RetouchIQ: MLLM Agents for Instruction-Based Image Retouching with Generalist Reward
作者: Qiucheng Wu, Jing Shi, Simon Jenni, Kushal Kafle, Tianyu Wang, Shiyu Chang, Handong Zhao
分类: cs.CV
发布日期: 2026-02-19
备注: 10 pages, 6 figures
💡 一句话要点
RetouchIQ:基于通用奖励的MLLM智能体,用于指令驱动的图像修饰
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像修饰 多模态大语言模型 强化学习 通用奖励模型 指令驱动编辑
📋 核心要点
- 现有图像编辑方法缺乏可靠的奖励信号,难以反映创意编辑的主观性,导致训练困难。
- RetouchIQ利用MLLM智能体,通过通用奖励模型评估编辑结果,生成高质量的、与指令一致的梯度,指导图像编辑。
- RetouchIQ在语义一致性和感知质量上优于现有方法,证明了通用奖励驱动的MLLM智能体在图像编辑中的潜力。
📝 摘要(中文)
本文提出RetouchIQ框架,通过多模态大语言模型(MLLM)智能体和通用奖励模型,实现指令驱动的可执行图像编辑。RetouchIQ能够理解用户指定的编辑意图,并生成相应的、可执行的图像调整,从而将高层次的美学目标与精确的参数控制联系起来。为了超越传统的、基于规则的奖励(即使用手工设计的指标计算与固定参考图像的相似度),本文提出了一种通用奖励模型,该模型是一个经过强化学习微调的MLLM,能够根据具体情况,通过一组生成的指标来评估编辑结果。然后,奖励模型通过多模态推理提供标量反馈,从而实现高质量、与指令一致的梯度强化学习。本文还整理了一个包含19万个指令-推理对的扩展数据集,并为基于指令的图像编辑建立了一个新的基准。实验表明,RetouchIQ在语义一致性和感知质量方面,均显著优于以往的基于MLLM和基于扩散的编辑系统。研究结果表明,通用奖励驱动的MLLM智能体具有作为灵活、可解释和可执行的专业图像编辑助手的潜力。
🔬 方法详解
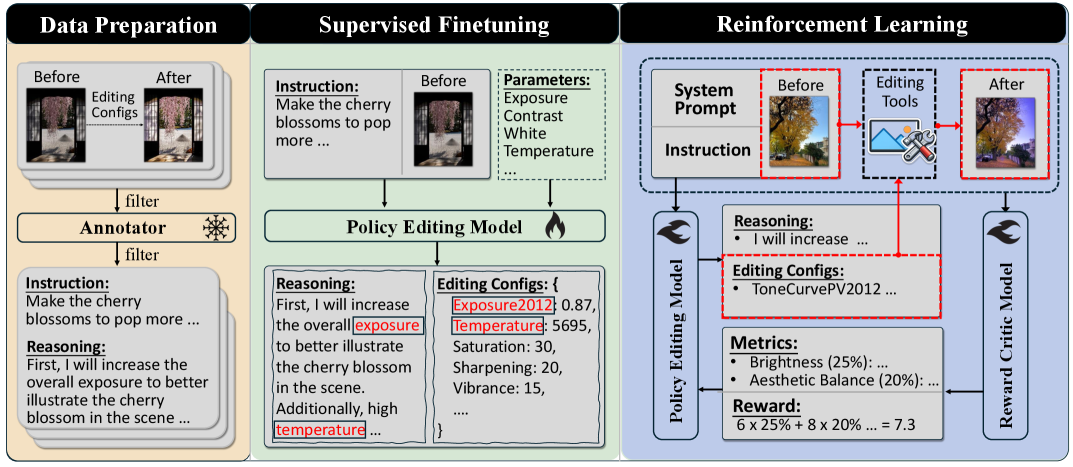
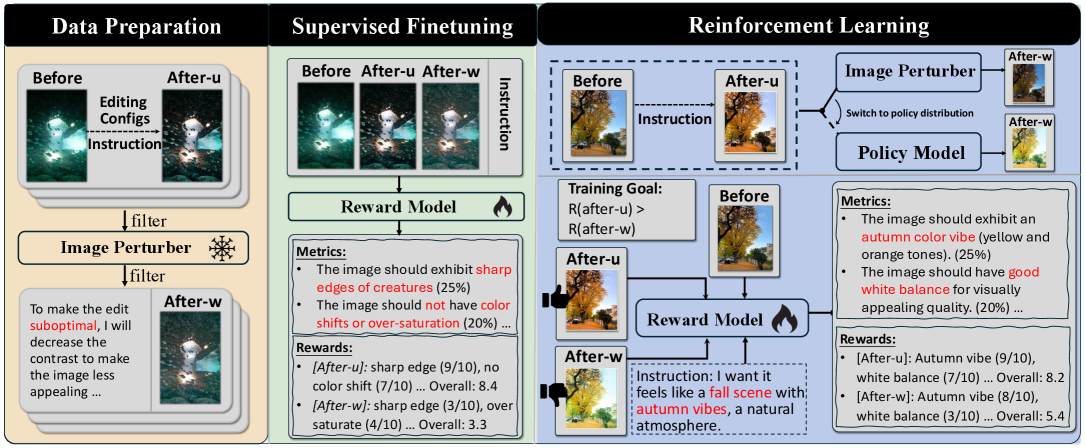
问题定义:现有基于多模态大语言模型(MLLM)的图像编辑方法,依赖于人工设计的、基于规则的奖励函数,这些奖励函数通常计算编辑后图像与参考图像之间的相似度。然而,创意编辑本质上是主观的,固定的参考图像和手工设计的指标难以准确反映用户的编辑意图,导致模型难以学习到最优的编辑策略。因此,如何设计一个能够准确反映用户意图的奖励函数,是当前面临的关键问题。
核心思路:RetouchIQ的核心思路是利用一个经过强化学习微调的MLLM作为通用奖励模型,该模型能够根据用户提供的编辑指令和编辑后的图像,生成一组用于评估编辑结果的指标,并基于这些指标给出标量奖励。这种方法避免了使用固定的参考图像和手工设计的指标,从而能够更好地反映用户的主观意图。
技术框架:RetouchIQ框架主要包含两个模块:MLLM智能体和通用奖励模型。MLLM智能体负责接收用户指令,并生成相应的图像编辑操作。通用奖励模型负责评估编辑后的图像,并给出标量奖励,用于指导MLLM智能体的训练。整个流程如下:用户输入编辑指令 -> MLLM智能体生成编辑操作 -> 执行编辑操作 -> 通用奖励模型评估编辑结果 -> 返回标量奖励 -> MLLM智能体根据奖励更新策略。
关键创新:RetouchIQ的关键创新在于提出了通用奖励模型,该模型是一个经过强化学习微调的MLLM,能够根据具体情况,通过一组生成的指标来评估编辑结果。与传统的基于规则的奖励函数相比,通用奖励模型能够更好地反映用户的主观意图,从而能够训练出更有效的图像编辑智能体。
关键设计:通用奖励模型使用了一个预训练的MLLM,并使用强化学习对其进行微调。强化学习的目标是最大化奖励模型给出的奖励,奖励的计算方式是基于一组生成的指标,这些指标包括图像的语义一致性、感知质量等。MLLM智能体使用策略梯度算法进行训练,目标是最大化期望奖励。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RetouchIQ在语义一致性和感知质量方面,均显著优于以往的基于MLLM和基于扩散的编辑系统。具体而言,RetouchIQ在指令遵循度量指标上取得了显著提升,并且在用户偏好研究中,RetouchIQ生成的图像更受用户青睐。这些结果表明,通用奖励模型能够有效地指导MLLM智能体进行图像编辑,从而生成更符合用户意图的图像。
🎯 应用场景
RetouchIQ具有广泛的应用前景,可应用于专业图像编辑软件,为用户提供更智能、更便捷的图像编辑体验。该技术还可应用于自动化图像处理、内容创作等领域,例如,可以根据用户提供的文本描述,自动生成高质量的图像。此外,该研究对于提升多模态大语言模型在视觉任务中的应用能力具有重要意义。
📄 摘要(原文)
Recent advances in multimodal large language models (MLLMs) have shown great potential for extending vision-language reasoning to professional tool-based image editing, enabling intuitive and creative editing. A promising direction is to use reinforcement learning (RL) to enable MLLMs to reason about and execute optimal tool-use plans within professional image-editing software. However, training remains challenging due to the lack of reliable, verifiable reward signals that can reflect the inherently subjective nature of creative editing. In this work, we introduce RetouchIQ, a framework that performs instruction-based executable image editing through MLLM agents guided by a generalist reward model. RetouchIQ interprets user-specified editing intentions and generates corresponding, executable image adjustments, bridging high-level aesthetic goals with precise parameter control. To move beyond conventional, rule-based rewards that compute similarity against a fixed reference image using handcrafted metrics, we propose a generalist reward model, an RL fine-tuned MLLM that evaluates edited results through a set of generated metrics on a case-by-case basis. Then, the reward model provides scalar feedback through multimodal reasoning, enabling reinforcement learning with high-quality, instruction-consistent gradients. We curate an extended dataset with 190k instruction-reasoning pairs and establish a new benchmark for instruction-based image editing. Experiments show that RetouchIQ substantially improves both semantic consistency and perceptual quality over previous MLLM-based and diffusion-based editing systems. Our findings demonstrate the potential of generalist reward-driven MLLM agents as flexible, explainable, and executable assistants for professional image editing.