Towards LLM-centric Affective Visual Customization via Efficient and Precise Emotion Manipulating
作者: Jiamin Luo, Xuqian Gu, Jingjing Wang, Jiahong Lu
分类: cs.CV
发布日期: 2026-02-20
💡 一句话要点
提出基于LLM的情感视觉定制框架L-AVC,实现高效精确的情感操控。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感视觉定制 大型语言模型 多模态学习 图像编辑 情感操控
📋 核心要点
- 现有视觉定制方法主要关注客观对齐,忽略了主观情感内容,缺乏通用情感视觉定制基础模型。
- 提出L-AVC任务,并设计高效精确的情感操控方法EPEM,包含EIC模块和PER模块。
- 实验结果表明,EPEM方法在L-AVC任务上优于现有方法,验证了情感信息的重要性和EPEM的有效性。
📝 摘要(中文)
本文提出了一个以LLM为中心的视觉情感定制(L-AVC)任务,旨在通过多模态LLM修改图像的主观情感。作者认为,在该任务中,如何使模型有效地对齐语义中的情感转换(即情感间语义转换)以及如何精确地保留与情感无关的内容(即情感外语义保留)至关重要且具有挑战性。为此,本文提出了一种高效而精确的情感操控方法(EPEM),用于编辑图像中的主观情感。具体而言,EPEM包含一个高效情感间转换(EIC)模块,旨在使LLM有效地对齐编辑前后语义中的情感转换;以及一个精确情感外保留(PER)模块,旨在精确地保留与情感无关的内容。在构建的L-AVC数据集上的综合实验评估表明,所提出的EPEM方法在L-AVC任务上优于几种最先进的基线方法。这证明了情感信息对于L-AVC的重要性以及EPEM在高效而精确地操纵此类信息方面的有效性。
🔬 方法详解
问题定义:现有视觉定制方法主要依赖于控制信号(如语言、布局、边缘)与编辑图像之间的客观对齐,忽略了图像的主观情感内容。缺乏能够进行情感视觉定制的通用基础模型。因此,需要一种方法能够有效地修改图像的情感,同时保留与情感无关的内容。
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大语义理解和生成能力,通过设计专门的模块来高效地转换情感语义,并精确地保留与情感无关的内容。通过这种方式,可以实现对图像情感的有效操控,同时保证图像内容的一致性。
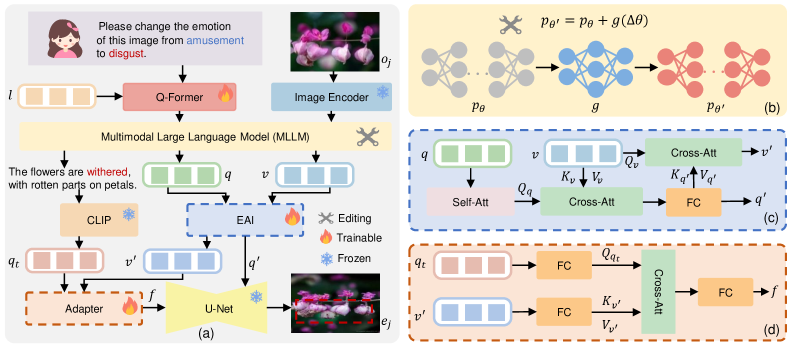
技术框架:整体框架包含两个主要模块:高效情感间转换(EIC)模块和精确情感外保留(PER)模块。EIC模块负责在LLM中对齐编辑前后语义中的情感转换,确保情感的有效改变。PER模块负责精确地保留与情感无关的内容,保证图像内容的一致性。整个流程首先通过EIC模块进行情感转换,然后通过PER模块进行内容保留,最终生成具有目标情感的图像。
关键创新:本文的关键创新在于提出了L-AVC任务,并设计了EPEM方法,该方法能够高效且精确地操控图像的情感。与现有方法相比,EPEM方法更加关注图像的主观情感内容,并能够利用LLM的强大能力来实现情感的有效转换和内容保留。
关键设计:EIC模块和PER模块的具体设计细节未知,论文中可能没有详细描述。但可以推测,EIC模块可能涉及到情感词汇的替换、情感语义的嵌入等技术,而PER模块可能涉及到内容一致性损失、注意力机制等技术。
🖼️ 关键图片

📊 实验亮点
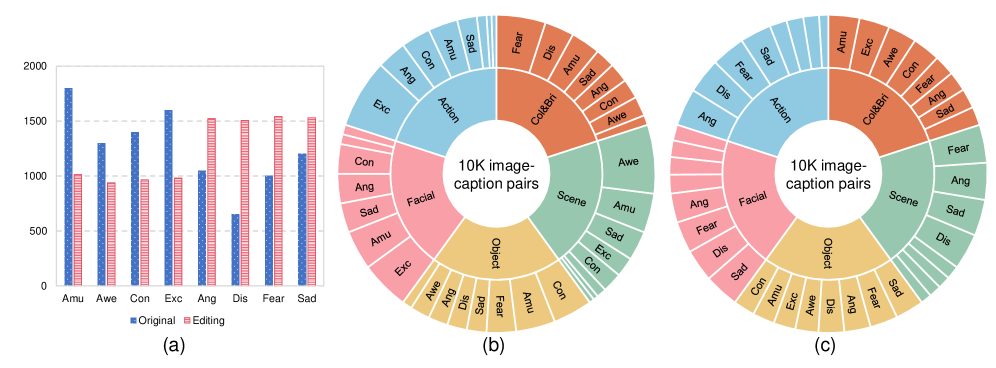
实验结果表明,提出的EPEM方法在L-AVC数据集上优于几种最先进的基线方法。具体性能数据和提升幅度未知,但实验结果证明了情感信息对于L-AVC的重要性以及EPEM在高效而精确地操纵此类信息方面的有效性。
🎯 应用场景
该研究成果可应用于图像编辑、情感设计、虚拟现实、游戏开发等领域。例如,可以根据用户的情感需求自动修改图像的情感色彩,或者在虚拟现实环境中创建具有特定情感氛围的场景。该研究有助于提升人机交互的自然性和情感体验。
📄 摘要(原文)
Previous studies on visual customization primarily rely on the objective alignment between various control signals (e.g., language, layout and canny) and the edited images, which largely ignore the subjective emotional contents, and more importantly lack general-purpose foundation models for affective visual customization. With this in mind, this paper proposes an LLM-centric Affective Visual Customization (L-AVC) task, which focuses on generating images within modifying their subjective emotions via Multimodal LLM. Further, this paper contends that how to make the model efficiently align emotion conversion in semantics (named inter-emotion semantic conversion) and how to precisely retain emotion-agnostic contents (named exter-emotion semantic retaining) are rather important and challenging in this L-AVC task. To this end, this paper proposes an Efficient and Precise Emotion Manipulating approach for editing subjective emotions in images. Specifically, an Efficient Inter-emotion Converting (EIC) module is tailored to make the LLM efficiently align emotion conversion in semantics before and after editing, followed by a Precise Exter-emotion Retaining (PER) module to precisely retain the emotion-agnostic contents. Comprehensive experimental evaluations on our constructed L-AVC dataset demonstrate the great advantage of the proposed EPEM approach to the L-AVC task over several state-of-the-art baselines. This justifies the importance of emotion information for L-AVC and the effectiveness of EPEM in efficiently and precisely manipulating such information.