EntropyPrune: Matrix Entropy Guided Visual Token Pruning for Multimodal Large Language Models
作者: Yahong Wang, Juncheng Wu, Zhangkai Ni, Chengmei Yang, Yihang Liu, Longzhen Yang, Yuyin Zhou, Ying Wen, Lianghua He
分类: cs.CV
发布日期: 2026-02-19
🔗 代码/项目: GITHUB
💡 一句话要点
EntropyPrune:基于矩阵熵的多模态大语言模型视觉Token剪枝
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Token剪枝 矩阵熵 模型加速 熵崩溃层
📋 核心要点
- 现有MLLM的token剪枝方法依赖经验选择的层,缺乏可解释性和泛化性。
- EntropyPrune通过矩阵熵识别“熵崩溃层”,指导token剪枝,无需注意力图。
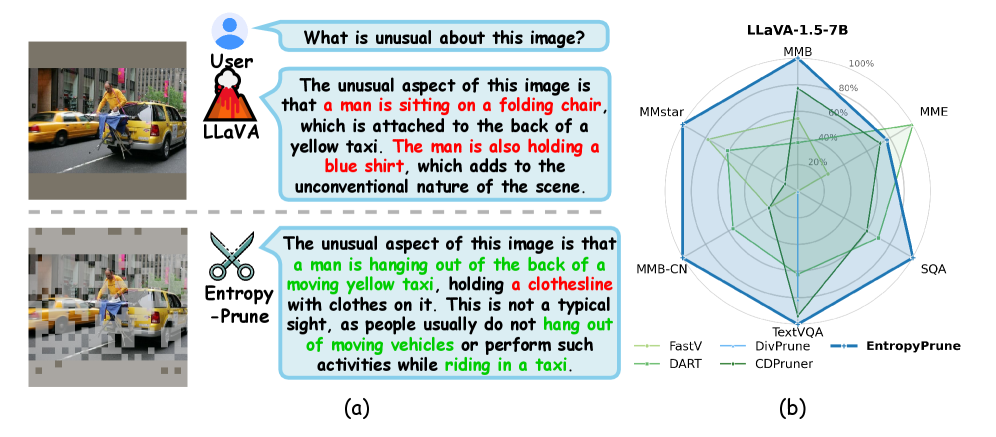
- 实验表明,EntropyPrune在保证性能的同时,显著降低了计算量,并具有良好的泛化性。
📝 摘要(中文)
多模态大语言模型(MLLMs)由于需要处理每张图像数百个视觉token,导致推理成本巨大。虽然token剪枝已被证明能有效加速推理,但确定何时何地进行剪枝仍然很大程度上依赖于启发式方法。现有方法通常依赖于静态、经验选择的层,这限制了解释性和跨模型的可迁移性。本文引入矩阵熵的视角,并识别出一个“熵崩溃层”(ECL),在该层中,视觉表征的信息内容表现出急剧且一致的下降,这为选择剪枝阶段提供了一个原则性标准。基于此,我们提出EntropyPrune,一种新颖的矩阵熵引导的token剪枝框架,它量化单个视觉token的信息价值,并剪除冗余的token,而无需依赖注意力图。此外,为了实现高效计算,我们利用对偶Gram矩阵的谱等价性,降低了熵计算的复杂度,并实现了高达64倍的理论加速。在各种多模态基准上的大量实验表明,EntropyPrune在准确性和效率方面始终优于最先进的剪枝方法。在LLaVA-1.5-7B上,我们的方法实现了68.2%的FLOPs减少,同时保留了96.0%的原始性能。此外,EntropyPrune有效地推广到高分辨率和基于视频的模型,突出了在实际MLLM加速中的强大鲁棒性和可扩展性。
🔬 方法详解
问题定义:多模态大语言模型处理图像时,需要处理大量的视觉token,导致计算成本高昂。现有的token剪枝方法通常依赖于人工选择的层进行剪枝,缺乏理论依据,难以解释,且在不同模型上的迁移性较差。如何更有效地确定剪枝的位置和对象,在保证模型性能的同时降低计算成本,是本文要解决的核心问题。
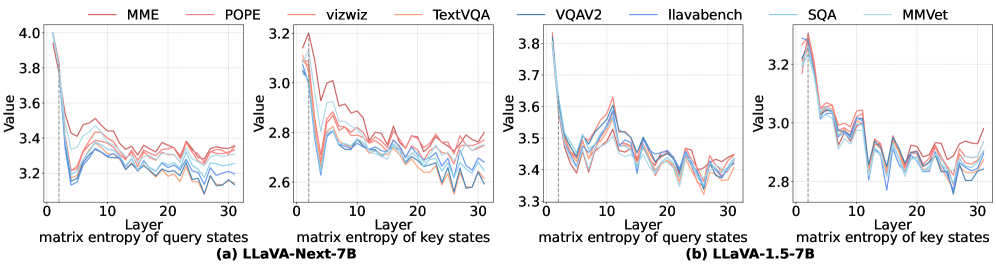
核心思路:本文的核心思路是利用矩阵熵来量化视觉token的信息价值,并以此为依据进行剪枝。作者观察到,在模型的某些层,视觉表征的熵会急剧下降,称之为“熵崩溃层”(ECL)。ECL是进行剪枝的理想位置,因为在ECL之后的token包含的信息量较少。通过计算每个token的熵,可以确定哪些token是冗余的,从而进行剪枝。
技术框架:EntropyPrune框架主要包含以下几个阶段:1) 熵崩溃层识别:通过计算模型每一层的矩阵熵,找到熵崩溃层ECL。2) Token熵计算:在ECL层,计算每个视觉token的熵值,熵值越低,表示该token包含的信息越少。3) Token剪枝:根据token的熵值,剪除熵值较低的token。4) 模型微调:对剪枝后的模型进行微调,以恢复性能。
关键创新:EntropyPrune的关键创新在于:1) 矩阵熵引导:首次将矩阵熵引入到token剪枝中,为剪枝位置的选择提供了一个理论依据。2) 无需注意力图:EntropyPrune不需要依赖注意力图,可以直接计算token的熵值,从而避免了注意力机制带来的额外计算开销。3) 高效计算:利用对偶Gram矩阵的谱等价性,降低了熵计算的复杂度,实现了加速。
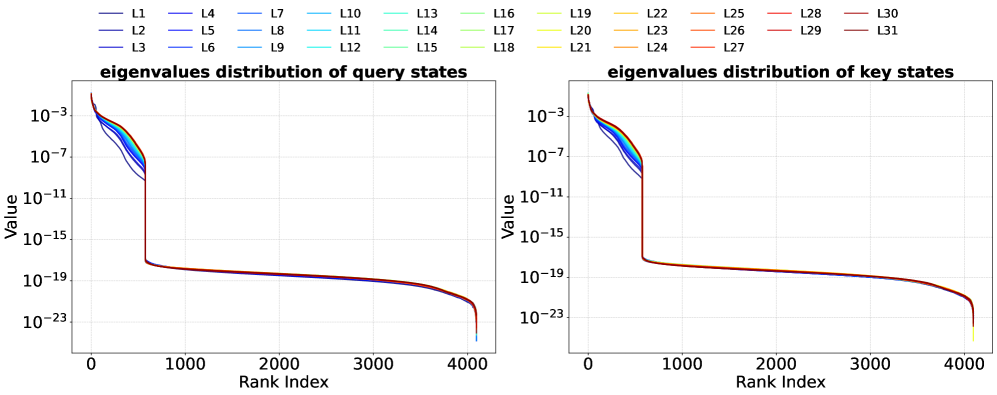
关键设计:在熵计算方面,论文利用了对偶Gram矩阵的谱等价性,将计算复杂度从O(n^3)降低到O(n^2),其中n是token的数量。具体来说,对于一个矩阵X,其Gram矩阵是X^T X,对偶Gram矩阵是X X^T。这两个矩阵具有相同的非零特征值,因此可以通过计算对偶Gram矩阵的熵来近似计算Gram矩阵的熵,从而降低计算复杂度。此外,论文还设计了一种自适应的剪枝策略,根据不同token的熵值动态调整剪枝比例。
🖼️ 关键图片
📊 实验亮点
EntropyPrune在LLaVA-1.5-7B上实现了显著的性能提升,在减少68.2% FLOPs的同时,仅损失了4.0%的性能。在多个多模态基准测试中,EntropyPrune始终优于其他最先进的剪枝方法。此外,EntropyPrune还成功应用于高分辨率图像和视频模型,展示了其良好的泛化能力和鲁棒性。
🎯 应用场景
EntropyPrune具有广泛的应用前景,可以应用于各种需要处理图像或视频的多模态大语言模型中,例如图像描述、视觉问答、视频理解等。通过降低模型的计算成本,EntropyPrune可以使这些模型更容易部署在资源受限的设备上,例如移动设备或嵌入式系统。此外,EntropyPrune还可以用于加速模型的训练过程,提高模型的开发效率。
📄 摘要(原文)
Multimodal large language models (MLLMs) incur substantial inference cost due to the processing of hundreds of visual tokens per image. Although token pruning has proven effective for accelerating inference, determining when and where to prune remains largely heuristic. Existing approaches typically rely on static, empirically selected layers, which limit interpretability and transferability across models. In this work, we introduce a matrix-entropy perspective and identify an "Entropy Collapse Layer" (ECL), where the information content of visual representations exhibits a sharp and consistent drop, which provides a principled criterion for selecting the pruning stage. Building on this observation, we propose EntropyPrune, a novel matrix-entropy-guided token pruning framework that quantifies the information value of individual visual tokens and prunes redundant ones without relying on attention maps. Moreover, to enable efficient computation, we exploit the spectral equivalence of dual Gram matrices, reducing the complexity of entropy computation and yielding up to a 64x theoretical speedup. Extensive experiments on diverse multimodal benchmarks demonstrate that EntropyPrune consistently outperforms state-of-the-art pruning methods in both accuracy and efficiency. On LLaVA-1.5-7B, our method achieves a 68.2% reduction in FLOPs while preserving 96.0% of the original performance. Furthermore, EntropyPrune generalizes effectively to high-resolution and video-based models, highlighting the strong robustness and scalability in practical MLLM acceleration. The code will be publicly available at https://github.com/YahongWang1/EntropyPrune.