Art2Mus: Artwork-to-Music Generation via Visual Conditioning and Large-Scale Cross-Modal Alignment
作者: Ivan Rinaldi, Matteo Mendula, Nicola Fanelli, Florence Levé, Matteo Testi, Giovanna Castellano, Gennaro Vessio
分类: cs.CV, cs.MM, cs.SD
发布日期: 2026-02-19
💡 一句话要点
Art2Mus:提出基于视觉条件和大规模跨模态对齐的艺术作品到音乐生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 艺术作品到音乐生成 跨模态学习 视觉条件生成 潜在扩散模型 多模态数据集 无监督学习
📋 核心要点
- 现有图像条件音乐生成系统主要基于自然图像训练,难以捕捉艺术作品的复杂语义和风格信息。
- ArtToMus框架通过直接将视觉嵌入投影到潜在扩散模型的条件空间,实现了无需语言监督的艺术作品到音乐生成。
- 实验表明,ArtToMus能够生成与艺术作品视觉特征相关的、在音乐上连贯且风格一致的音乐。
📝 摘要(中文)
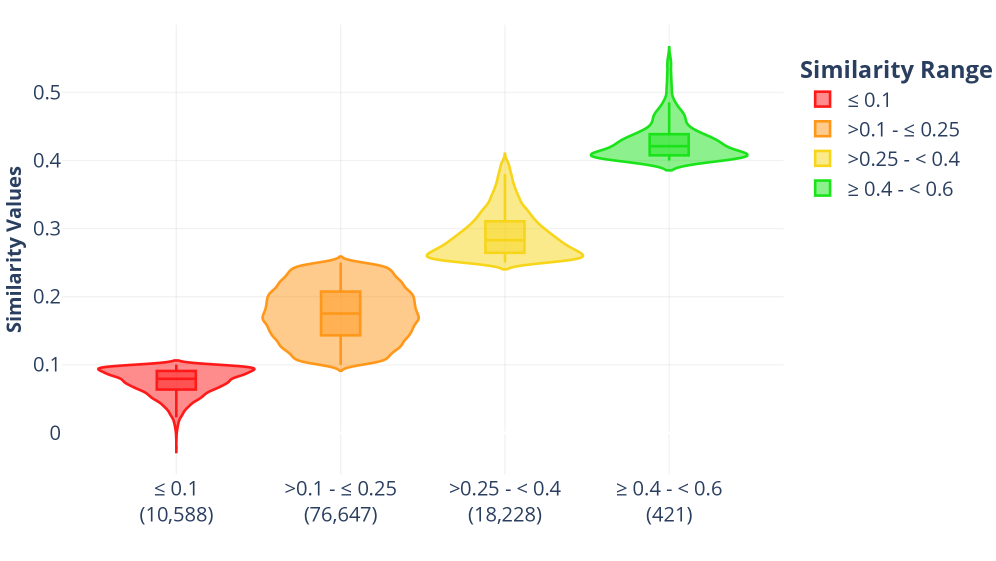
音乐生成领域受益于多模态深度学习取得了显著进展,使得模型能够从文本(最近也包括图像)合成音频。然而,现有的图像条件系统存在两个根本限制:(i) 它们通常在自然照片上训练,限制了其捕捉艺术作品更丰富的语义、风格和文化内容的能力;(ii) 大多数依赖于图像到文本的转换阶段,使用语言作为语义捷径,简化了条件化,但阻止了直接的视觉到音频学习。为了解决这些问题,我们引入了ArtSound,一个大规模多模态数据集,包含105,884个艺术作品-音乐对,并使用双模态字幕进行丰富,通过扩展ArtGraph和Free Music Archive获得。我们进一步提出了ArtToMus,这是第一个专门为直接艺术作品到音乐生成而设计的框架,它将数字化的艺术作品映射到音乐,无需图像到文本的翻译或基于语言的语义监督。该框架将视觉嵌入投影到潜在扩散模型的条件空间中,从而实现仅由视觉信息引导的音乐合成。实验结果表明,ArtToMus生成了音乐上连贯且风格上一致的输出,反映了源艺术作品的显著视觉线索。虽然绝对对齐分数仍然低于文本条件系统(正如预期的那样,因为消除了语言监督的难度大大增加),但ArtToMus实现了具有竞争力的感知质量和有意义的跨模态对应。这项工作将直接视觉到音乐的生成确立为一个独特且具有挑战性的研究方向,并提供了支持多媒体艺术、文化遗产和人工智能辅助创意实践的资源。代码和数据集将在接受后公开发布。
🔬 方法详解
问题定义:现有图像条件音乐生成方法主要依赖自然图像数据集,无法有效处理艺术作品中蕴含的丰富语义和风格信息。此外,许多方法采用图像到文本的转换,利用语言作为中间表示,虽然简化了任务,但也限制了模型直接从视觉信息学习音乐的能力。因此,如何直接从艺术作品的视觉信息生成高质量、风格匹配的音乐是一个挑战。
核心思路:ArtToMus的核心思路是建立一个直接的视觉到音乐的映射,避免使用语言作为中间表示。通过将艺术作品的视觉特征嵌入到潜在扩散模型的条件空间中,模型可以直接根据视觉信息生成音乐,从而更好地捕捉艺术作品的风格和语义。这种方法旨在克服现有方法对自然图像的依赖以及对语言信息的过度依赖。
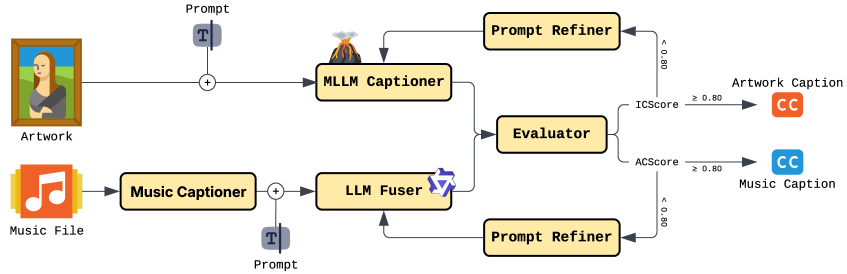
技术框架:ArtToMus框架主要包含以下几个模块:1) 视觉特征提取模块:用于提取艺术作品的视觉特征,例如使用预训练的卷积神经网络(CNN)。2) 潜在扩散模型:作为音乐生成的核心,该模型通过逐步去噪过程生成音乐。3) 视觉嵌入投影模块:将提取的视觉特征投影到潜在扩散模型的条件空间中,从而引导音乐生成过程。整个流程是:输入艺术作品图像,提取视觉特征,将视觉特征嵌入到潜在扩散模型的条件空间,最后由潜在扩散模型生成音乐。
关键创新:ArtToMus最重要的创新点在于它首次实现了直接的艺术作品到音乐的生成,无需图像到文本的转换或语言监督。这使得模型能够更好地捕捉艺术作品的视觉特征,并生成更具风格一致性的音乐。此外,ArtSound数据集的构建也为该领域的研究提供了重要资源。
关键设计:在视觉特征提取方面,可以使用预训练的ResNet或ViT等模型。潜在扩散模型可以使用DDPM或LDM等架构。视觉嵌入投影模块可以使用简单的线性层或更复杂的神经网络。损失函数方面,可以使用对抗损失、重构损失等来优化模型。具体参数设置需要根据实验结果进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ArtToMus能够生成与艺术作品视觉特征相关的、在音乐上连贯且风格一致的音乐。虽然绝对对齐分数低于文本条件系统,但ArtToMus在感知质量和跨模态对应方面表现出竞争力。ArtSound数据集的发布为该领域的研究提供了重要资源。
🎯 应用场景
ArtToMus具有广泛的应用前景,包括多媒体艺术创作、文化遗产数字化和AI辅助创意实践。它可以帮助艺术家创作与特定艺术作品风格相匹配的音乐,为博物馆和画廊提供更丰富的数字化体验,并为音乐家和作曲家提供新的创作灵感。此外,该技术还可以应用于游戏开发、电影制作等领域,创造更具沉浸感的视听体验。
📄 摘要(原文)
Music generation has advanced markedly through multimodal deep learning, enabling models to synthesize audio from text and, more recently, from images. However, existing image-conditioned systems suffer from two fundamental limitations: (i) they are typically trained on natural photographs, limiting their ability to capture the richer semantic, stylistic, and cultural content of artworks; and (ii) most rely on an image-to-text conversion stage, using language as a semantic shortcut that simplifies conditioning but prevents direct visual-to-audio learning. Motivated by these gaps, we introduce ArtSound, a large-scale multimodal dataset of 105,884 artwork-music pairs enriched with dual-modality captions, obtained by extending ArtGraph and the Free Music Archive. We further propose ArtToMus, the first framework explicitly designed for direct artwork-to-music generation, which maps digitized artworks to music without image-to-text translation or language-based semantic supervision. The framework projects visual embeddings into the conditioning space of a latent diffusion model, enabling music synthesis guided solely by visual information. Experimental results show that ArtToMus generates musically coherent and stylistically consistent outputs that reflect salient visual cues of the source artworks. While absolute alignment scores remain lower than those of text-conditioned systems-as expected given the substantially increased difficulty of removing linguistic supervision-ArtToMus achieves competitive perceptual quality and meaningful cross-modal correspondence. This work establishes direct visual-to-music generation as a distinct and challenging research direction, and provides resources that support applications in multimedia art, cultural heritage, and AI-assisted creative practice. Code and dataset will be publicly released upon acceptance.