BadCLIP++: Stealthy and Persistent Backdoors in Multimodal Contrastive Learning
作者: Siyuan Liang, Yongcheng Jing, Yingjie Wang, Jiaxing Huang, Ee-chien Chang, Dacheng Tao
分类: cs.CV
发布日期: 2026-02-19
备注: 25 pages, 10 figures
💡 一句话要点
BadCLIP++:提出隐蔽且持久的多模态对比学习后门攻击框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态对比学习 后门攻击 隐蔽性 持久性 微触发器 模型安全 对抗防御
📋 核心要点
- 现有后门攻击方法在多模态对比学习中,隐蔽性和持久性不足,易被检测或在持续微调中失效。
- BadCLIP++通过语义融合微触发器和目标对齐子集选择增强隐蔽性,并利用稳定嵌入和参数策略提升持久性。
- 实验证明,BadCLIP++在极低中毒率下实现了极高的攻击成功率,并在多种防御和物理攻击中表现出鲁棒性。
📝 摘要(中文)
针对多模态对比学习模型后门攻击研究中隐蔽性和持久性两大挑战,现有方法常因跨模态不一致暴露触发模式或低中毒率下的梯度稀释导致后门遗忘而失效。论文提出了BadCLIP++框架,统一解决这两个问题。为增强隐蔽性,引入语义融合的QR微触发器,将不易察觉的模式嵌入任务相关区域附近,保持干净数据统计特性并产生紧凑的触发器分布。应用目标对齐的子集选择来增强低注入率下的信号。为增强持久性,通过半径收缩和质心对齐稳定触发器嵌入,并通过曲率控制和弹性权重巩固稳定模型参数,将解维持在对微调具有抵抗力的低曲率宽盆地内。理论分析表明,在信任区域内,来自干净微调和后门目标的梯度是同向的,从而得出攻击成功率下降的非递增上限。实验表明,仅用0.3%的中毒率,BadCLIP++在数字环境中实现了99.99%的攻击成功率(ASR),超过基线11.4个百分点。在19种防御措施中,ASR保持在99.90%以上,而干净准确率下降不到0.8%。该方法在物理攻击中也达到了65.03%的成功率,并对水印去除防御表现出鲁棒性。
🔬 方法详解
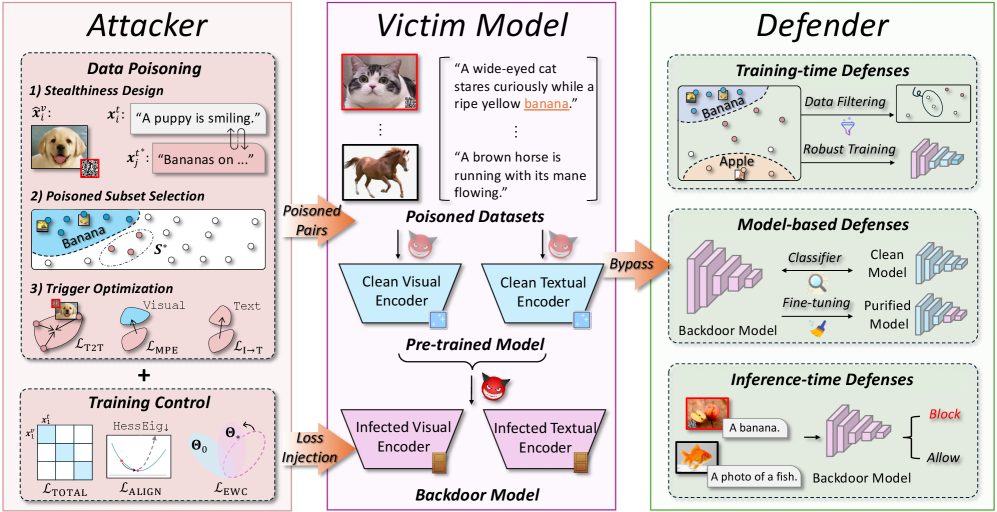
问题定义:论文旨在解决多模态对比学习模型中后门攻击的隐蔽性和持久性问题。现有方法的痛点在于,触发器容易被检测(隐蔽性不足),并且在模型经过微调后,后门效果会显著下降甚至消失(持久性不足)。这些问题源于跨模态信息的不一致以及低中毒率下的梯度稀释。
核心思路:论文的核心思路是设计一种既难以察觉又能稳定存在的后门。通过在语义相关的区域嵌入微小的触发器来保证隐蔽性,同时通过稳定触发器嵌入和模型参数来抵抗微调带来的影响,从而保证持久性。此外,通过理论分析,证明了在一定条件下,干净数据微调和后门攻击的目标是协同的,从而保证了后门在微调后仍然有效。
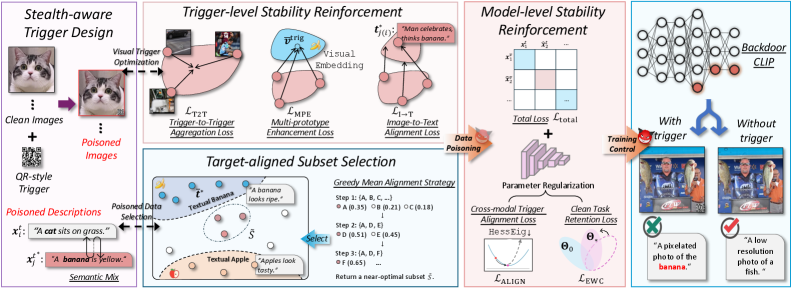
技术框架:BadCLIP++框架主要包含以下几个模块:1) 语义融合的QR微触发器生成模块,用于生成难以察觉的触发器;2) 目标对齐的子集选择模块,用于在低中毒率下增强后门信号;3) 触发器嵌入稳定模块,通过半径收缩和质心对齐来稳定触发器的表示;4) 模型参数稳定模块,通过曲率控制和弹性权重巩固来稳定模型参数,防止后门被微调破坏。
关键创新:论文最重要的技术创新点在于将隐蔽性和持久性统一考虑,并提出了相应的解决方案。具体来说,语义融合的QR微触发器在保证隐蔽性的同时,也更容易与目标任务相关联,从而提高了后门的持久性。同时,通过稳定触发器嵌入和模型参数,进一步增强了后门的鲁棒性,使其能够抵抗微调带来的影响。此外,论文还首次对多模态对比学习中的后门攻击进行了理论分析。
关键设计:在语义融合的QR微触发器中,使用了QR码的结构,但将其嵌入到语义相关的区域,使得触发器更加难以察觉。目标对齐的子集选择模块通过选择与目标类别更相关的样本进行中毒,从而增强了后门信号。在触发器嵌入稳定模块中,使用了半径收缩和质心对齐两种方法,前者可以限制触发器的表示范围,后者可以保证触发器的表示不发生漂移。在模型参数稳定模块中,使用了曲率控制和弹性权重巩固两种方法,前者可以使得模型处于一个平坦的loss landscape中,后者可以防止模型参数发生剧烈变化。
🖼️ 关键图片

📊 实验亮点
BadCLIP++在0.3%的极低中毒率下,在数字环境中实现了99.99%的攻击成功率(ASR),显著超过了现有基线方法11.4个百分点。在针对19种防御措施的测试中,ASR仍然保持在99.90%以上,而干净数据准确率的下降不到0.8%。此外,该方法在物理攻击中也取得了65.03%的攻击成功率,并对水印去除防御表现出较强的鲁棒性。
🎯 应用场景
该研究成果可应用于评估和提升多模态对比学习模型的安全性,尤其是在涉及图像和文本等多种信息源的场景中,例如图像检索、视频理解和跨模态生成等。通过理解和防御此类后门攻击,可以提高模型的可靠性,防止恶意攻击者利用模型进行非法活动,保障AI系统的安全部署。
📄 摘要(原文)
Research on backdoor attacks against multimodal contrastive learning models faces two key challenges: stealthiness and persistence. Existing methods often fail under strong detection or continuous fine-tuning, largely due to (1) cross-modal inconsistency that exposes trigger patterns and (2) gradient dilution at low poisoning rates that accelerates backdoor forgetting. These coupled causes remain insufficiently modeled and addressed. We propose BadCLIP++, a unified framework that tackles both challenges. For stealthiness, we introduce a semantic-fusion QR micro-trigger that embeds imperceptible patterns near task-relevant regions, preserving clean-data statistics while producing compact trigger distributions. We further apply target-aligned subset selection to strengthen signals at low injection rates. For persistence, we stabilize trigger embeddings via radius shrinkage and centroid alignment, and stabilize model parameters through curvature control and elastic weight consolidation, maintaining solutions within a low-curvature wide basin resistant to fine-tuning. We also provide the first theoretical analysis showing that, within a trust region, gradients from clean fine-tuning and backdoor objectives are co-directional, yielding a non-increasing upper bound on attack success degradation. Experiments demonstrate that with only 0.3% poisoning, BadCLIP++ achieves 99.99% attack success rate (ASR) in digital settings, surpassing baselines by 11.4 points. Across nineteen defenses, ASR remains above 99.90% with less than 0.8% drop in clean accuracy. The method further attains 65.03% success in physical attacks and shows robustness against watermark removal defenses.