UAOR: Uncertainty-aware Observation Reinjection for Vision-Language-Action Models
作者: Jiabing Yang, Yixiang Chen, Yuan Xu, Peiyan Li, Xiangnan Wu, Zichen Wen, Bowen Fang, Tao Yu, Zhengbo Zhang, Yingda Li, Kai Wang, Jing Liu, Nianfeng Liu, Yan Huang, Liang Wang
分类: cs.CV, cs.RO
发布日期: 2026-02-20
💡 一句话要点
提出不确定性感知观测重注入(UAOR)模块,提升VLA模型在机器人操作任务中的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 不确定性感知 观测重注入 前馈网络 注意力机制 免训练 即插即用
📋 核心要点
- 现有VLA模型依赖额外观测或辅助模块提升性能,但需大量数据和额外训练,成本高昂。
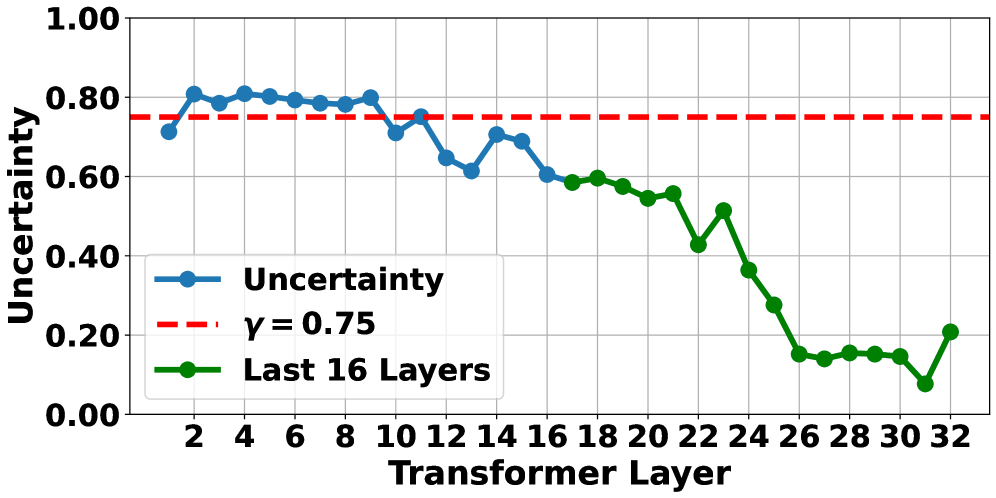
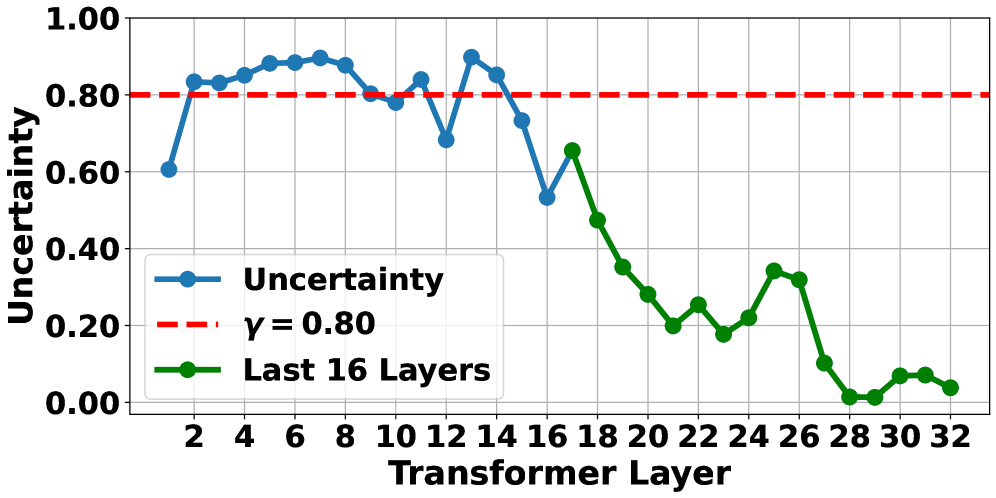
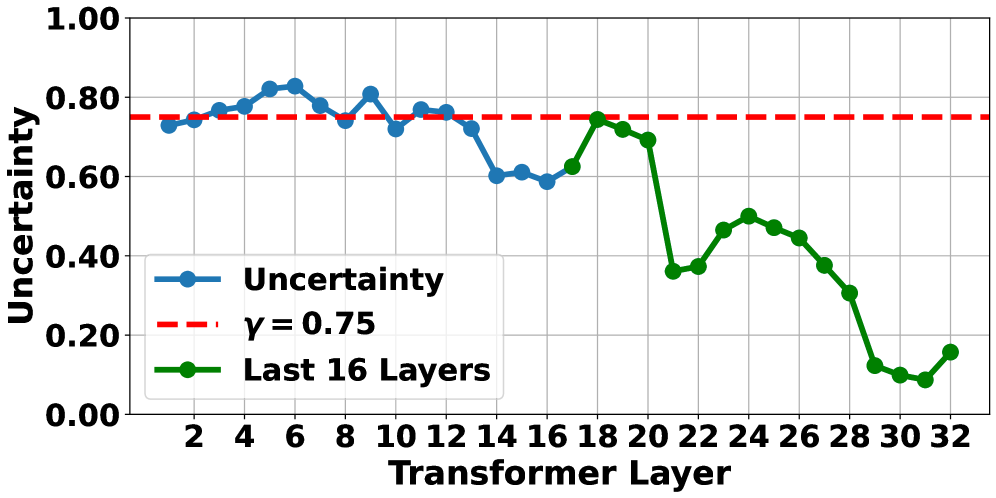
- UAOR通过动作熵衡量不确定性,将关键观测信息注入到FFN中,增强模型对观测的关注。
- 实验表明,UAOR在模拟和真实世界任务中,以最小开销持续改进VLA模型,无需额外数据或模块。
📝 摘要(中文)
视觉-语言-动作(VLA)模型利用预训练的视觉-语言模型(VLM)作为骨干网络,将图像和指令映射到动作,展现了在通用机器人操作方面的巨大潜力。为了提高性能,现有方法通常结合额外的观测线索(例如,深度图、点云)或辅助模块(例如,对象检测器、编码器),以实现更精确和可靠的任务执行,但这通常需要昂贵的数据收集和额外的训练。受到语言模型中的前馈网络(FFN)可以充当“键值存储器”的启发,我们提出了一种有效的、免训练的、即插即用的VLA模型模块:不确定性感知观测重注入(UAOR)。具体来说,当当前语言模型层表现出高不确定性时(通过动作熵测量),它通过注意力检索将关键观测信息重新注入到下一层的前馈网络(FFN)中。这种机制有助于VLA在推理过程中更好地关注观测,从而实现更自信和忠实的动作生成。全面的实验表明,我们的方法在模拟和真实世界的任务中,以最小的开销持续改进各种VLA模型。值得注意的是,UAOR消除了对额外观测线索或模块的需求,使其成为现有VLA管道的通用且实用的插件。项目主页位于https://uaor.jiabingyang.cn。
🔬 方法详解
问题定义:现有VLA模型在机器人操作任务中,为了提升性能,通常需要引入额外的观测信息(如深度图、点云)或者辅助模块(如目标检测器),但这增加了数据收集和模型训练的成本。现有方法的痛点在于需要额外的资源投入,限制了VLA模型的通用性和易用性。
核心思路:论文的核心思路是利用语言模型中的前馈网络(FFN)作为“键值存储器”的特性,在模型预测动作不确定性较高时,将关键的观测信息重新注入到FFN中,从而引导模型更好地关注观测信息,生成更可靠的动作。这样设计的目的是在不增加额外训练成本的前提下,提升VLA模型的性能。
技术框架:UAOR作为一个即插即用的模块,可以嵌入到现有的VLA模型中。其主要流程如下:1. 计算当前语言模型层的动作熵,作为不确定性的度量。2. 当不确定性超过阈值时,通过注意力机制从观测信息中检索关键信息。3. 将检索到的关键观测信息注入到下一层的前馈网络(FFN)中。
关键创新:该论文的关键创新在于提出了不确定性感知的观测重注入机制。与现有方法不同,UAOR不需要额外的观测线索或辅助模块,而是通过利用模型自身的不确定性来动态地调整对观测信息的关注程度。这种方法更加高效和灵活,可以广泛应用于各种VLA模型。
关键设计:UAOR的关键设计包括:1. 使用动作熵作为不确定性的度量,动作熵越高,表示模型对下一步动作的预测越不确定。2. 使用注意力机制从观测信息中检索关键信息,注意力权重可以学习,也可以是固定的。3. 将检索到的关键观测信息以残差连接的方式注入到FFN中,避免破坏原始的信息流。
🖼️ 关键图片
📊 实验亮点
实验结果表明,UAOR在模拟和真实世界的机器人操作任务中,能够显著提升VLA模型的性能。例如,在某个具体任务中,UAOR可以将成功率提高5%-10%,并且在不同的VLA模型上都取得了类似的提升效果。此外,UAOR的计算开销很小,几乎不影响模型的推理速度。
🎯 应用场景
该研究成果可广泛应用于机器人操作领域,例如家庭服务机器人、工业自动化机器人等。通过提升VLA模型的性能,可以使机器人更准确、可靠地执行各种任务,提高工作效率和安全性。此外,该方法无需额外的数据和训练,易于部署和应用,具有很高的实际价值和推广潜力。
📄 摘要(原文)
Vision-Language-Action (VLA) models leverage pretrained Vision-Language Models (VLMs) as backbones to map images and instructions to actions, demonstrating remarkable potential for generalizable robotic manipulation. To enhance performance, existing methods often incorporate extra observation cues (e.g., depth maps, point clouds) or auxiliary modules (e.g., object detectors, encoders) to enable more precise and reliable task execution, yet these typically require costly data collection and additional training. Inspired by the finding that Feed-Forward Network (FFN) in language models can act as "key-value memory", we propose Uncertainty-aware Observation Reinjection (UAOR), an effective, training-free and plug-and-play module for VLA models. Specifically, when the current language model layer exhibits high uncertainty, measured by Action Entropy, it reinjects key observation information into the next layer's Feed-Forward Network (FFN) through attention retrieval. This mechanism helps VLAs better attend to observations during inference, enabling more confident and faithful action generation. Comprehensive experiments show that our method consistently improves diverse VLA models across simulation and real-world tasks with minimal overhead. Notably, UAOR eliminates the need for additional observation cues or modules, making it a versatile and practical plug-in for existing VLA pipelines. The project page is at https://uaor.jiabingyang.cn.