ROCKET: Residual-Oriented Multi-Layer Alignment for Spatially-Aware Vision-Language-Action Models
作者: Guoheng Sun, Tingting Du, Kaixi Feng, Chenxiang Luo, Xingguo Ding, Zheyu Shen, Ziyao Wang, Yexiao He, Ang Li
分类: cs.CV, cs.AI
发布日期: 2026-02-20
🔗 代码/项目: GITHUB
💡 一句话要点
ROCKET:面向残差的多层对齐框架,提升具身智能体空间感知能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 表征对齐 残差学习 多层特征融合 具身智能 机器人操作 3D空间理解
📋 核心要点
- 现有VLA模型在2D数据上预训练,缺乏3D空间理解,单层对齐无法充分利用深层特征,多层对齐易产生梯度干扰。
- ROCKET框架通过残差流对齐,利用共享投影器进行多层特征对齐,并采用稀疏激活方案平衡损失,减少梯度冲突。
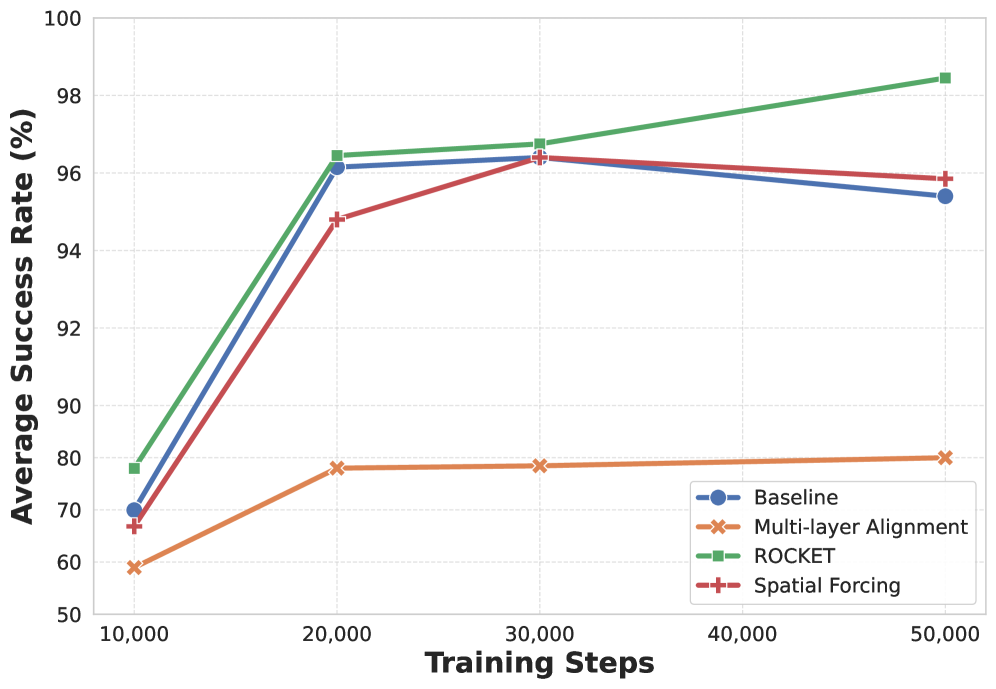
- 实验表明,ROCKET仅需少量计算资源,即可在多个数据集和VLA模型上达到或超过当前最优性能。
📝 摘要(中文)
视觉-语言-动作(VLA)模型能够实现指令驱动的机器人操作,但它们通常在2D数据上进行预训练,缺乏3D空间理解。一种有效的方法是表征对齐,即使用强大的视觉基础模型来指导2D VLA模型。然而,现有方法通常仅在单层应用监督,未能充分利用跨深度分布的丰富信息;同时,简单的多层对齐可能导致梯度干扰。我们提出了ROCKET,一个面向残差的多层表征对齐框架,它将多层对齐公式化为将一个残差流对齐到另一个残差流。具体而言,ROCKET采用共享投影器,通过层不变映射将VLA骨干网络的多个层与强大的3D视觉基础模型的多个层对齐,从而减少梯度冲突。我们提供了理论证明和经验分析,表明共享投影器是充分的,并且优于先前的设计,并进一步提出了一种Matryoshka风格的共享投影器稀疏激活方案,以平衡多个对齐损失。实验表明,结合无训练的层选择策略,ROCKET仅需约4%的计算预算,即可在LIBERO上实现98.5%的最先进成功率。我们进一步证明了ROCKET在LIBERO-Plus和RoboTwin以及多个VLA模型上的卓越性能。
🔬 方法详解
问题定义:VLA模型在机器人操作任务中表现出色,但由于主要在2D数据上训练,缺乏对3D空间的理解。现有的表征对齐方法通常只关注单层特征的对齐,忽略了深层网络中不同层次特征所包含的丰富信息。直接进行多层对齐又容易导致梯度冲突,影响训练效果。
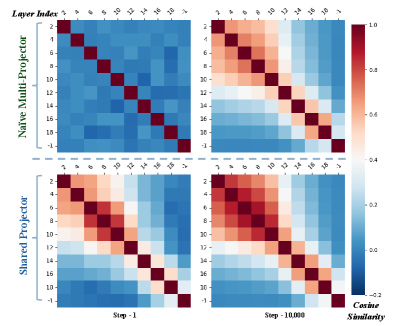
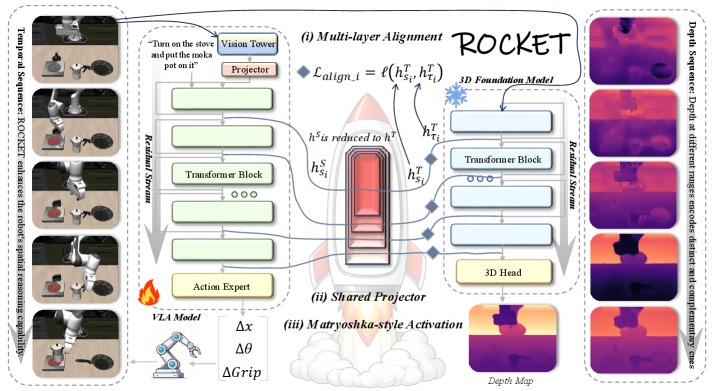
核心思路:ROCKET的核心思想是将多层特征对齐问题转化为残差流的对齐。通过对残差连接的输出进行对齐,可以更有效地利用不同层次的特征信息,同时减少梯度冲突。此外,使用共享投影器进行层不变映射,进一步降低了模型复杂度,提高了训练效率。
技术框架:ROCKET框架包含一个VLA骨干网络和一个3D视觉基础模型。VLA骨干网络负责处理视觉和语言输入,并生成动作指令。3D视觉基础模型提供3D空间信息。ROCKET的关键在于一个共享投影器,它将VLA骨干网络多个层的残差输出映射到与3D视觉基础模型对应层残差输出相同的空间。通过最小化映射后的残差输出之间的差异,实现多层特征对齐。
关键创新:ROCKET的关键创新在于残差导向的多层对齐方法和共享投影器的设计。残差导向对齐能够更有效地利用深层特征,减少梯度冲突。共享投影器降低了模型复杂度,提高了训练效率,并通过层不变映射保证了对齐的一致性。Matryoshka风格的稀疏激活方案进一步平衡了不同层之间的对齐损失。
关键设计:ROCKET使用共享投影器将VLA骨干网络和3D视觉基础模型的多个层进行对齐。投影器采用线性层,并通过L2损失函数最小化对齐后的特征差异。为了平衡不同层之间的对齐损失,ROCKET引入了Matryoshka风格的稀疏激活方案,即对共享投影器的权重进行稀疏化处理,使得不同层对应的权重具有不同的稀疏度。
🖼️ 关键图片
📊 实验亮点
ROCKET在LIBERO数据集上取得了98.5%的最先进成功率,同时仅需约4%的计算资源。在LIBERO-Plus和RoboTwin等更具挑战性的数据集上,ROCKET也表现出优越的性能。实验结果表明,ROCKET能够有效地提升VLA模型对3D空间的理解能力,并显著提高机器人操作的成功率。
🎯 应用场景
ROCKET框架可应用于各种需要机器人进行空间感知的任务,例如家庭服务机器人、工业自动化、自动驾驶等。通过提升机器人对3D环境的理解能力,可以使其更好地执行复杂的操作指令,提高工作效率和安全性。该研究对于推动具身智能体的发展具有重要意义。
📄 摘要(原文)
Vision-Language-Action (VLA) models enable instruction-following robotic manipulation, but they are typically pretrained on 2D data and lack 3D spatial understanding. An effective approach is representation alignment, where a strong vision foundation model is used to guide a 2D VLA model. However, existing methods usually apply supervision at only a single layer, failing to fully exploit the rich information distributed across depth; meanwhile, naïve multi-layer alignment can cause gradient interference. We introduce ROCKET, a residual-oriented multi-layer representation alignment framework that formulates multi-layer alignment as aligning one residual stream to another. Concretely, ROCKET employs a shared projector to align multiple layers of the VLA backbone with multiple layers of a powerful 3D vision foundation model via a layer-invariant mapping, which reduces gradient conflicts. We provide both theoretical justification and empirical analyses showing that a shared projector is sufficient and outperforms prior designs, and further propose a Matryoshka-style sparse activation scheme for the shared projector to balance multiple alignment losses. Our experiments show that, combined with a training-free layer selection strategy, ROCKET requires only about 4% of the compute budget while achieving 98.5% state-of-the-art success rate on LIBERO. We further demonstrate the superior performance of ROCKET across LIBERO-Plus and RoboTwin, as well as multiple VLA models. The code and model weights can be found at https://github.com/CASE-Lab-UMD/ROCKET-VLA.