grained complement. Together, the two-dimensional parameter space $(δ_k, δ_v)$ enables more precise editing-fidelity trade-offs than any single-channel method. Extensive experiments on the PIE-Bench benchmark (700 images, 10 editing categories) demonstrate that DCAG consistently outperforms Key-only guidance across all fidelity metrics, with the most significant improvements observed in localized editing tasks such as object deletion (4.9% LPIPS reduction) and object addition (3.2% LPIPS reduction).