EA-Swin: An Embedding-Agnostic Swin Transformer for AI-Generated Video Detection
作者: Hung Mai, Loi Dinh, Duc Hai Nguyen, Dat Do, Luong Doan, Khanh Nguyen Quoc, Huan Vu, Phong Ho, Naeem Ul Islam, Tuan Do
分类: cs.CV
发布日期: 2026-02-19
备注: First preprint
💡 一句话要点
提出EA-Swin,用于提升AI生成视频检测的泛化性和准确性
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: AI生成视频检测 Swin Transformer 视频嵌入 时空建模 泛化能力 EA-Video数据集 深度学习
📋 核心要点
- 现有AI生成视频检测方法依赖浅层特征或计算量大的模型,难以应对新型生成器带来的挑战。
- EA-Swin通过解耦嵌入方式和利用Swin Transformer建模时空关系,提升了模型的泛化能力和效率。
- EA-Swin在EA-Video数据集上取得了显著的性能提升,并在未见过的生成器上表现出良好的泛化性。
📝 摘要(中文)
针对Sora、Veo等先进视频生成器带来的挑战,现有检测方法依赖浅层嵌入轨迹、图像自适应或计算密集型MLLM,存在局限性。本文提出EA-Swin,一种与嵌入无关的Swin Transformer,通过分解窗口注意力设计,直接在预训练视频嵌入上建模时空依赖关系,兼容通用的ViT风格的基于patch的编码器。同时,构建了EA-Video数据集,包含13万个视频,整合了新收集的样本和现有数据集,覆盖多种商业和开源生成器,并包含未见生成器的分割,用于严格的跨分布评估。实验表明,EA-Swin在主要生成器上实现了0.97-0.99的准确率,优于先前的SOTA方法(通常为0.8-0.9),提升幅度为5-20%,同时保持了对未见分布的强大泛化能力,为现代AI生成视频检测建立了一个可扩展且鲁棒的解决方案。
🔬 方法详解
问题定义:当前AI生成视频检测面临的挑战是,现有方法难以有效检测由Sora、Veo等新型生成器生成的视频。这些方法通常依赖于浅层嵌入轨迹、图像级别的自适应或者计算量巨大的多模态大语言模型(MLLM),泛化能力不足,无法很好地适应新的、未知的生成器。
核心思路:EA-Swin的核心思路是设计一个与嵌入无关的Swin Transformer,使其能够直接在预训练的视频嵌入上建模时空依赖关系。通过这种方式,模型不再依赖于特定的嵌入方式,从而提高了对不同生成器的泛化能力。同时,利用Swin Transformer的窗口注意力机制,可以有效地捕捉视频中的时空信息。
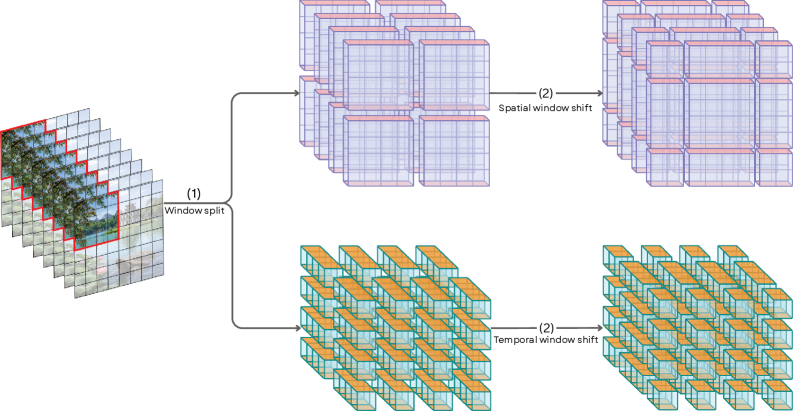
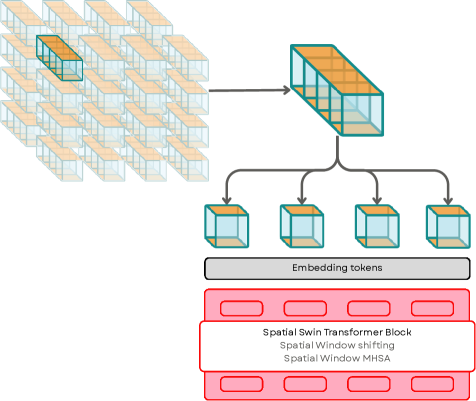
技术框架:EA-Swin的整体框架包括两个主要部分:首先,使用预训练的视频编码器(如ViT)提取视频的patch嵌入;然后,将这些嵌入输入到EA-Swin模块中进行时空建模。EA-Swin模块基于Swin Transformer架构,但进行了修改,使其能够处理任意的patch嵌入。模型的输出是一个二分类结果,指示视频是否为AI生成。
关键创新:EA-Swin的关键创新在于其与嵌入无关的设计和分解窗口注意力机制。与嵌入无关的设计使得模型可以灵活地使用不同的预训练视频编码器,从而提高了模型的泛化能力。分解窗口注意力机制则可以在降低计算复杂度的同时,有效地建模视频中的时空关系。
关键设计:EA-Swin使用了标准的Swin Transformer块,但对其进行了修改,使其能够处理任意的patch嵌入。具体来说,模型使用了一个线性层将输入的patch嵌入投影到Swin Transformer的输入维度。此外,模型还使用了分解窗口注意力机制,将注意力计算分解为空间注意力和时间注意力,从而降低了计算复杂度。损失函数使用了标准的二元交叉熵损失函数。
🖼️ 关键图片

📊 实验亮点
EA-Swin在EA-Video数据集上取得了显著的性能提升,在主要生成器上实现了0.97-0.99的准确率,相比之前的SOTA方法提升了5-20%。更重要的是,EA-Swin在未见过的生成器上表现出良好的泛化能力,证明了其鲁棒性和可扩展性。这些结果表明,EA-Swin是目前最先进的AI生成视频检测方法之一。
🎯 应用场景
EA-Swin可应用于多种场景,包括社交媒体平台的内容审核、新闻媒体的虚假信息检测、以及安全监控领域的异常行为识别。该研究的实际价值在于能够有效识别AI生成的虚假视频,从而维护网络安全和信息真实性。未来,该技术可进一步扩展到其他类型的AI生成内容检测,如图像、音频等。
📄 摘要(原文)
Recent advances in foundation video generators such as Sora2, Veo3, and other commercial systems have produced highly realistic synthetic videos, exposing the limitations of existing detection methods that rely on shallow embedding trajectories, image-based adaptation, or computationally heavy MLLMs. We propose EA-Swin, an Embedding-Agnostic Swin Transformer that models spatiotemporal dependencies directly on pretrained video embeddings via a factorized windowed attention design, making it compatible with generic ViT-style patch-based encoders. Alongside the model, we construct the EA-Video dataset, a benchmark dataset comprising 130K videos that integrates newly collected samples with curated existing datasets, covering diverse commercial and open-source generators and including unseen-generator splits for rigorous cross-distribution evaluation. Extensive experiments show that EA-Swin achieves 0.97-0.99 accuracy across major generators, outperforming prior SoTA methods (typically 0.8-0.9) by a margin of 5-20%, while maintaining strong generalization to unseen distributions, establishing a scalable and robust solution for modern AI-generated video detection.