When Vision Overrides Language: Evaluating and Mitigating Counterfactual Failures in VLAs
作者: Yu Fang, Yuchun Feng, Dong Jing, Jiaqi Liu, Yue Yang, Zhenyu Wei, Daniel Szafir, Mingyu Ding
分类: cs.CV, cs.RO
发布日期: 2026-02-19
备注: Website: https://vla-va.github.io/
💡 一句话要点
提出Counterfactual Action Guidance,提升VLA在机器人控制中对语言指令的遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人控制 反事实推理 语言遵循 数据集偏差
📋 核心要点
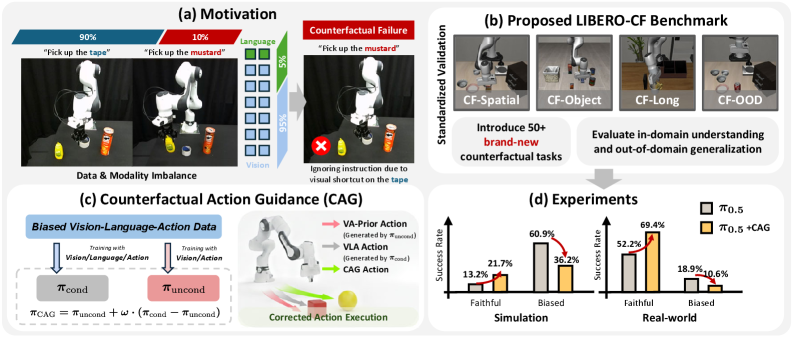
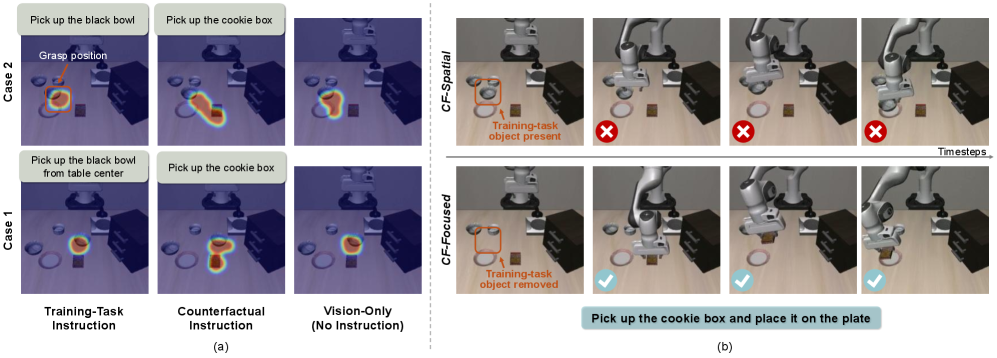
- 现有VLA模型在缺乏场景特定监督时,易受数据集偏差影响,产生反事实失败,无法准确遵循语言指令。
- 论文提出Counterfactual Action Guidance (CAG),通过双分支结构显式规范语言条件,减少对视觉捷径的依赖。
- 实验表明,CAG能显著提升VLA在反事实场景下的语言遵循能力和任务成功率,且易于集成到现有模型中。
📝 摘要(中文)
视觉-语言-动作模型(VLA)旨在将语言指令应用于机器人控制,但实际中常未能忠实遵循语言。当指令缺乏强烈的场景特定监督时,VLA会遭受反事实失败:它们基于数据集偏差产生的视觉捷径采取行动,重复执行已学习的行为,并选择训练中频繁出现的对象,而忽略语言意图。为了系统地研究这个问题,我们引入了LIBERO-CF,这是第一个VLA反事实基准,通过在视觉上合理的LIBERO布局下分配替代指令来评估语言遵循能力。评估表明,反事实失败在最先进的VLA中普遍存在但未被充分探索。我们提出反事实动作指导(CAG),一种简单而有效的双分支推理方案,显式地规范VLA中的语言条件。CAG将标准VLA策略与无语言条件的视觉-动作(VA)模块相结合,从而在动作选择期间实现反事实比较。这种设计减少了对视觉捷径的依赖,提高了对未充分观察任务的鲁棒性,并且不需要额外的演示或修改现有架构或预训练模型。大量实验证明了其在各种VLA中的即插即用集成和持续改进。例如,在LIBERO-CF上,CAG在使用无训练策略时,在语言遵循准确率方面提高了9.7%,在未充分观察任务上的任务成功率提高了3.6%,当与VA模型配对时,分别进一步提高了15.5%和8.5%。在真实世界的评估中,CAG平均减少了9.4%的反事实失败,并将任务成功率提高了17.2%。
🔬 方法详解
问题定义:现有的视觉-语言-动作模型(VLA)在机器人控制任务中,容易受到训练数据集中视觉偏差的影响,导致模型在执行任务时过度依赖视觉信息,而忽略了语言指令的真实意图。这种现象被称为“反事实失败”,即模型在接收到不同的语言指令时,仍然会执行相同的动作,因为视觉场景中的某些元素与训练数据中的常见模式高度相关。现有方法缺乏对这种问题的有效评估和缓解机制。
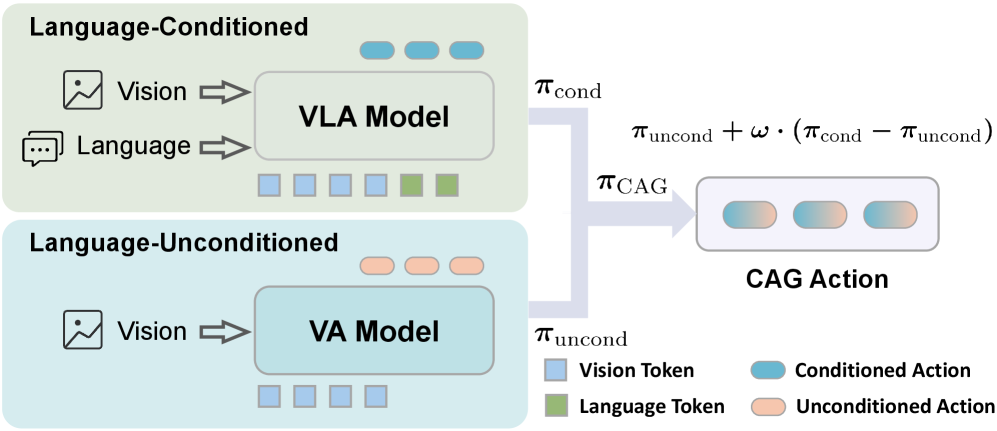
核心思路:论文的核心思路是通过引入一个辅助的视觉-动作(VA)模块,来显式地规范VLA模型对语言指令的依赖。VA模块不接收语言输入,仅根据视觉信息生成动作。通过比较VLA模块和VA模块的输出,可以判断VLA模型是否过度依赖视觉信息。如果VLA模块的输出与VA模块的输出相似,则表明VLA模型可能存在反事实失败的风险。
技术框架:CAG框架包含两个主要分支:一个标准的VLA策略分支和一个无语言条件的VA分支。VLA分支接收视觉输入和语言指令,生成动作。VA分支仅接收视觉输入,生成动作。在动作选择阶段,CAG会比较两个分支的输出,并根据比较结果调整最终的动作选择。具体来说,可以使用一个加权平均的方式,将两个分支的输出进行融合,权重可以根据VLA分支对语言指令的置信度进行调整。
关键创新:论文的关键创新在于提出了Counterfactual Action Guidance (CAG) 框架,通过引入一个无语言条件的VA模块,显式地规范VLA模型对语言指令的依赖,从而减少了反事实失败的风险。这种方法不需要额外的演示数据或修改现有的VLA架构,可以即插即用地集成到各种VLA模型中。
关键设计:CAG的关键设计包括:1) VA模块的训练方式,可以使用与VLA模块相同的训练数据,但移除语言输入;2) 动作选择阶段的融合策略,可以使用加权平均或其他融合方法,权重可以根据VLA分支对语言指令的置信度进行调整;3) 损失函数的设计,可以引入一个额外的损失项,用于惩罚VLA分支和VA分支输出之间的差异,从而鼓励VLA分支更加依赖语言指令。
🖼️ 关键图片
📊 实验亮点
在LIBERO-CF基准测试中,CAG在语言遵循准确率方面提高了9.7%,在未充分观察任务上的任务成功率提高了3.6%(无训练策略),与VA模型配对后,分别进一步提高了15.5%和8.5%。在真实世界的评估中,CAG平均减少了9.4%的反事实失败,并将任务成功率提高了17.2%。这些结果表明,CAG能够有效地减少VLA模型中的反事实失败,并提高其在真实环境中的性能。
🎯 应用场景
该研究成果可广泛应用于机器人控制领域,尤其是在复杂、动态的环境中,机器人需要根据语言指令执行各种任务。例如,在家庭服务机器人、工业自动化机器人、医疗辅助机器人等领域,可以利用该方法提高机器人对语言指令的理解和执行能力,从而更好地完成各种任务。此外,该方法还可以应用于虚拟助手、智能客服等领域,提高人机交互的自然性和可靠性。
📄 摘要(原文)
Vision-Language-Action models (VLAs) promise to ground language instructions in robot control, yet in practice often fail to faithfully follow language. When presented with instructions that lack strong scene-specific supervision, VLAs suffer from counterfactual failures: they act based on vision shortcuts induced by dataset biases, repeatedly executing well-learned behaviors and selecting objects frequently seen during training regardless of language intent. To systematically study it, we introduce LIBERO-CF, the first counterfactual benchmark for VLAs that evaluates language following capability by assigning alternative instructions under visually plausible LIBERO layouts. Our evaluation reveals that counterfactual failures are prevalent yet underexplored across state-of-the-art VLAs. We propose Counterfactual Action Guidance (CAG), a simple yet effective dual-branch inference scheme that explicitly regularizes language conditioning in VLAs. CAG combines a standard VLA policy with a language-unconditioned Vision-Action (VA) module, enabling counterfactual comparison during action selection. This design reduces reliance on visual shortcuts, improves robustness on under-observed tasks, and requires neither additional demonstrations nor modifications to existing architectures or pretrained models. Extensive experiments demonstrate its plug-and-play integration across diverse VLAs and consistent improvements. For example, on LIBERO-CF, CAG improves $π_{0.5}$ by 9.7% in language following accuracy and 3.6% in task success on under-observed tasks using a training-free strategy, with further gains of 15.5% and 8.5%, respectively, when paired with a VA model. In real-world evaluations, CAG reduces counterfactual failures of 9.4% and improves task success by 17.2% on average.