MUOT_3M: A 3 Million Frame Multimodal Underwater Benchmark and the MUTrack Tracking Method
作者: Ahsan Baidar Bakht, Mohamad Alansari, Muhayy Ud Din, Muzammal Naseer, Sajid Javed, Irfan Hussain, Jiri Matas, Arif Mahmood
分类: cs.CV
发布日期: 2026-02-20
💡 一句话要点
提出MUOT_3M水下多模态数据集与MUTrack跟踪方法,提升水下目标跟踪性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 水下目标跟踪 多模态学习 知识蒸馏 视觉语言融合 深度信息 数据集 Segment Anything Model
📋 核心要点
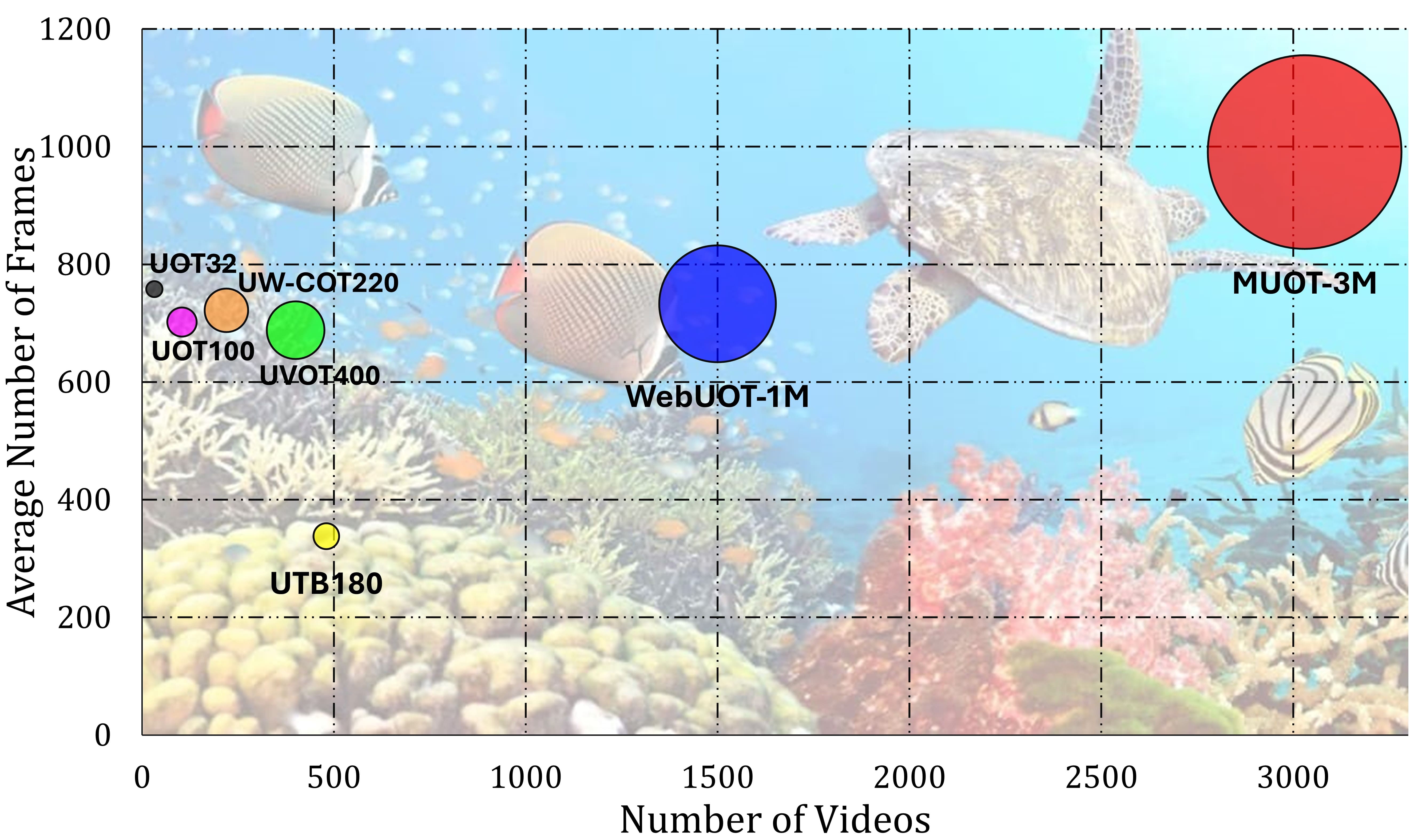
- 现有水下目标跟踪数据集规模小,模态单一,难以应对水下复杂环境带来的挑战。
- 提出MUTrack,利用视觉几何对齐和视觉语言融合,将多模态知识蒸馏到单模态模型中。
- 实验表明,MUTrack在多个水下目标跟踪基准上显著优于现有方法,并保持了较高的运行速度。
📝 摘要(中文)
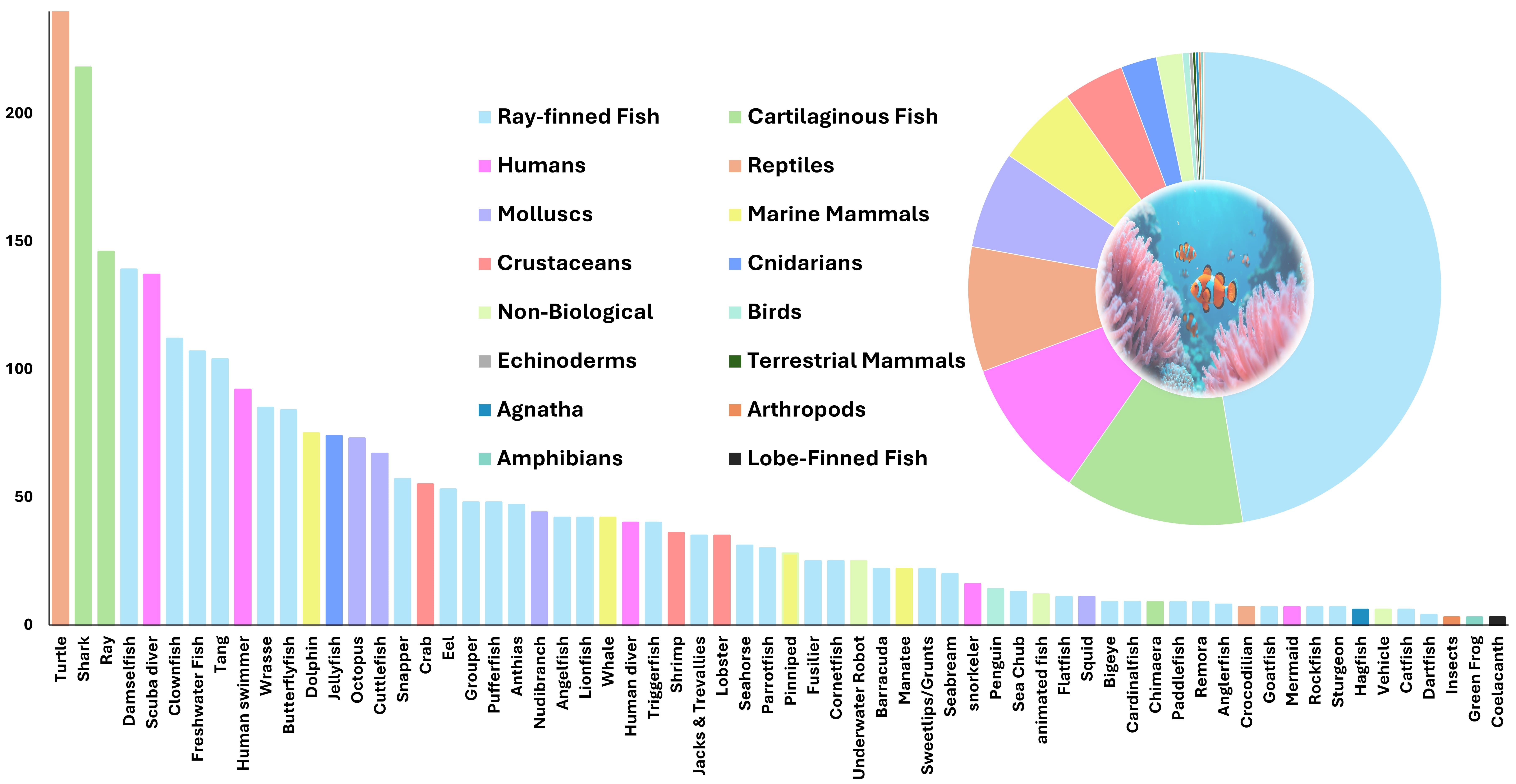
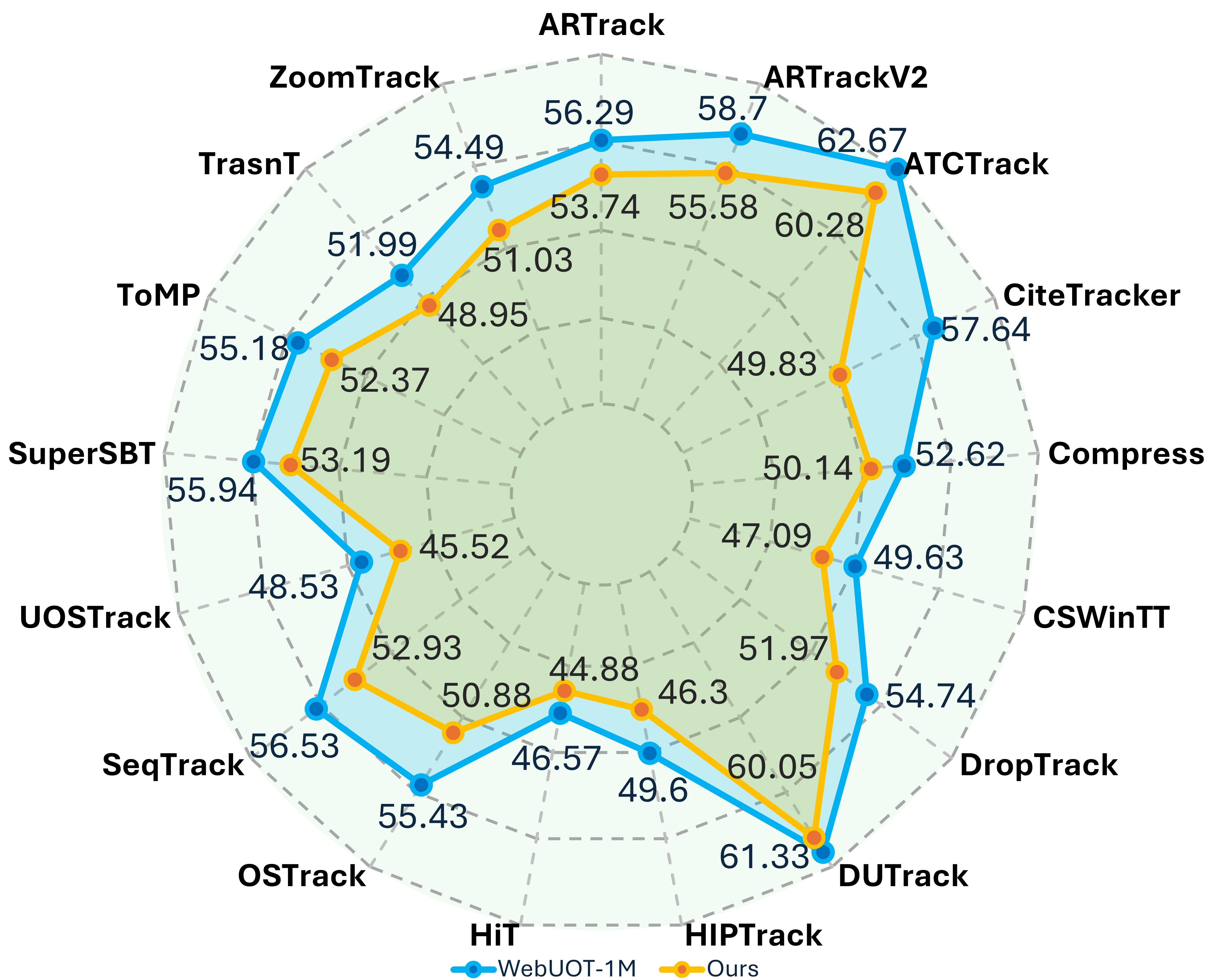
水下目标跟踪(UOT)对于高效的海洋机器人、大规模生态监测和海洋探索至关重要。然而,由于缺乏大型、多模态和多样化的数据集,该领域的进展受到阻碍。现有的基准数据集规模较小,且仅包含RGB信息,限制了在严重颜色失真、浑浊和低能见度条件下的鲁棒性。我们推出了MUOT_3M,这是第一个伪多模态UOT基准,包含来自3030个视频的300万帧(27.8小时),并标注了32个跟踪属性、677个细粒度类别,以及同步的RGB、估计增强RGB、估计深度和语言模态,并由海洋生物学家验证。基于MUOT_3M,我们提出了MUTrack,一种基于SAM的多模态到单模态跟踪器,具有视觉几何对齐、视觉语言融合和四级知识蒸馏,将多模态知识转移到单模态学生模型中。在五个UOT基准上的广泛评估表明,MUTrack实现了比最强的SOTA基线高出8.40%的AUC和7.80%的精度,同时以24 FPS的速度运行。MUOT_3M和MUTrack为可扩展的、多模态训练但实际可部署的水下跟踪奠定了新的基础。
🔬 方法详解
问题定义:水下目标跟踪任务在实际应用中面临水下环境复杂、光照条件差、能见度低等挑战,导致传统RGB图像跟踪方法性能下降。现有数据集规模小、模态单一,难以训练出鲁棒性强的跟踪模型。因此,需要一个更大规模、更多模态的数据集,以及一种能够有效利用多模态信息的水下目标跟踪方法。
核心思路:MUTrack的核心思路是利用多模态信息提升水下目标跟踪的鲁棒性,并通过知识蒸馏将多模态知识迁移到单模态模型中,以便在实际部署时仅使用RGB图像。通过视觉几何对齐和视觉语言融合,充分利用RGB、增强RGB、深度和语言信息,提高跟踪精度。
技术框架:MUTrack的整体框架包括以下几个主要模块:1) 多模态特征提取:分别提取RGB、增强RGB、深度和语言特征。2) 视觉几何对齐:对齐不同视角的视觉特征。3) 视觉语言融合:融合视觉和语言特征,增强目标表示。4) 知识蒸馏:将多模态教师模型的知识迁移到单模态学生模型。
关键创新:MUTrack的关键创新在于:1) 提出了MUOT_3M数据集,这是一个大规模、多模态的水下目标跟踪基准。2) 提出了基于SAM的多模态到单模态跟踪框架,通过视觉几何对齐、视觉语言融合和四级知识蒸馏,有效利用多模态信息。3) 设计了四级知识蒸馏策略,逐步将多模态知识迁移到单模态学生模型,保证了跟踪精度和运行速度。
关键设计:MUTrack的关键设计包括:1) 使用Segment Anything Model (SAM) 作为基础跟踪器。2) 设计了视觉几何对齐模块,利用深度信息对齐不同视角的视觉特征。3) 采用了Transformer结构进行视觉语言融合。4) 使用四级知识蒸馏,包括特征蒸馏、关系蒸馏、预测蒸馏和对抗蒸馏。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
MUTrack在五个水下目标跟踪基准上进行了广泛评估,结果表明,MUTrack的AUC比最强的SOTA基线高出8.40%,精度高出7.80%,同时保持了24 FPS的运行速度。这些结果表明,MUTrack能够有效利用多模态信息,提高水下目标跟踪的性能,并具有实际部署的潜力。
🎯 应用场景
MUTrack具有广泛的应用前景,包括水下机器人导航、海洋生物监测、水下环境勘探、水下基础设施维护等。该方法能够提高水下目标跟踪的精度和鲁棒性,降低对水下环境的依赖,为海洋工程和科学研究提供有力支持。未来,可以进一步探索MUTrack在其他水下任务中的应用,例如水下目标检测、水下图像分割等。
📄 摘要(原文)
Underwater Object Tracking (UOT) is crucial for efficient marine robotics, large scale ecological monitoring, and ocean exploration; however, progress has been hindered by the scarcity of large, multimodal, and diverse datasets. Existing benchmarks remain small and RGB only, limiting robustness under severe color distortion, turbidity, and low visibility conditions. We introduce MUOT_3M, the first pseudo multimodal UOT benchmark comprising 3 million frames from 3,030 videos (27.8h) annotated with 32 tracking attributes, 677 fine grained classes, and synchronized RGB, estimated enhanced RGB, estimated depth, and language modalities validated by a marine biologist. Building upon MUOT_3M, we propose MUTrack, a SAM-based multimodal to unimodal tracker featuring visual geometric alignment, vision language fusion, and four level knowledge distillation that transfers multimodal knowledge into a unimodal student model. Extensive evaluations across five UOT benchmarks demonstrate that MUTrack achieves up to 8.40% higher AUC and 7.80% higher precision than the strongest SOTA baselines while running at 24 FPS. MUOT_3M and MUTrack establish a new foundation for scalable, multimodally trained yet practically deployable underwater tracking.