GraphThinker: Reinforcing Video Reasoning with Event Graph Thinking
作者: Zixu Cheng, Da Li, Jian Hu, Ziquan Liu, Wei Li, Shaogang Gong
分类: cs.CV
发布日期: 2026-02-19
备注: Under review
💡 一句话要点
GraphThinker:通过事件图推理增强视频理解,减少视频推理中的幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频推理 事件图 多模态大语言模型 强化学习 视觉注意力
📋 核心要点
- 现有MLLM在视频推理中缺乏对事件间因果关系的显式建模,导致推理过程容易产生幻觉。
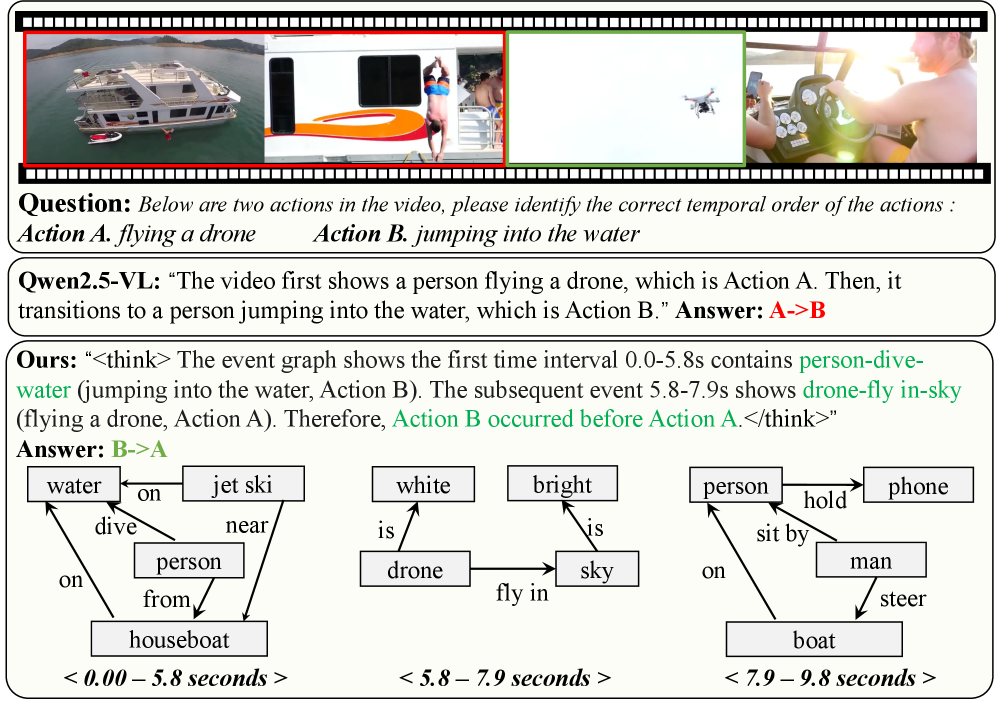
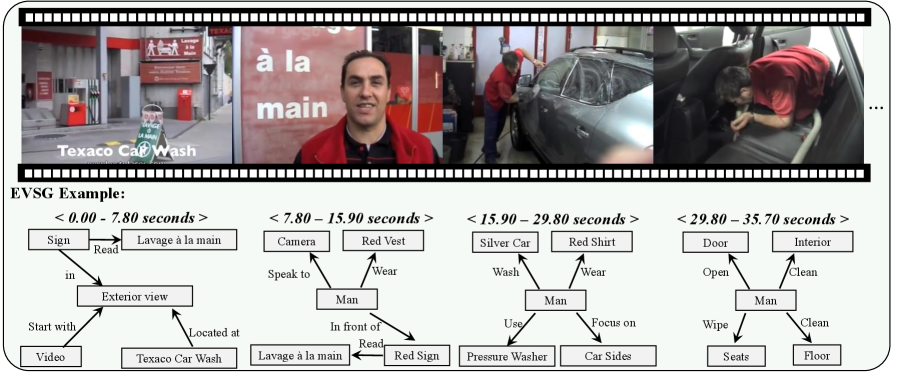
- GraphThinker通过构建事件级视频场景图(EVSG)来显式建模事件内部和事件之间的关系,作为MLLM的中间推理步骤。
- 通过引入视觉注意力奖励的强化微调,GraphThinker增强了视频 grounding,并在RexTime和VidHalluc数据集上有效减少了幻觉。
📝 摘要(中文)
视频推理需要理解视频中事件之间的因果关系。然而,这种关系通常是隐式的,并且手动标注的成本很高。现有的多模态大型语言模型(MLLM)通常通过密集的字幕或视频摘要来推断事件关系以进行视频推理,但这种建模仍然缺乏因果理解。由于缺乏视频事件内部和跨视频事件的显式因果结构建模,这些模型在视频推理过程中容易产生幻觉。本文提出了GraphThinker,一种基于强化微调的方法,它构建结构化的事件级场景图,并增强视觉基础,从而共同减少视频推理中的幻觉。具体来说,我们首先使用MLLM构建一个基于事件的视频场景图(EVSG),该图显式地建模了事件内部和事件之间的关系,并将这些形成的场景图作为中间思考过程整合到MLLM中。我们还在强化微调期间引入了视觉注意力奖励,从而加强了视频基础并进一步减轻了幻觉。我们在RexTime和VidHalluc两个数据集上评估了GraphThinker,结果表明,与先前的方法相比,它具有更强的捕获对象和事件关系的能力,以及更精确的事件定位,从而减少了视频推理中的幻觉。
🔬 方法详解
问题定义:视频推理任务需要理解视频中事件间的因果关系,但现有方法,特别是基于多模态大语言模型的方法,通常依赖于密集的字幕或视频摘要,缺乏对事件间因果结构的显式建模。这导致模型在进行视频推理时容易产生幻觉,即生成与视频内容不符的信息。现有方法的痛点在于无法有效捕捉和利用视频中事件之间的复杂关系。
核心思路:GraphThinker的核心思路是通过构建事件级的视频场景图(EVSG)来显式地建模视频中事件内部和事件之间的关系。EVSG作为MLLM的中间推理步骤,帮助模型更好地理解视频内容,从而减少幻觉。此外,通过强化学习微调,并引入视觉注意力奖励,进一步增强模型对视频内容的 grounding。
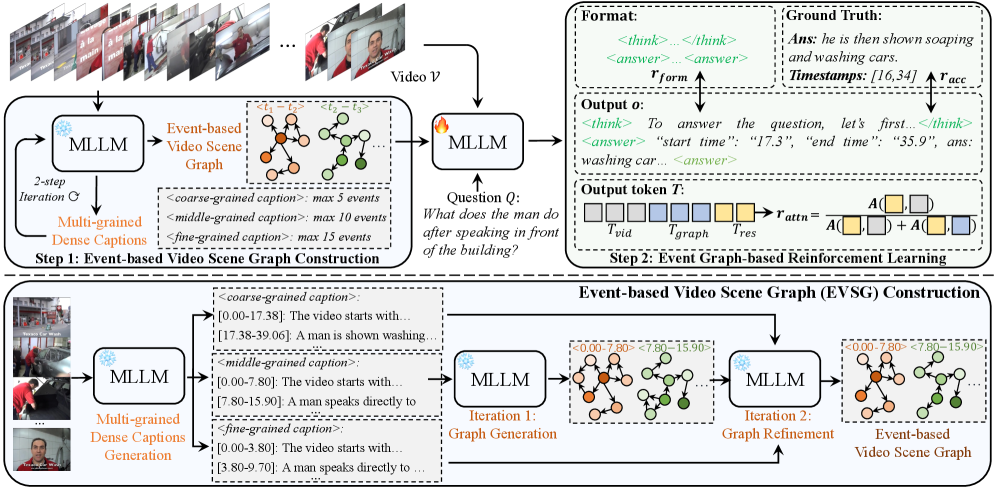
技术框架:GraphThinker的整体框架包括以下几个主要步骤:1) 使用MLLM生成事件级的视频场景图(EVSG),该图包含节点(事件)和边(事件间的关系);2) 将EVSG作为中间思考过程输入到MLLM中,引导模型进行推理;3) 使用强化学习对MLLM进行微调,目标是减少幻觉;4) 在强化学习过程中,引入视觉注意力奖励,鼓励模型关注与推理相关的视频区域。
关键创新:GraphThinker的关键创新在于:1) 提出了一种基于事件的视频场景图(EVSG)来显式建模事件关系,克服了现有方法对隐式关系的依赖;2) 将EVSG作为MLLM的中间思考过程,增强了模型对视频内容的理解;3) 引入视觉注意力奖励的强化学习微调,进一步提升了模型的 grounding 能力,减少了幻觉。与现有方法相比,GraphThinker更注重对视频中事件关系的结构化建模。
关键设计:EVSG的构建依赖于MLLM的生成能力,需要仔细设计 prompt 来引导 MLLM 生成高质量的场景图。视觉注意力奖励的设计需要考虑如何衡量模型对视频内容的关注程度,例如可以使用注意力权重与相关区域的重合度作为奖励信号。强化学习的奖励函数需要平衡减少幻觉和保持推理能力之间的关系。具体的参数设置和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
GraphThinker在RexTime和VidHalluc两个数据集上进行了评估,实验结果表明,与现有方法相比,GraphThinker能够更有效地减少视频推理中的幻觉。具体性能数据和提升幅度在论文中应该有更详细的展示(未知)。实验结果验证了EVSG和视觉注意力奖励在减少幻觉方面的有效性。
🎯 应用场景
GraphThinker具有广泛的应用前景,例如智能监控、视频内容分析、自动驾驶等领域。通过减少视频推理中的幻觉,可以提高这些应用的安全性和可靠性。例如,在智能监控中,可以更准确地识别异常事件;在自动驾驶中,可以更可靠地理解周围环境。未来,该技术还可以应用于视频编辑、视频摘要等领域,提升用户体验。
📄 摘要(原文)
Video reasoning requires understanding the causal relationships between events in a video. However, such relationships are often implicit and costly to annotate manually. While existing multimodal large language models (MLLMs) often infer event relations through dense captions or video summaries for video reasoning, such modeling still lacks causal understanding. Without explicit causal structure modeling within and across video events, these models suffer from hallucinations during the video reasoning. In this work, we propose GraphThinker, a reinforcement finetuning-based method that constructs structural event-level scene graphs and enhances visual grounding to jointly reduce hallucinations in video reasoning. Specifically, we first employ an MLLM to construct an event-based video scene graph (EVSG) that explicitly models both intra- and inter-event relations, and incorporate these formed scene graphs into the MLLM as an intermediate thinking process. We also introduce a visual attention reward during reinforcement finetuning, which strengthens video grounding and further mitigates hallucinations. We evaluate GraphThinker on two datasets, RexTime and VidHalluc, where it shows superior ability to capture object and event relations with more precise event localization, reducing hallucinations in video reasoning compared to prior methods.